二次模态重构的泄漏积分储备池网络的供水量预测方法
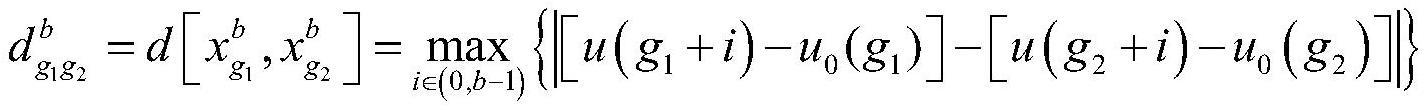
本发明涉及供水量预测领域,特别是涉及一种二次模态重构的泄漏积分储备池网络的供水量预测方法。
背景技术:
1、近年来,由于城市化进程的不断推进和社会经济的高速发展,城市用水量幅度大大增加,城市供水的复杂度也大大增加,因此满足城市的用水量需求是供水系统的当务之急,这对供水系统的优化提出了挑战。预测城市用水需求量是优化城市供水系统规划的基础,使水务公司能够在节约能源的同时,做出水资源优化调度的决策,从而提高水资源利用率,同时满足客户用水需求。
2、由于历史原因、技术水平等多方面因素,导致当前多数中小城市仍旧根据传统经验来进行供水调度决策,容易导致供水过度或供水不足的问题,因此做到城市供水量精确预测是水务公司面临的关键问题之一。
3、因此本领域技术人员致力于开发一种二次模态重构的泄漏积分储备池网络的供水量预测方法城市供水量预测方法,以求精确预测城市用水需求量。
技术实现思路
1、有鉴于现有技术的上述缺陷,本发明所要解决的技术问题是提供一种二次模态重构的泄漏积分储备池网络的供水量预测方法城市供水量预测方法,以求精确预测城市用水需求量。
2、为实现上述目的,本发明提供了一种二次模态重构的泄漏积分储备池网络的供水量预测方法,包括以下步骤:
3、1)数据采集,采集目标区域中所有用户历史供水量数据,形成供水量时间序列x(t);
4、2)利用时间序列分解ceemdan方法,对供水量时间序列x(t)进行分解,将其分解为一系列拥有不同特征尺度的模态分量其中,k=1,2,…;
5、3)对模态分量进行重构,根据熵值将不同的模态分量进行合并,将不同模态中所表现出来的共同特性进行融合得到高频子序列t1、t2、…、to,中频子序列m和低频子序列l;
6、4)分别将步骤3)重构得到的高频子序列t1、t2、…、to,中频子序列m,低频子序列l作为输入量,输入到一个基于注意力机制、用入侵杂草优化算法优化的、含有泄漏系数的回声状态网络中,得到高频子序列t1、t2、…、to的预测值y1、y2、…、yo,中频子序列m的预测值ym以及低频子序列l的预测值yl;
7、5)将每个子序列得到的预测结果进行集成,得到最终的预测结果。
8、较佳的,所述步骤1)中供水量时间序列x(t)至少为连续一年的日供水量数据。
9、较佳的,所述步骤2)中,供水量时间序列分解ceemdan方法包括以下步骤:
10、21)利用经验模态分解方法即emd算法对信号x(t)+ε0vi(t)进行i次分解,其中i的取值为50~100,通过均值计算获得第一个模态分量:
11、
12、其中ε0为幅值,vi(t)代表i(i=1,2,…,i)次实验中添加的具有标准正态分布的白噪声序列,imf1i(t)为第i次实验得到的第一个emd分量;
13、22)将从原始时间序列x(t)中减去,得到第1个余量信号利用emd对信号r1(t)+ε1e1[vi(t)]进行i次分解,通过均值计算获得第二个模态分量:
14、
15、其中e1{r1(t)+ε1e1[vi(t)]}代表通过emd算法提取的第一个模态分量;
16、23)将从第1个余量信号r1(t)中减去,得到第2个余量信号利用emd对信号r2(t)+ε2e2[vi(t)]进行i次分解,通过均值计算获得第三个模态分量:
17、
18、24)将从第k-1(k=3,4,…)个余量信号rk-1(t)中减去,得到第k个余量信号利用emd对信号rk(t)+εkek[vi(t)]进行i次分解,通过均值计算获得第k+1个模态分量:
19、
20、25)判断余量信号的极值点个数是否小于等于两个,若是,停止;若否,进入步骤24);
21、算法终止时,得到k+1个模态分量和1个余量信号,令k=k+1+1,故最终原始数据可以通过ceemdan算法被分解为k个模态分量:
22、
23、其中前k-1个为第k个为余量信号
24、较佳的,所述经验模态分解方法包括以下步骤:
25、211)设原始时间序列为x'(t),确定x'(t)所有局部极值点,用三次样条曲线连接所有局部极大值点形成上包络线,连接所有局部极小值点形成下包络线,计算上下包络线的平均值m1,求出原始数据与m1之间的差值h1=x'(t)-m1,判断h1是否满足imf的条件;所述imf的条件为极值点和过零点的数目相等或至多相差1且m1=0;若是,则进入步骤212),若否,则进入步骤213);
26、212)则h1为x'(t)的第1个imf分量,记为c1;
27、213)把h1作为原始数据,进入步骤211)e(e=1,2,…)次,直到h1e=h1(e-1)-m1e满足imf的条件:极值点和过零点的数目相等或至多相差1;m1=0。其中h1(e-1)为第e次重复过程的原始数据,m1e为第e次重复过程上下包络线的平均值,记c1=h1e,则c1为信号x'(t)的第1个imf分量;
28、214)将c1从原始时间序列x'(t)中减去,得到第1个余量信号r1=x'(t)-c1,将r1作为原始数据进入步骤211),得到x'(t)的第2个imf分量c2;
29、215)将c2从第1个余量信号r1中减去,得到第2个余量信号r2=r1-c2,将r2作为原始数据进入步骤211),得到x'(t)的第3个imf分量c3;
30、216)将cn从第n-1(n=3,4,…)个余量信号rn-1中减去,得到第n个余量信号rn=rn-1-cn,将rn作为原始数据进入步骤211),得到x'(t)的第n+1个imf分量cn+1;
31、217)判断余量信号是否是单调函数,不能再提取出满足条件的imf:极值点和过零点的数目相等或至多相差1;m1=0;若是,停止;若否,进入步骤216);算法终止时,得到n+1个emd模态分量和1个余量信号。
32、较佳的,所述步骤3)中包括步骤31)一次重构和步骤32)二次重构。
33、较佳的,所述步骤31)一次重构包括:
34、311)将步骤2)得到的模态分量作为输入向量,记为u(g),计算各分量的模糊熵;将u(g)={u(1),u(2),…,u(k)}按照顺序构造一组b(b一般选择2~5)维向量即
35、
36、g=1,2,…,k-b+1
37、其中u0(g)为均值,即
38、
39、312)取向量组中的两个不同向量和其中g1,g2=1,2,…,k-b+1且l≠j,计算向量和两者元素之间距离的最大值,即
40、
41、313)使用模糊函数来计算和之间的相似度
42、
43、其中a为梯度,s1为相似容限;
44、314)对除自身外所有隶属度求平均
45、
46、315)构建b+1维向量,即用b+1替换公式中的b,得
47、
48、316)定义模糊熵为
49、
50、因k为有限数,故上式可表达成:
51、fuzzyen(b,a,s1,k)=lnφb(a,s1)-lnφb+1(a,s1);
52、317)根据以上各步骤,计算得到各模态分量的模糊熵值,并按照模糊熵值的数量级进行区间划分,熵值大于等于0.5的则为高频分量t1、t2、…、tj,熵值在区间[0.2,0.5)之间则合并为中频子序列m,熵值小于0.2则合并为低频子序列l;以此得到高频分量t1、t2、…、tj,中频子序列m和低频子序列l。
53、较佳的,所述步骤32)二次重构包括:
54、321)将一次重构得到的高频分量t1、t2、…、tj作为输入向量,记为v(l),计算其样本熵;将v(l)={v(1),v(2),…,v(j)}按照顺序构造一组c(c一般选择1或2,优先选择2)维向量ylc,即
55、ylc={v(l),v(l+1),…,v(l+c-1)},
56、l=1,2,…,j-c+1
57、322)取向量组ylc(l=1,2,…,j-c+1)中的两个不同向量和其中l1,l2=1,2,…,j-c+1且l1≠l2,计算向量和两者元素之间距离的最大值,即
58、
59、323)给定相似容限s2(s2>0),对于每个l值,计算与除自身外的其他向量(p=1,2,…,j-c+1且p≠l)间的距离统计的个数,然后计算其与距离总数j-c的比值,记为即
60、
61、324)计算的平均值bc(s2),即
62、
63、325)针对c+1维,即用c+1替换公式中的c,得bc+1(s2)
64、
65、326)计算样本熵
66、
67、因j为有限数,故上式可表达成
68、
69、327)根据以上各步骤,计算得到各高频分量t1、t2、…、tj的样本熵值,根据样本熵的值,按照熵值数量级进行区间划分,合并得到得到高频子序列t1、t2、…、to(o<j)。
70、较佳的,所述步骤4)的包括:
71、41)利用注意力机制的步骤,将步骤3)重构得到的高频子序列t1、t2、…、to,中频子序列m,低频子序列l分别作为输入量输入量通过注意力机制的响应分别是向量它与输入量的维度相同:
72、
73、
74、
75、
76、
77、
78、其中是激活函数,具体采用sigmoid函数作为激活函数,即win是输入层权值矩阵,w是储备池权值矩阵,通过注意力机制调整后的liesn输入量分别为:
79、
80、
81、
82、
83、
84、
85、其中⊙指元素级乘法;
86、42)利用入侵杂草优化算法liesn的步骤如下:
87、421)对种群进行初始化,liesn需要优化的5个参数为谱半径sr、神经元个数n、输入单元尺度is、连接稀疏度sd以及嵌入维数q;初始化定义5个参数的解空间范围;
88、422)计算每个种子的适应度函数,适应度函数为:
89、
90、其中len为供水量时间序列的长度,y(w)和分别代表w时刻的实际供水量数据和预测供水量数据,h为输出向量的长度;
91、423)种子成长为杂草,杂草产生新的种子,其产生的新种子数目snum为:
92、
93、其中floor()为向下取整函数,fmax、fmin分别为当前种群中的最大适应度值和最小适应度值,smax、smin分别为单个杂草能产生的最大种子数和最小种子数,子代以正态分布扩散到父代周围,计算新的适应度值;
94、424)判断种群规模是否达到限定的最大值,若是将所有杂草按适应度值从高到低排序,保留排在前5位的个体,当达到最大进化代数或者|fmax-fmin|<10-6时,优化完成,输出这5个参数的最优值给liesn网络;若否,再次进入步骤423)、424);
95、43)基于注意力机制、用入侵杂草优化算法优化的含有泄漏系数的回声状态网络am-iwo-liesn实现预测的步骤,具体包括以下步骤:
96、设在t时刻的网络通过注意力机制的输入层向量分别为:
97、
98、
99、储备池向量为h(t)=[h1(t),…,hn(t)]t,输出层向量为
100、
101、
102、则liesn网络的储备池在t+1时刻的状态方程分别为:
103、
104、
105、
106、
107、
108、
109、其中,c为时间常数,α为泄漏率,ρ为谱半径,f(·)表示储备池的激活函数;利用liesn对t+1时刻的目标值的预测分别可由下式得到:
110、
111、
112、
113、
114、
115、
116、其中,fout(·)表示输出层的激活函数。通过该公式,可以得到重构得到的各子序列的预测值。
117、较佳的,所述步骤5)中的集成是指将步骤4)得到的高频子序列t1、t2、…、to的预测值y1、y2、…、yo,中频子序列m的预测值ym以及低频子序列l的预测值yl加总,得到最终的预测值。
118、本发明的有益效果是:本发明采用二次模态重构的泄漏积分储备池网络的预测方式来解决城市日供水量预测精度低的缺点,能够准确预测出城市日供水量,可以为城市供水的调度决策优化提供依据与技术支持。
- 还没有人留言评论。精彩留言会获得点赞!