基于深度学习和MASK算子的阵列传感器自适应参数检测方法
本发明属于传感器智能检测,具体涉及基于深度学习和mask算子的阵列传感器自适应参数检测方法。
背景技术:
1、在已注入某一定量气体密封场景下,使用气体传感器检测环境中的气体浓度;气敏传感器基本上都存在预热步骤,气体传感器的气敏单元与气体通过充分化学或者物理反应,产生自身性质变化,通过不同的气敏元件特性设计检测电路,最终将物理或者化学信号转变为电信号。从以上反应特性可得出,气体传感器的测量周期缓慢,并且精度保障存在很大困难。
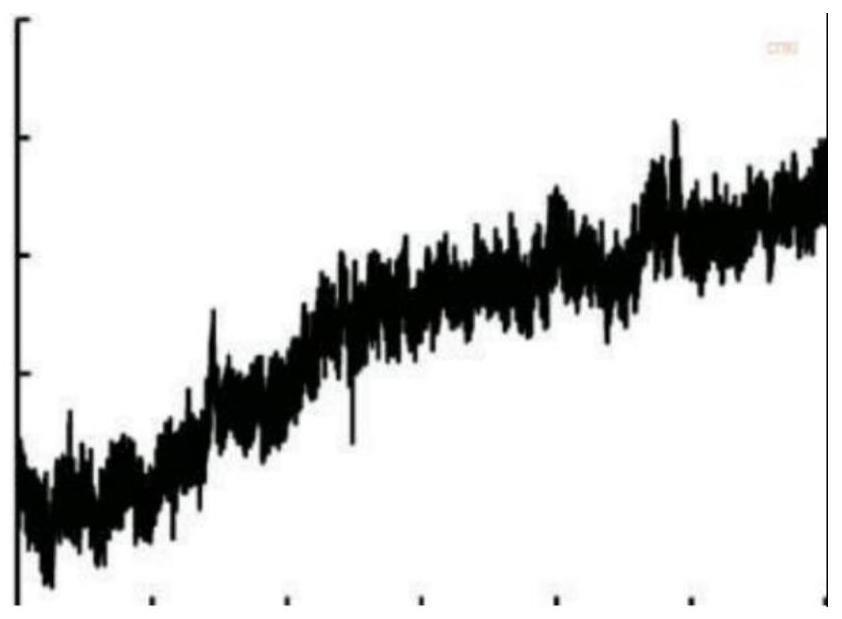
2、在传统的气体传感器测量方式是利用下位机收集气体传感器电路发出的电信号的幅值,将幅值时间序列中的平稳值或者峰值设置为当前环境气体浓度值。如图1所示,在碳纳米管气体传感器测量sof2和so2f2气体浓度引起的电导幅值变化幅度值可以看出,整个反应过程存在峰值不规则变化现象。该次实验过程持续85h,传统收集时序幅值峰值的做法只能通过无限延长实验周期的方式减少误差,该过程存在耗时、实验结果偏差等问题。
3、在传统测量方案上提出基于时序导数等数学特征测量幅值峰值方法,该方法是根据幅值-时序曲线分析一阶导数值估计实际气体浓度值。改变原有的幅值峰值估计方式,采用测量速度值进一步估计实际值。该方法一定程度上缩减实验周期,但丢弃时序曲线的完整性,对一类时序加速度值连续变化曲线无法做到准确估计。另外,在动态测量过程中,气体类浓度极易受到历史浓度状态的影响。在封闭状态已有气体的状态下注入测试气体,浓度的测量曲线的过程导数受到多方面影响,可能会出现同一浓度却过程导数不同或者过程导数类似但实际浓度不匹配的现象,所以该方法依旧存在一定问题与局限性。
4、传统的阵列传感器融合处理方案通常采用多个单一传感器构成阵列,通过将阵列中各个传感器采集到的信号进行融合处理,得到更为准确的测量结果。具体而言,融合处理方案通常包括采集数据、数据预处理、特征提取、特征融合、分类识别,这五大步骤。算法简单,测量结果相对可靠。但是其系统复杂度高,由于需要使用多个传感器并进行多步数据处理,导致系统硬件和软件都比较复杂;成本较高,多个传感器和处理器的成本较高,加上系统复杂度高,导致整个系统的成本较高;信号同步难度大,多个传感器需要同步工作,以避免数据错位或延迟,增加了工程设计难度和成本;稳定性难以保证,由于多个传感器和处理器都存在可能的故障点,系统的稳定性难以保证,也增加了维护成本。
技术实现思路
1、为了克服当前在气体传感器检测领域存在检测时间周期长、受历史影响大、数据处理复杂、检测精度低等问题,本发明提供了一种基于深度学习和mask算子的阵列传感器自适应参数检测方法,该检测方法通过mask算子,可自适应动态处理阵列传感器输入时间序列,并且能充分利用暂失能状态下传感器数据,结合深度神经网络算法进一步提高运算效率与测量精度。
2、本发明通过如下技术方案实现:
3、基于深度学习和mask算子的阵列传感器自适应参数检测方法,具体包括如下步骤:
4、步骤一:数据集准备及预处理;
5、收集待测气体经过同型号阵列传感器检测的已有数据,并对数据进行预处理,所述预处理包括清理、去噪及标准化,经预处理后得到带有时间维度的气体浓度序列数据;
6、步骤二:基于深度学习和mask算子的神经网络模型的构建;
7、所述神经网络模型包括数据处理模块、序列处理模块及融合处理模块;
8、数据处理模块中,对数据集采用mask算子运算实现数据增强,并使用十次十折交叉验证切分数据集;序列处理模块中,调节序列神经网络模型(transformer)中编码器(encoder)和解码器(decoder)模块超参数,参考均方误差(mse)、平均绝对误差(mae)指标使用网格搜索等优化函数评估出最优的超参数组合,以估算出各个传感器序列对应的气体浓度;融合处理模块中,采用卷积神经网络(cnn)自动的从序列处理后的数据中提取特征,从而实现对传感器的检测和诊断;
9、步骤三:基于深度学习和mask算子的神经网络模型的训练;
10、步骤四:采用上述训练好的神经网络模型检测出实际浓度值与阵列传感器件状态。
11、进一步地,步骤一中,数据包括阵列传感器检测的浓度及时间值的序列值,将传感器中包括浓度和时间的序列值转换为用于transformer模型的格式,从而进行模型训练任务,具体包括如下内容:
12、a1、将时间序列离散化:将连续的时间序列数据离散化成固定为10min时间间隔的数据;
13、a 2、序列标准化:对离散化后的时间序列进行均值归一化处理,使其具有相似的统计特征;
14、a3、构建输入序列:将均值归一化后的时间序列数据转化为输入序列,即将一段固定时间长度的数据作为一个序列输入到transformer神经网络模型中;
15、a4、批量化和填充:对于输入序列长度不足的情况,进行填充操作来保证输入序列长度的一致性。
16、进一步地,步骤二中,数据处理模块中,mask算子运算可扩充数据集,增加样本数量;具体地,根据传感器阵列形式设计mask算子,采用生成的mask算子掩膜对步骤一中预处理得到后的序列数据进行遮盖,得到一系列被遮盖的新样本序列数据;最后,将生成的新样本序列数据作为的数据集,用于模型训练和评估。
17、进一步地,步骤二中,采用十次十折交叉验证方法,对数据集进行切分并进行模型训练和评估,具体步骤如下:
18、b1、将原始数据集分为10个互不重叠的子集;
19、b2、对于每个子集,依次将该子集作为测试集,其余9个子集作为训练集,进行模型训练和评估;
20、b3、重复步骤b2共10次,直到每个子集都被用作为一次测试集;
21、b4、对于每次划分,记录模型在测试集上的性能指标;
22、b5、将所有10次的测试集性能指标求平均值,得到模型的最终性能指标。
23、进一步地,步骤二中,所述序列处理模块中,采用transformer神经网络的encoder-decoder模型及嵌入层对数据进行时序处理;其中,所述嵌入层用于将传感器采集到的数据转换为神经网络可以处理的向量形式;所述encoder模块用于将输入序列转换为一组隐藏表示;所述decoder模块用于根据encoder模块提供的隐藏表示和之前生成的输出,生成当前时间步的输出;
24、所述嵌入层由位置编码器及输入嵌入组成,位置编码器用于为每个时间点的输入数据添加位置信息,以便于模型学习时间序列的顺序;输入嵌入用于将每个时间点的输入数据转换为固定维度的向量表示,以便于后续的注意力机制、编码器和解码器进行处理;
25、所述encoder模块包括:
26、多头注意力机制multi-head attention,用于对输入序列进行加权汇聚,以便encoder模块能够更好地利用输入序列的信息;
27、前馈神经网络position-wise feed-forward network:用于对上述多头注意力机制的输出进行加权汇聚,以便生成一组隐藏表示。
28、所述decoder模块包括:
29、自注意力机制masked multi-head attention,用于计算当前时间步的输出与之前生成的输出之间的关系,以及将encoder模块提供的隐藏表示与当前时间步的输出进行交互;
30、多头注意力机制multi-head attention,用于对encoder模块提供的隐藏表示进行加权汇聚,以便decoder模块能够更好地利用输入序列的信息;
31、前馈神经网络position-wise feed-forward network,用于对上述两个注意力机制的输出进行加权汇聚,以便生成当前时间步的输出;
32、所述encoder模块与decoder模块的各组件之间均设置有layer normalization模块,用于更好地进行信号传输和防止模型训练时的梯度消失问题。
33、进一步地,步骤二序列处理模块,构建模型具体包括如下内容:
34、c1:设定超参数范围;
35、首先,确定输入序列长度,根据数据的采样频率和应用场景,选择从0到24个小时的数据点作为一个输入序列长度,全面的记录环境气体浓度变化值;然后,确定批次大小及隐藏层数,设置批次为32、64或128;确定隐藏层数为5-6层;最后,确定头数为6-8;
36、c2:网格搜索;
37、采用网格搜索方法在超参数范围内搜索最优的超参数组合;
38、c3:随机搜索;
39、采用随机搜索方法在超参数范围内随机搜索最优的超参数组合;
40、c4:贝叶斯优化;
41、采用贝叶斯优化方法在超参数范围内寻找最优的超参数组合;
42、c5:评估模型性能;
43、采用通过上述方法各自得到的最优超参数组合分别训练transformer神经网络模型,并在测试集上使用均方误差(mse)、平均绝对误差(mae)评估出最优的超参数组合,并使用最优参数模型对应的mse、mae表征模型性能。
44、进一步地,步骤二中,融合处理模块中,采用卷积神经网络(cnn)对序列处理模块估算出的各个传感器序列对应的气体浓度进行特征提取,从而实现对损坏传感器的检测和诊断,并输出气体浓度值与阵列传感器件状态。
45、进一步的,步骤二中,所述融合处理模块的实现包括以下步骤:
46、d1:将传感器阵列数据输入到cnn网络中;
47、在cnn网络的输入层,将传感器阵列数据按照传感器阵列位置进行排列,将传感器阵列中每个传感器的读数作为输入的一个通道;
48、d2:利用多个卷积层和池化层对输入数据进行特征提取;
49、在卷积层中,通过卷积运算对输入数据进行滤波操作,提取数据中的空间特征;在池化层中,对卷积输出进行下采样操作,减小特征图的尺寸,并保留关键特征信息;
50、d3:利用全连接层对特征进行分类;
51、在全连接层中,将特征向量展开为一维向量,并通过一系列的全连接操作,将特征映射到输出空间中,实现对传感器阵列数据的分类;
52、d4:根据分类的结果,输出气体浓度值与阵列传感器件状态;
53、具体地,根据分类结果判断气体浓度值数据属于哪一类别,从而得到对应的阵列传感器件状态。
54、进一步地,步骤三具体如下:
55、选取目标气体整列传感器的已有数据集,该数据集的参数值与其对应的时刻值作为神经网络的分析特征量,即qi=[ti,vi]t,qi表示在某一时刻下位机发送的数据参数,ti、vi分别是其对应的气体的浓度及时间值;将训练集通过embedding方式导入神经网络,经过一系列穿插、归一化、注意力机制、mask算子掩膜遮盖、融合算法训练处理,得到气体阵列传感器数据序列与实际气体浓度和阵列传感器件状态的参数关系,即模型训练完成。
56、与现有技术相比,本发明的优点如下:
57、本发明通过在输入数据中增加权重模板mask,通过mask可以对任意数量的传感器响应数据进行降权重使用或者屏蔽,从而使得训练所得模型在部分器件出现数值偏差或异常的时候仍然能基于正常工作的器件给出尽可能准确的预测结果,从而提升整个检测系统的鲁棒性及系统的稳定性和可靠性;
58、本发明充分利用传感器阵列上的器件冗余设计实现器件间工作状态的相互验证和对测试数据误差的抑制,在传感器工作状态诊断及准确性上有所提升;
59、本发明通过训练数据集纳入mask算子训练得到的模型,更好的对测试参数变化评估故障源解算进行细分,一方面提高故障源分析的准确性,一方面将可疑参数按照权重纳入运算,提高目标气体浓度检测的准确性。
- 还没有人留言评论。精彩留言会获得点赞!