基于激光雷达的语义面元地图的制作方法
本发明涉及一种自动驾驶地图制作的算法,具体是一种基于激光雷达的语义面元地图的制作方法。
背景技术:
1、根据《智能网联汽车技术路线图2.0》规划,2025年l2/l3级自动驾驶新车渗透率将达到50%。2021年,l3级自动驾驶汽车进入量产元年,自动驾驶地图作为l3及以上自动驾驶感知层核心技术之一,是无人驾驶系统中不可或缺的先验信息,是重定位、路径规划、导航决策等任务的前提条件。
2、在实际的制图过程中,由于城市和郊区环境会不断变化,这些变化发生在不同的时间尺度上,包括动态和短暂的对象(例如停放的汽车),季节性的变化(植被、雪、灰尘)和人类影响,例如建造。因此,制图的方法面对这些真实环境变化时的鲁棒性至关重要。
3、其次,由于自动驾驶系统必须根据车辆行驶过程中环境变化做出实时决策,低延迟性极其关键。大多数制图的算法仅仅只是对点云数据进行简单化的参数化处理,这会导致后续匹配地图过程中,将有着相同几何特征的东西与地图库中的不同物体匹配,这个问题在场景复杂且重复度高的城市环境中尤为明显,如何在此场景下提取细致化信息制图和后续地图匹配定位成为智能汽车亟待解决的难题。
技术实现思路
1、发明目的:针对现有技术中存在的不足,本发明提供了一种基于激光雷达的语义面元地图的制作方法,该方法通过语义面元地图的数据采集、制作语义面元地图各个层级、用面元表征点云地图,结合语义信息构成语义面元地图;三个步骤完成语义面元地图的构建,并且在制作语义面元地图各个层级时通过过滤不必要的噪声数据,将语义特征参数化,实现了该语义面元地图在运行过程中的鲁棒性更加优异;同时优化了运行方式,缩短程序运算时间,进一步降低延迟。
2、技术方案:一种基于激光雷达的语义面元地图的制作方法,包括:
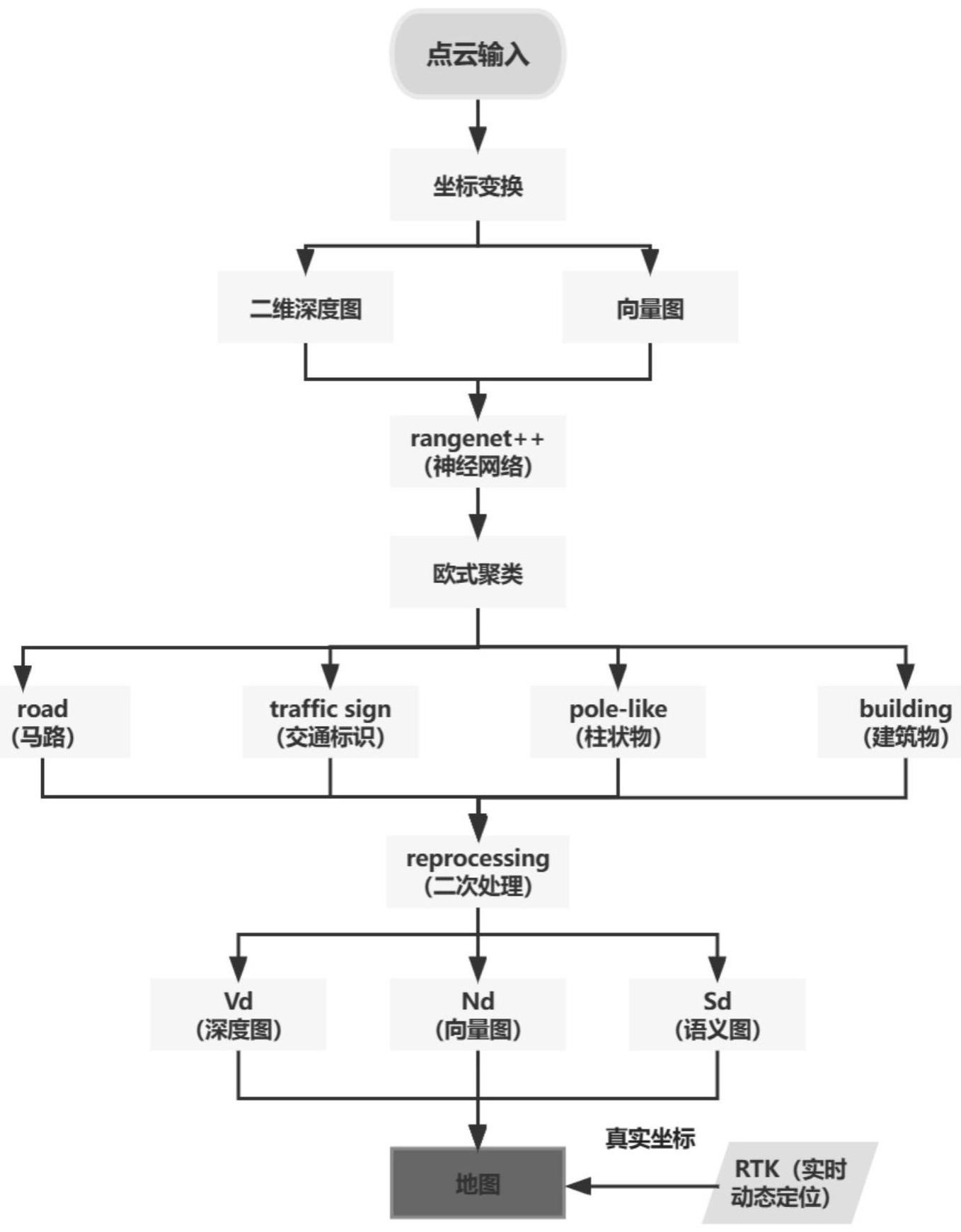
3、s1:语义面元地图的数据采集;
4、s1.1:在城市环境中利用激光雷达采取激光点云信息,点云数据内容包括城市环境中所扫描到物体的每个点的三维坐标和激光反射强度;
5、s1.2:利用rtk实时动态定位技术实时采取车辆的真实坐标信息;
6、s1.3:对采集到的激光点云信息进行预处理,整理获得的激光点云数据与各自对应的轨迹信息,完成原始数据集;
7、s2:按层级制作语义面元地图;
8、s2.1:将三维空间中的点投影到二维深度图上获取二维深度图vd;
9、s2.2:将深度图vd中的每一个点计算其法向量,所有的点的法向量构成向量图nd;
10、s2.3:使用深度学习的方法进行语义分割,采用激光点云语义分割的方法对深度图像进行2d图像完全卷积语义分割接着从原始点云中恢复所有点的从2d到3d的语义转换;
11、基于有效深度图像重建点云,并且基于knn最邻近分类法搜索,消除不希望的离散化何推理的伪影,在处理完点云数据后,对结果进行分类;
12、s2.4:对分类结果进行过滤,并且将过滤后的语义特征参数化;
13、s2.5:记录车辆在世界坐标系下的真实坐标值,以4×4的的矩阵表达车辆轨迹的真实坐标;
14、s3:用面元表征点云地图,结合语义信息构成语义面元地图;
15、s3.1:基于上述步骤获取的语义面元地图的基本元素,利用rtk实时动态定位技术实时采取车辆的真实坐标信息,得到每一帧的位姿后,接着把当前帧融合到地图中;
16、s3.2:对每一个点都计算出相应的面元,然后判别该面元是否与某个已有面元足够接近,若足够接近,则融合到已有面元中,否则,保留该面元作为新建面元。
17、优选项,所述s2.1具体为:首先把三维点投影到球面上,所有的点都用(θ,ψ,depth)为,然后把(θ,ψ)映射为二维坐标(u,v),将depth映射为像素值,便由此得到深度图vd;
18、将三维坐标转换为二维坐标具体包括:
19、旋转扫描式激光雷达,它的垂直视场角fov分为上下两个部分:fov_up和fov_down,以fov_up的数值为正数而fov_down数值为负数,所以fov=fov_up+(-fov_down);
20、球面坐标用3个参数来表示:距离,方位角(azimuth),天顶角(zenith)。通常使用的激光雷达点云中的每个由三维笛卡尔坐标表示的点实际上是从球面坐标系转换而来,激光雷达点云中的每个由三维笛卡尔坐标为的点坐标为(x,y,z),以x轴方向为前视图的方向把激光雷达旋转扫描一周得到的圆柱体展开后,得到一副图像:坐标原点在图像的中心,图像中像素的纵坐标由俯仰角投影得到,范围为[fov_down,fov_up],横坐标由偏转角投影得到,范围为[-π,π];
21、
22、pitch1=sin-1(z/r) (2)
23、yaw1=tan-1(y/x) (3)
24、公式(1)中r为激光雷达采集到的每个点到原点的距离,x,y,z是点的坐标,公式(2)中pitch1是俯仰角,z是z轴方向的点云坐标,公式(3)中yaw1是偏转角;
25、图像坐标系以左上角作为坐标原点,将上述得到的前视图做坐标转换,将坐标原点移到左上角:
26、pitch2=fov_up-pitch1 (4)
27、yaw2=yaw 1+π (5)
28、公式(4)中pitch2是转换后的俯仰角,fov_up是上部视场垂直分辨率,公式(5)yaw1是偏转角,yaw2是转换后的偏转角;
29、把三维点云投影为二维图像,这种降维操作必然会带来信息损失。为了尽可能减少投影带来的信息损失,我们需要选择合适大小的投影图像。对于一个80线的激光雷达,一般会设置投影图像的高为80,图像的宽度根据激光雷达的最大水平分辨率来设置,80线激光雷达的水平分辨率为0.35-0.4度,那么旋转一周一个激光器最多产生的点数为1028。在卷积神经网络中,一般会对输入特征图做多次2倍下采样,所以图像的宽度需要设置为2的次幂,这里可设置为1024。由于不同类型激光雷达的视场角、水平分辨率不同,投影图像的尺寸也会根据需要设置为不同的值,为了适应这些变化,将yaw2和pitch2进行规范化,规范化后,乘以投影图像的宽高,得到了这个点投影到深度图像的坐标,
30、pitch3=(fov_up-pitch2)/(fov_up-fov_down) (6)
31、yaw3=(yaw2+π)/2π (7)
32、
33、公式(6)中pitch3是规范和缩放后的俯仰角,fov_down是下部视场垂直分辨率,公式(7)yaw3是规范和缩放后的偏转角,公式(8)中u,v规范化和缩放后的坐标值,z是点云在z轴的坐标,r是激光扫描到的点与坐标原点的距离,row_scale是转换后深度图像的宽度,col_scale是深度图的长度。
34、优选项,所述s2.2具体为:计算随机一个点的法向量,就是该点到右侧相邻点的向量,与该点到上侧相邻点的向量,两者叉乘后的外积,计算公式如下:
35、nd(u,v)=[vd(u+1,v)-vd(u,v+1)]×[vd(u,v+1)-vd(u,v)] (9)
36、公式(9)中nd是指每个点的法向量,u,v为公式(8)中计算得到的二维坐标,vd是指深度图坐标,“×”是指叉乘。
37、优选项,所述s2.3具体为:使用深度学习的方法进行语义分割,使用神经网络rangenet++对深度图像进行2d图像完全卷积语义分割,接着从原始点云中恢复所有点的从2d到3d的语义转换,无论使用的深度图离散化如何,最后基于有效深度图像重建点云,并且基于knn搜索,消除不希望的离散化何推理的伪影。
38、处理完点云数据后,经过卷积神经网络进行识别分类,得到以下结果,包括:交通信号标识牌、柱状物体、马路、人行道、移动的车辆、停止的车辆、建筑物、和人。
39、所述的柱状物体包括:树干、电线杆、路灯柱子、消防栓、垃圾桶等固定安置在马路边缘的设施。
40、优选项,考虑到后续为了满足车辆重定位或者导航的需求,需要精炼语义地图,考虑到鲁棒性,不仅需要滤除移动物体,还要将容易发生变化的语义信息进行滤除,考虑到实时性,精度和存储,需要对特征对象进行选择。
41、所述s2.4具体为:将s2.3得出的分类结果进行过滤,将所述交通信号标识牌、柱状物体、马路和建筑物的点云数据保留;
42、所述将分类结果进行过滤具体是通过动态物体过滤方法在将这些类别进行二次分类,方法如下:
43、新激光点穿过旧激光点的位置,则旧激光点为动态点;当新激光与旧激光每一次重合,miss次数加一,设置阈值φ和ω,当累加的miss次数大于φ则标记为高动态物体,当累加的miss次数小于φ大于ω则标记为低动态物体,当累加的miss次数低于ω则标记为待处理物体;
44、通过上述分类方法滤除掉移动物体,包括:移动的车辆和人;
45、根据环境物体分类处理剩下的分类结果,根据物体动态程度将待处理物体分为半静态物体和静态物体,半静态物体包括停止的车辆,静态物体包括交通信号牌、柱状物体、马路和建筑物;
46、通过上述分类方法滤除掉半静态物体,保留交通信号标识牌、柱状物体、马路和建筑物;
47、参数化语义特征交通信号标识牌,由于交通信号的点云一般都是相对独立的,所以可以直接使用欧氏聚类来进行二次分割,通过ransac的方法进行提取;
48、参数化语义特征柱状物体,使用欧几里得聚类,拟合出一条3d直线,用一个杆上离原点距离最近的点坐标和方向向量表示。
49、具体算法如下:首先为输入点云数据集创建kd-tree(kd树)表示p,接着建立一个空的簇列表c和一个需要检查的点的队列q,然后对于每个点pi∈p,执行下面步骤:添加pi到当前队列q,对于每个点pi∈q做:在半径为r的圆柱体中搜索pik点邻居的集合,对于每个邻居点pik∈pik,检查该点是否已经被处理,如果没有,则将其添加到q,处理完所有点的队列q后,添加q到集群列表中c,并且重置q为空列表,当所有点pi∈p都被处理并且现在是点簇列表的一部分时,算法终止c。
50、真实坐标坐标信息,利用rtk工具实时动态测量车辆位置,记录车辆在世界坐标系下的真实坐标值,以4×4的的矩阵表达。
51、地图的形式有点云地图、栅格地图、面元地图。点云地图是主流地图,精度高,但是随着规模的增大,内存消耗严重,不利于计算和存储,栅格地图的优势在于在大规模场景中内存消耗比点云地图好,但是缺点在于精度差,最后便是面元地图,面元地图的优点在于用尽量少的数据表达尽可能大的场景,因此资源占用较低。考虑到存储问题,所以采用面元地图。
52、面元是面元地图的基本元素,所谓面元,是空间中有方向和大小的一个(椭)圆形平面,因此一个面元的基本构成要素为:面元中心点三维坐标;面元的法向量;面元大小(圆半径)。
53、根据构成面元的要求,结合各层级地图,我们提出地图更新的策略:首先对每一个点都计算出相应的面元,然后判别该面元是否与某个已有面元足够接近,若足够接近,则融合到已有面元中,否则,保留该面元作为新建面元。
54、优选项,所述s3.2具体为:对于当前帧任意一个点vs,记其对应的面元为s,该面元的空间坐标即点的坐标,法向量即点的法向量,面元的半径rs按如下公式计算:
55、
56、该式中,分子的||vs||代表点到激光雷达原点的距离,因此分子就是点到原点的距离再乘一个比例系数其中p为球面坐标系单位角度上的像素密度,是一个固定参数。分母中的clamp(*)是一个区间限定函数,限定了括号中第一项的取值范围为0.5到1.0之间;括号内的第一项表示的正是激光线方向与点法向量方向之夹角的余弦值,vs表示面元中点的坐标,ns表示对应点的法向量。
57、由于夹角必定位于0到90度之间,因此余弦值的取值范围是1-0。经过clamp(*)限定后,分母的实际取值范围为1.0到0.5。可以推断出,法向量与激光线越平行,夹角越小,分母越大,半径越小。这个公式中,分子相当于提供了一个初始半径,分母则根据法向量与激光线的夹角来调整这个半径。如果激光打到的地方与激光线越垂直,法向量与激光线夹角越小,分母越大,对应的面元半径越小;反之,面元半径越大。
58、判断该面元是否与某个已有面元足够接近,沿着激光线的方向打出一道光,在已有地图中打到的第一个面元,是在该光路上离坐标原点最近的面元s’,判断s和s’是否足够接近的标准是:
59、
60、||ns×ns,||<sinθm (12)
61、公式(11)中s’为沿着当前帧里面的点的视线延长打到的第一个面元,为该面元法向量的转置,vs,为该面元的中心坐标,vs为当前帧中面元中点的坐标,δm为距离阈值,在公式(12)中ns为当前帧中面元的法向量,ns,为沿着当前帧里面的点的视线延长打到的第一个面元的法向量,θm为角度阈值;
62、这个标准意味着,s和s’的位置需要足够接近,且法向量指向基本一致,如果判定为不够接近,则就把s’的概率累减一个值,并把新面元s插入到面元地图中。如果判定为足够接近则把s’的概率累加一个值,并用s的信息去更新s’,也即面元融合,更新公式如下:
63、
64、
65、
66、公式(13)中为更新的坐标位置,γ为阈值,vs为当前帧中的面元中心坐标,为沿着当前帧里面的点的视线延长打到的第一个面元的中心坐标,公式(14)中为更新法向量,γ为阈值,ns为当前帧中的法向量,为沿着当前帧里面的点的视线延长打到的第一个面元的法向量,公式(15)中为更新的半径,rs为当前帧中面元半径。
67、在处理完所有点云数据的信息后便完成了语义面元地图的制作。
68、有益效果:本发明构建了一种语义面元地图,地图保证每个节点包含二维深度、向量、语义以及车辆轨迹的真实坐标的多维度信息;考虑到算法的鲁棒性和后续定位的实时性,在深度学习方法的基础上额外使用传统特征提取法精炼语义信息,并且通过二次过滤的方式将噪音数据滤除,为后续车辆的定位导航或是决策提供精准的先验信息。使用面元形式表征点云,应用于室外大规模场景中,在保证精度的基础上大大减少了内存。
- 还没有人留言评论。精彩留言会获得点赞!