一种基于互补关系挖掘的不平衡增量学习方法
本发明属于增量学习,具体涉及一种基于互补关系挖掘的不平衡增量学习方法。
背景技术:
1、随着科技的发展,自动驾驶技术越来越成熟,越来越多的汽车都配备有辅助的自动驾驶功能,这种配备有自动驾驶功能的汽车在出厂之前会预设一些路况场景,例如,等待红绿灯的场景和正常道路行驶的场景等,方便汽车识别实现自动避障和驾驶。但是,汽车在真实上路之后会面临各种各样的见过或者没见过的路况。因此,需要在不忘记之前预设场景的基础上学习适应新的路况。
2、增量学习旨在通过平衡模型的可塑性和稳定性来缓解对旧知识的遗忘,其中旧知识不会被遗忘(变化的稳定性),同时学习新的输入数据(适应性可塑性),目前,大多的增量学习方法都是假设数据分布在不同任务中是平衡的。然而,真实世界的数据往往是不平衡的,通常以长尾分布的形式出现。
3、新的路况场景也有长尾分布特性,比如大部分遇到的是堵车,等红绿灯,正常行驶的场景,但也会遇到一些少的情况,比如大风,阳光眩晕,打伞的人,人在车后搬箱子、树倒在路中央等其他路况场景。对于分布不平衡的数据,采用现有的增量学习方法可能会导致性能显著下降,特别是对于具有少量样本的类,可能会遇到更严重的遗忘,另外,现有的增量学习方法知识蒸馏方法仅使用距离损失来缩小新旧模型输出特征之间的差距,而没有考虑它们之间的充分交互,导致跨任务的信息蒸馏效率较低,对于自动驾驶领域,这些问题会严重影响自动驾驶应用的安全性问题。
技术实现思路
1、为了解决现有技术中存在的上述问题,本发明提供了一种基于互补关系挖掘的不平衡增量学习方法。本发明要解决的技术问题通过以下技术方案实现:
2、本发明提供了一种基于互补关系挖掘的不平衡增量学习方法,包括:
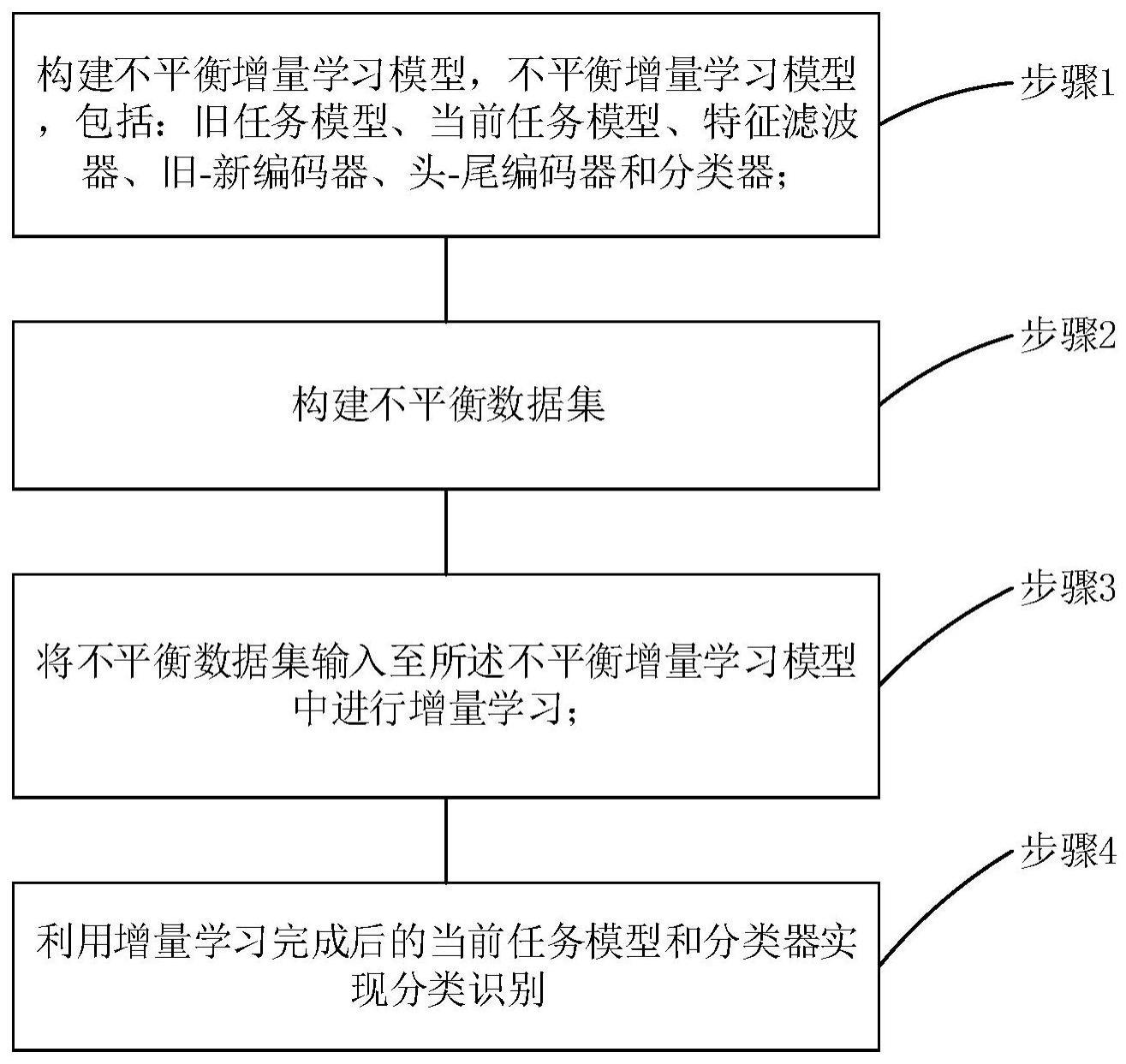
3、步骤1:构建不平衡增量学习模型,所述不平衡增量学习模型,包括:旧任务模型、当前任务模型、特征滤波器、旧-新编码器、头-尾编码器和分类器;其中,
4、所述旧任务模型、所述特征滤波器和所述旧-新编码器依次级联;
5、所述当前任务模型的输出端分别连接所述旧-新编码器的输入端和所述头-尾编码器的输入端;
6、所述旧-新编码器的输出端和所述头-尾编码器的输出端均连接所述分类器的输入端;
7、步骤2:构建不平衡数据集;
8、步骤3:将所述不平衡数据集输入至所述不平衡增量学习模型中进行增量学习;其中,
9、在增量学习过程中,利用知识蒸馏将所述旧任务模型包含的知识提取至所述当前任务模型中;利用头-尾编码器挖掘不平衡数据集中多数类和少数类数据之间的关系,利用旧-新编码器挖掘旧任务模型和当前任务模型生成的特征之间的关系;
10、步骤4:利用增量学习完成后的当前任务模型和分类器实现分类识别。
11、在本发明的一个实施例中,所述旧任务模型和所述当前任务模型均为resnet18网络。
12、在本发明的一个实施例中,所述旧-新编码器和所述头-尾编码器的结构相同,均包括第一归一化层、自注意力层、第二归一化层和多层感知机,其中,
13、所述第一归一化层、所述自注意力层、所述第二归一化层和所述多层感知机依次级联;
14、所述第一归一化层的输入与所述自注意力层的输出融合后作为所述第二归一化层的输入;
15、所述第二归一化层的输入与所述多层感知机的输出融合后作为编码器的输出。
16、在本发明的一个实施例中,所述不平衡数据集包括多个类别的附有类别标签的路况场景图片,所有类别的路况场景图片的数量分布符合长尾分布特性。
17、在本发明的一个实施例中,所述步骤3包括:
18、步骤3.1:将所述不平衡数据集中的路况场景图片按照类别依次输入至所述不平衡增量学习模型中;
19、步骤3.2:所述旧任务模型对输入的样本进行特征提取,得到旧模型特征,所述当前任务模型对输入的样本进行特征提取,得到新模型特征;
20、步骤3.3:所述特征滤波器对所述旧模型特征进行特征过滤,得到关键特征;
21、步骤3.4:所述旧-新编码器对所述新模型特征和所述关键特征,进行特征融合得到旧-新融合特征;
22、步骤3.5:所述头-尾编码器对当前输入的新模型特征与之前输入的新模型特征,进行特征融合得到头-尾融合特征;
23、步骤3.6:所述分类器根据输入的旧-新融合特征和头-尾融合特征,对输入的样本进行分类识别,根据分类识别结果以及分类标签计算模型损失函数;
24、步骤3.7:根据所述模型损失函数,通过反向传播更新当前任务模型、旧-新编码器、头-尾编码器和分类器的参数。
25、在本发明的一个实施例中,所述步骤3.3包括:
26、对每个类别的路况场景图片对应的旧模型特征,计算得到其特征均值;
27、计算得到对应类别中的路况场景图片的旧模型特征与特征均值之间的距离;
28、根据预设的阈值,将所述旧模型特征中距离超过阈值的特征剔除,得到对应的关键特征。
29、在本发明的一个实施例中,所述模型损失函数表示为:
30、
31、式中,表示分类损失,表示语义补偿损失,表示批处理约束损失,表示蒸馏损失,α,β,γ,δ分别表示各类损失的权重;其中,
32、
33、
34、
35、式中,nt表示当前任务的输入样本dt中的样本数,cold表示在第t阶段增量学习的所有旧类的类别数目,call=cold+ct表示第t阶段增量学习中所有类的类别数目,ct表示第t阶段增量学习中新类的类别数目,表示最后一个全连接层的权值矩阵,d表示维数,表示最后一个全连接层的偏置向量,t表示转置,||||表示范数运算,zi表示第i个样本经过当前任务模型后输出的特征,yi表示第i个样本的标签,xi表示第i个样本,表示旧任务模型,表示当前任务模型,表示头部类的语义补偿损失,表示尾部类的语义补偿损失,μ1和μ2分别表示和的权重。
36、与现有技术相比,本发明的有益效果在于:
37、本发明的基于互补关系挖掘的不平衡增量学习方法,通过构建不平衡增量学习模型实现不平衡数据的增量学习,通过头-尾编码器挖掘当前小批量之间的关系,方便少数类与大多数类的丰富特征信息,通过旧-新编码器充分利用了不同模型生成的输出特征之间的关系,以减少任务之间的灾难性遗忘,同时使用了知识蒸馏以及语义损失和微调技术,提高了模型的学习性能,本发明提供了一种新的增量学习方法,可以应用至自动驾驶等多种实际场景中,解决了传统增量学习过程中数据分布不平衡导致的性能下降问题和灾难性遗忘导致分类识别精度变差而产生的安全性问题。
38、上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
- 还没有人留言评论。精彩留言会获得点赞!