一种基于增量学习的金融合同条款提取方法和系统
本发明涉及计算机自然语言处理,特别涉及一种基于增量学习的金融合同条款提取方法和系统。
背景技术:
1、风险控制(风控)是金融行业不可或缺的一部分,而风控工作通过审核金融合同找到其中可能包含风险的条款,并输入风控系统中进行管理和控制。随着业务量的增加,人工审核一份一百多页的合同费时费力,因此,利用智能模型系统进行自动识别时非常必要的,同时也是一种趋势。在搭建深度学习模型进行自动识别过程中,常常会遇到的问题包括:训练数据无法一步到位、多次标注的训练数据存在歧义、甚至出现新类别需要识别的情况,因此,构建一个自动处理金融合同提取风险条款的模型,并且能够不断学习处理新的条款是解决这些问题的方案。
2、从现有技术来看,风险子句提取工作主要使用分类模型。已有的方法有:浅层机器学习方法,包括人工神经网络、支持向量机、贝叶斯网络等;以及深度学习方法如长短期记忆网络(long short-term memory,lstm)、卷积神经网络(convolutional neuralnetworks,cnn)、bert等,但是这种分类模型只能判断单句的类别,适合于对边界没有较强要求或是半结构化数据中的提取任务。
3、在金融合同条款提取任务中,存在一个子句有多个条款和多个子句属于一个条款的情况。因此不仅要判断出子句的类别,同样需要判断条款的边界;相近的研究主要从文本分割、主题分割等方面出发,通过对更大篇幅的文本输入建模,进而提取出其中子句级的目标。文本分割的研究大致分为无监督方法和神经网络方法,无监督方法例如早期的词频等文本信息计算、以及贝叶斯方法等,无监督方法的计算成本很高,并且分割的准确性也不好。有监督的神经网络方法有多层级的双向lstm网络,多层级的bert模型等序列标记算法,能够根据上下文信息进行每个子句的类别判断,找到位于分割点的子句,进而将文段分割。就提取风险条款而言,大模型在训练与预测计算量大、耗时长,小模型准确率低,学习到深层次的语义信息、提高模型准确度仍然是一个重大难题。
4、在实际应用中,金融行业的专业性和特殊性,使得不同批次的数据标注可能存在歧义,并且根据业务需要可能会有新的类别加入。类增量学习可以完成这样的应用场景。而增量学习所带来的一个最主要的问题就是灾难性遗忘问题,即神经网络在经过新数据训练后,会几乎忘记之前学过的任务。面对这一问题,现有文献主要有3种解决方案。其中有基于样本的方法,其主要包括回放,即直接使用或间接使用之前的训练样本进行再训练,这种方法对于某些无法再次获得数据的应用场景难以实现;
5、以及基于模型参数的方法,即对模型的参数作出划分或正则化限制,使得模型对于不同的任务使用不同的参数,难以得到一个统一的模型;最后是基于知识蒸馏的方法,知识蒸馏常被运用在自然语言处理中,将大模型蒸馏得到小模型,主要方法是搭建小模型来拟合大模型输出的软标签,进而拟合大模型的输出效果。但是对于序列标注任务,crf(conditional random field)层输出的所有可能路径数量庞大,作为软标签难以学习。因此在序列标注任务中知识蒸馏的增量学习仍然是一个重大难题。
技术实现思路
1、本发明针对现有技术的缺陷,提供了一种基于增量学习的金融合同条款提取方法和系统。综合利用cnn的特征提取能力和双向lstm的时序预测,利用增量学习对旧模型进行知识蒸馏,保留旧知识并学习新知识。首先,利用cnn对数据进行下采样降低数据的维度和复杂程度,提高模型整体的泛化和学习能力,随后,将降维后的数据输入双向lstm网络,进一步挖掘段落中不同子句提供的信息特征。该模型有效利用cnn的速度和轻量特性与双向lstm网络的顺序敏感性,允许在训练时查看更多的数据量,提高预测准确度。
2、为了实现以上发明目的,本发明采取的技术方案如下:
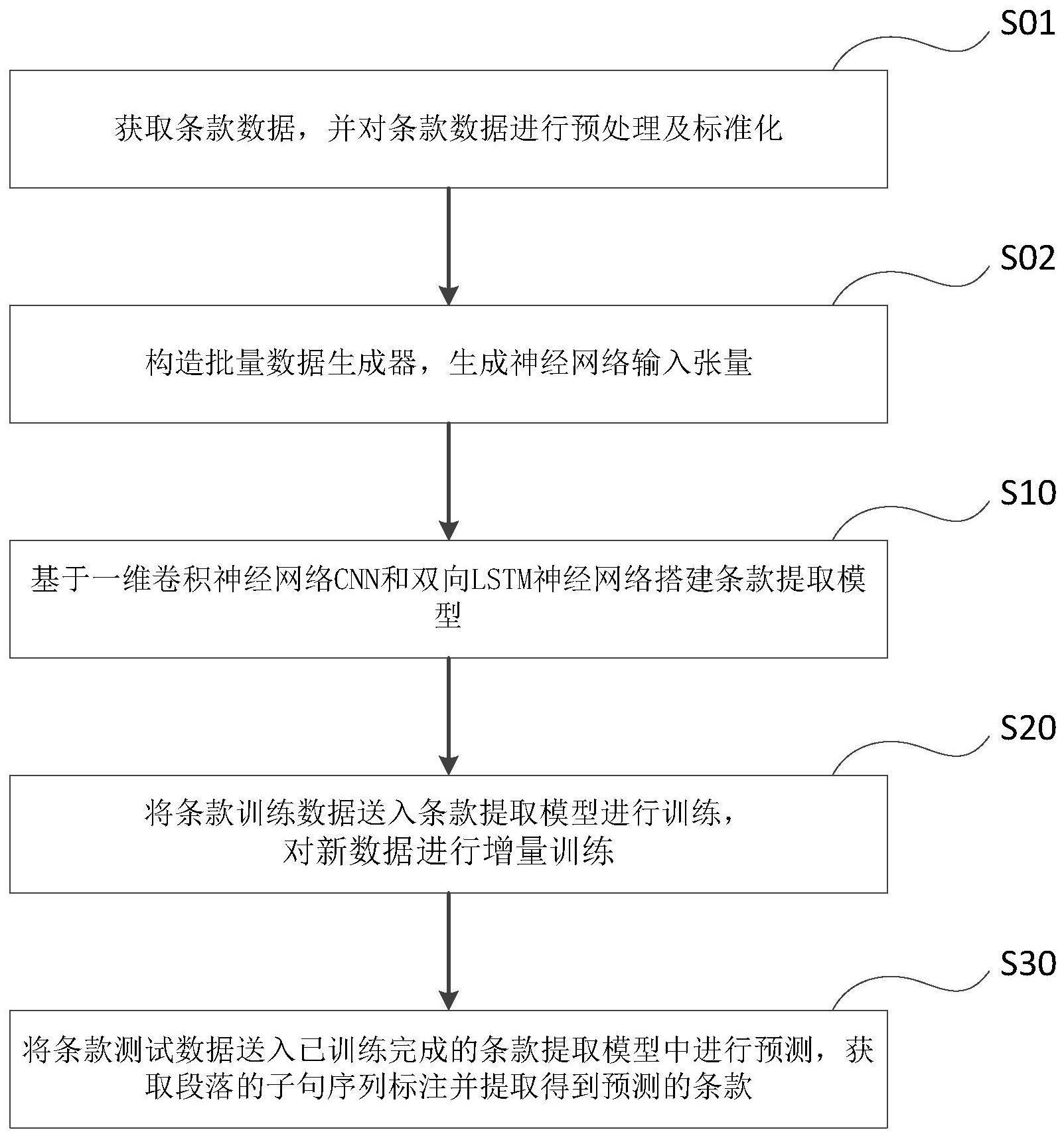
3、一种基于增量学习的金融合同条款提取方法,包括以下步骤:
4、s1、获取条款数据,并对条款数据进行预处理及标准化;
5、s2、构造批量数据生成器,生成神经网络输入张量;
6、s3、基于一维cnn和双向lstm网络搭建条款提取模型;
7、s4、将条款训练数据输入条款提取模型进行训练,对新数据进行增量训练;
8、s5、将条款测试数据送入已训练完成的条款提取模型中进行预测,获取段落的序列标注并提取得到预测的条款。
9、进一步地,s1中进行预处理及标准化具体为:
10、条款数据,以一个金融合同中的自然段落为一条数据。一个段落中可能包含一条或多条条款、也可能不包含条款。
11、将条款数据划分为训练集、验证集、测试集。
12、通过标点符号,将条款数据的段落拆分成子句序列;并通过构造好的词典,将子句中每个字词转换成词典中对应的数字编号,再根据设定好的最大子句长度对每个子句数字编号向量进行补齐或切除。后将一个段落的子句数字编号向量拼接,根据设定好的最大子句数量对每个段落进行补齐或切除。
13、进一步地,s2中所述的批量数据生成器,其指定预测输入包含段落向量、子句序列标注及每个批量包含样本数,其返回是一个元组,即多变量输入数据的一个批量,对应的目标子句序列数组。
14、进一步地,所述s3中条款提取模型具体为:
15、输入的段落文本数据等长拆分成若干个子句,并通过embedding层进行词嵌入。所述一维cnn的输入端连接单个子句的词向量,输出得到子句的嵌入向量。将段落中的所有子句嵌入向量拼接后输入双向lstm神经网络,双向lstm神经网络的输出端接入crf层,生成段落的子句序列标注;
16、优选地,所述的获取子句嵌入向量,具体为:使用卷积层进行子句特征学习,使用全局最大池化进行子采样,将卷积层输出的嵌入向量最后一维压缩。
17、优选地,所述的crf层作为最后一层进一步优化序列标注结果,损失函数由其真实路径分数和所有路径分数构成,训练中在每个批量上根据损失值进行反向传播运算,并选择f1分数作为模型的误差评价指标,衡量预测的好坏。
18、进一步地,所述s4具体为:
19、embedding层分别对每个词进行嵌入成词向量,一维cnn对每个子句的词向量进行局部特征学习并降维,依次经过卷积和池化操作,形成子句嵌入向量;将子句嵌入向量序列输入双向lstm神经网络,双向lstm神经网络从正序和逆序学习子句向量序列,输出的特征序列向量输入crf中计算得到最佳的序列标注结果;
20、对于新标记好的数据,首先使用原数据训练好的模型对其进行估计,得到crf前若干条得分最高的序列标注结果及其分数作为软标签,再使用新数据打好的标签修正软标签,得到修正过的软标签;将原数据训练好的模型参数载入新的模型,再使用新数据及其修正过的软标签对模型进行再训练。
21、所述新标记好的数据为:足量的、包含旧类别和新类别的条款训练数据,使模型能够同时学习到新旧知识。
22、优选地,所述的双向lstm神经网络,包括前向和后向lstm神经网络,分别从文本正序和文本逆序处理输入子句嵌入向量序列,lstm神经网络在大量训练中不断调整自身参数,使其从一维cnn提取的数据中学习数据间的上下文依赖关系。
23、优选地,所述s4中训练,在模型的层与层之间广泛引入dropout技术以预防过拟合。
24、本发明还公开了一种基于增量学习的金融合同条款提取系统,该系统能够用于实施上述的金融合同条款提取方法,具体的,包括:数据获取模块、数据生成器模块、条款提取模块;
25、数据获取模块:获取条款数据,并对条款数据进行预处理及标准化;
26、数据生成器模块:生成神经网络输入张量;
27、条款提取模块:对条款训练数据输入条款提取模型进行训练,对新数据进行增量训练;将条款测试数据送入已训练完成的条款提取模型中进行预测,获取段落的序列标注并提取得到预测的条款。
28、本发明还公开了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述金融合同条款提取方法。
29、与现有技术相比,本发明的优点在于:
30、(1)本发明的条款提取技术能更好的学习上下文信息,有效利用卷积神经网络的速度和轻量特性与循环神经网络的顺序敏感性,同等条件下允许查看更多数据,预测准确度高于传统预测方法;
31、(2)使用双向lstm从正序和逆序处理子句向量序列,能捕捉到可能被单向lstm忽略掉的模式,提高子句向量序列的特征学习能力,从而提升预测准确度。
32、(3)本发明的增量学习方法能更好地保留旧知识,缓解学习新数据时带来的灾难性遗忘,同时保证新类别的识别能力。
- 还没有人留言评论。精彩留言会获得点赞!