三维神经网络处理方法及图像处理方法、系统和存储介质与流程
本发明涉及三维神经网络处理方法及图像处理方法、系统和存储介质,属于神经网络以及图像处理。
背景技术:
1、随着大数据时代的来临和计算机运算能力的提高,二维神经网络即2d cnn在图像分类方面取得了最先进的精度。然而,在处理视频等高维数据时,基于图像的2d cnn无法对其中的时间信息和运动模式进行建模,因此无法取得令人满意的效果。为了实现对视频等高维数据的精确分类,研究人员提出使用三维卷积来捕获视频等数据中的时空信息。2010年,ji等人首次提出了三维卷积神经网络,其在相邻的图像帧上执行三维卷积以提取时间和空间维度上的特征。随后,tran等人提出了一个现代意义上的深度架构c3d,c3d相对于以往的三维神经网络即3d cnn具有更深的层,故而可以在大规模数据集上进行学习并取得最优的结果。此后,3d cnn在视频分析、三维几何数据分析、三维医学图像诊断方面取得了巨大的成功。然而,与算法性能提升相对应的是3d cnn显著增加的模型尺寸和计算量。例如,在网络结构相同的情况下,3d resnet34的参数数目和计算量分别为63.5m和36.7gflops,是2d resnet34(参数数目21.5m,计算量3.5gflops)的2.95倍和10.49倍。相比于2d cnn,3dcnn额外增加了时间维度以捕获时域特征,因而存在更为庞大的存算开销。因此,如何高性能、低功耗地部署3d cnn,是目前学术界和工业界的研究热点。
2、为了解决这个问题,研究者开始在算法层面采用模型压缩方法对3d cnn的存储和计算开销进行优化,目前常用的模型压缩方法包括剪枝、量化、低秩分解以及快速算法。剪枝通常寻找一种评判指标来判断参数的重要性,将不重要的参数剪去,以减少模型的冗余,其往往能带来一个较高的压缩比。然而,此类方法通常伴随着微调、重训练等过程,显著加重了三维卷积神经网络的训练负担,除此之外,剪枝还会造成非零元素的不规则分布,引起访存不规则、计算负载不均衡等问题,对硬件实现不友好。参数量化可以有效降低计算资源消耗、片上存储开销和片外访存的压力,但量化过程往往会造成巨大的精度损失,且其对计算强度的压缩效果并不明显。
3、因此量化一般作为一种辅助的压缩方法出现。低秩分解使用多个低秩矩阵来逼近高维张量,常见的分解方式包括cp分解、svd分解、tucker分解以及tensor-train分解,低秩分解可以显著降低模型推理时的计算复杂度,但其涉及计算成本高昂的分解操作,且需要大量的重训练来达到收敛,对本已非常耗时的3d cnn训练来说是无法接受的。
4、可用于加速卷积的快速算法包括快速傅立叶变换fft和winograd,此类算法先通过某种变换(快速傅立叶变换fft或者winograd变换)将特征图和权重变换到另一个域,然后在另一个域上进行计算,最后再将计算结果变换回原先的域。然而,前述方法可以有效降低模型的计算量,但却无法减少模型的参数数目。此外,winograd和快速傅立叶变换fft算法受卷积尺寸、步长的影响较大,例如两者都无法加速1×1×1卷积,而这在现代网络中占据了主要计算量,如3d resnet、3d mobilenet。
5、总而言之,上述方法仍未妥善解决3d cnn的处理效率问题,使其在能效/资源受限场景下的部署仍面临严峻的性能和能效挑战。
技术实现思路
1、针对现有技术的缺陷,本发明的目的一在于提供一种通过构建分块循环矩阵模型、计算加速模型、全频域模型,利用快速傅立叶变换fft加速计算,取得了显著的存储和计算压缩效果,并引入频域内的激活、批归一化和池化操作,从而实现了全频域计算,降低了3d cnn模型推理时的计算开销的三维神经网络处理方法。
2、本发明的目的二在于提供一种采用一种基于分块循环矩阵的三维神经网络处理方法对视频图像进行处理,能够高性能、低功耗地部署3d cnn,进而实现对视频等高维数据的精确分类以及识别,方案科学合理、切实可行,便于实现的图像处理方法。
3、本发明的目的三在于提供一种通过设置分块循环矩阵模块、计算加速模块、全频域模块,利用快速傅立叶变换fft加速计算,在保持模块结构规则的前提下,取得了显著的存储和计算压缩效果,并引入频域内的激活、批归一化和池化操作,实现了全频域计算,降低计算开销的三维神经网络处理系统。
4、本发明的目的四在于提供一种适用于各种类型的卷积核尺寸、步长,适用范围广,具有较强的通用性,能够妥善解决三维神经网络处理方法3d cnn的处理效率问题,使其能够部署在能效/资源受限场景下的三维神经网络处理方法及图像处理方法、系统和存储介质。为
5、实现上述目的之一,本发明的第一种技术方案为:
6、一种基于分块循环矩阵的三维神经网络处理方法,包括以下内容:
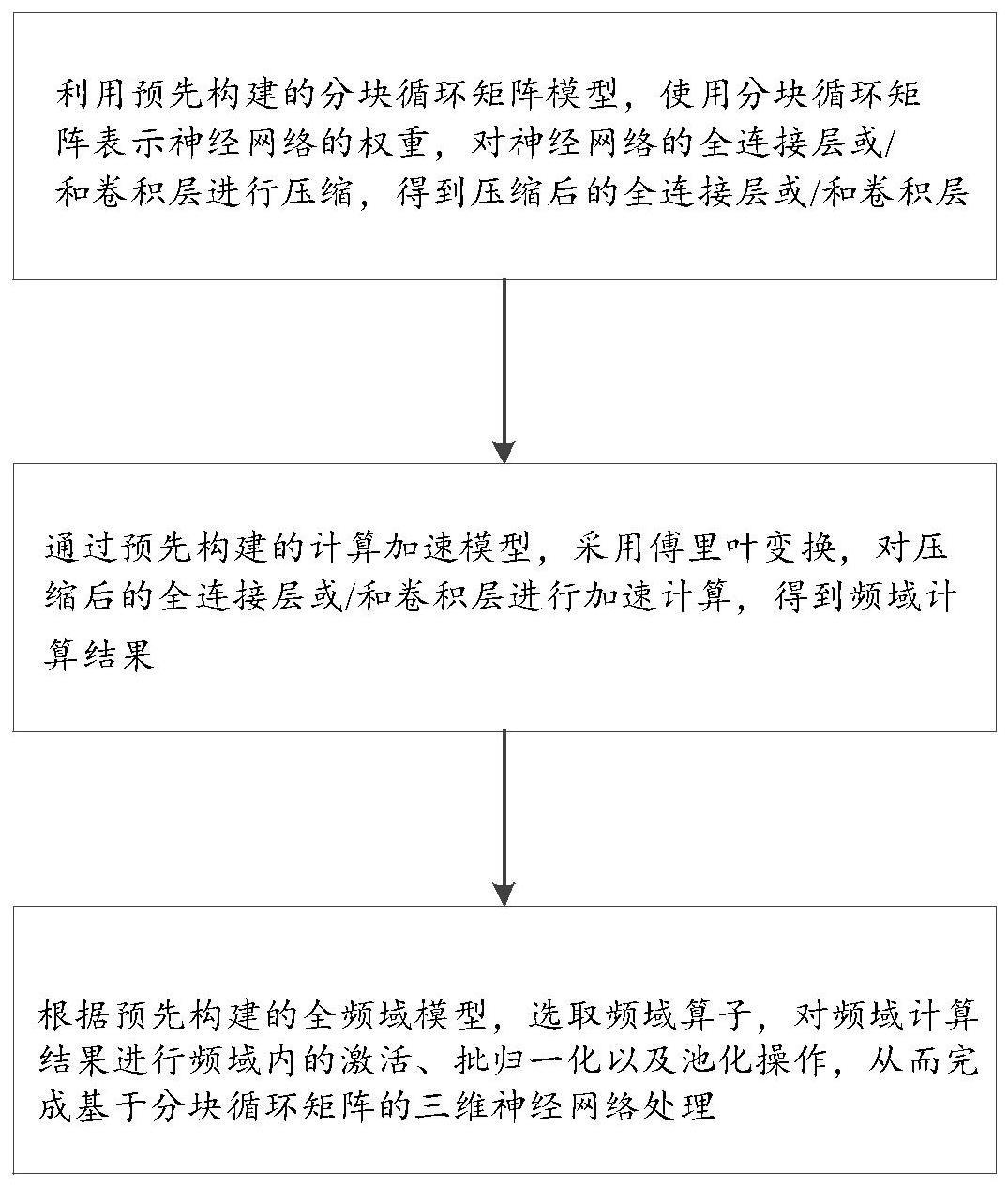
7、利用预先构建的分块循环矩阵模型,使用分块循环矩阵表示神经网络的权重,对神经网络的全连接层或/和卷积层进行压缩,得到压缩后的全连接层或/和卷积层;
8、通过预先构建的计算加速模型,采用傅立叶变换,对压缩后的全连接层或/和卷积层进行加速计算,得到频域计算结果;
9、根据预先构建的全频域模型,选取频域算子,对频域计算结果进行频域内的激活、批归一化以及池化操作,从而完成基于分块循环矩阵的三维神经网络处理。
10、本发明经过不断探索以及试验,通过构建分块循环矩阵模型、计算加速模型、全频域模型,克服以往剪枝等模型压缩方法存在的访存、计算不规则等问题,提出使用分块循环矩阵对三维神经网络3d cnn进行压缩,并且进一步利用快速傅立叶变换fft加速计算,取得了显著的存储和计算压缩效果。在此基础上,引入频域内的激活、批归一化和池化操作,进一步消除由于快速傅立叶变换fft带来的频繁的时域/频域切换开销,从而实现了全频域计算,进一步降低了3d cnn模型推理时的计算开销。
11、进而,本发明采用基于分块循环矩阵的三维神经网络处理方法,适用于各种类型的卷积核尺寸、步长,适用范围广,具有较强的通用性。此外,该三维神经网络处理方法不会给模型的训练过程带来额外的计算复杂度,方案科学合理、切实可行,便于实现,能够妥善解决三维神经网络处理方法3d cnn的处理效率问题,使其能够部署在能效/资源受限场景下。
12、作为优选技术措施:
13、分块循环矩阵模型的构建方法如下:
14、第一步,设置n×n的矩阵a,用于表示循环矩阵;
15、第二步,构造矩阵a的元素,当且仅当其每一行元素都是上一行元素循环右移一个位置的结果,通过存储矩阵a的第一列元素表示整个矩阵a,第一列元素所构成的向量为循环矩阵的生成向量。
16、作为优选技术措施:
17、计算加速模型的构建方法如下:
18、根据循环卷积算法,对相乘的循环矩阵和任意向量进行加速;
19、循环矩阵为n×n的矩阵a;
20、向量为n×1的向量x;
21、循环卷积算法的计算公式如下:
22、a·x=ifft(fft(a)⊙fft(x))#(1)
23、其中,a是矩阵a的生成向量,fft为快速傅立叶变换,ifft为快速傅立叶逆变换,⊙表示元素级乘法。
24、作为优选技术措施:
25、全频域模型的构建方法如下:
26、根据频域算子的计算复杂度和精度损失,采用crelu、cbn和cmaxpool作为频域算子,其表达式如下所示:
27、crelu(a+bi)=relu(a)+relu(b)
28、cbn(a+bi)=bn(a)+bn(b)
29、cmaxpool(a+bi)=maxpool(a)+imaxpool(b)
30、其中,relu、bn和maxpool分别是实数域上的激活、批归一化和最大池化操作,a是实数域上的数值,b为虚数域上的数值。
31、作为优选技术措施:
32、对神经网络的全连接层进行压缩的方法如下:
33、步骤11,获取全连接层的权重矩阵w,权重矩阵w的尺寸为m×n;
34、步骤12,将尺寸为m×n的权重矩阵w划分为p×q个k×k的方阵wij;
35、p=m/k,q=n/k,若无法整除,则对w进行填充,直至整除为止;
36、步骤13,将方阵wij构建为循环矩阵,用于对神经网络的参数数目进行压缩。
37、作为优选技术措施:
38、对压缩后的全连接层进行加速计算的方法如下:
39、s11,根据循环矩阵,将全连接层的计算a=w·x按照分块矩阵-向量乘法进行,其计算公式如下:
40、
41、其中,a为输出特征向量,w是一个分块循环矩阵,x为输入特征向量;ai为输出特征向量的子向量,wij为循环矩阵,xj为输入特征向量的子向量;
42、s12,通过快速傅立叶变换fft对分块矩阵-向量乘法进行加速,以降低全连接层的计算量,其计算公式如下:
43、
44、s13,利用快速傅立叶变换fft/快速傅立叶逆变换ifft的线性性质,将快速傅立叶逆变换ifft移至求和符号外,将快速傅立叶逆变换ifft的调用次数由q减少为1,其计算公式如下:
45、
46、其中,fft为快速傅立叶变换,ifft为快速傅立叶逆变换。
47、作为优选技术措施:
48、还包括,利用分块循环矩阵对神经网络的反向传播过程进行加速,其表达式如下:
49、
50、
51、其中,l为损失函数,为输出特征向量的子向量ai的第l个元素,为输入特征向量的子向量xj的第l个元素,wij为循环矩阵对应的生成向量为wij;
52、和为具有分块循环矩阵的结构,且其生成向量分别为和wij;
53、将和依次通过快速傅立叶变换fft、两个矩阵对应位置元素进行乘积、快速傅立叶逆变换ifft进行加速。
54、作为优选技术措施:
55、对神经网络的卷积层进行压缩的方法如下:
56、步骤21,获取卷积层的权重张量w,卷积层的权重张量w为一个尺寸为m×n×kd×kr×kc的五维张量;
57、其中,m为卷积层的输入通道数,n为卷积层的输出通道数,kd×kr×kc为卷积层的卷积核尺寸;
58、步骤22,将权重张量w划分为kd×kr×kc个m×n的矩阵wijk;
59、步骤23,将尺寸为m×n的矩阵wijk构建为循环矩阵,用于降低卷积层的计算和存储开销,其构建方法如下:
60、将m×n的矩阵wijk划分为p×q个b×b子矩阵wi,j,kd,kr,kc,
61、其中p=m/b,q=n/b,i=0,1,..,p-1,j=0,1,..,q-1,kd,kr,kc=0,1,…,k-1,
62、将每一个子矩阵wi,j,kd,kr,kc都设置为循环矩阵的结构。
63、作为优选技术措施:
64、对压缩后的卷积层进行加速计算的方法如下:
65、s21,根据循环矩阵,将卷积层的计算按照分块矩阵-向量乘法进行;
66、s22,通过快速傅立叶变换fft对分块矩阵-向量乘法进行加速,以降低卷积层的计算量。
67、为实现上述目的之一,本发明的第二种技术方案为:
68、一种基于三维神经网络的图像处理方法,采用上述的一种基于分块循环矩阵的三维神经网络处理方法对视频图像进行处理,以提取视频图像上的时间和空间维度上的特征。
69、本发明经过不断探索以及试验,采用一种基于分块循环矩阵的三维神经网络处理方法对视频图像进行处理,能够高性能、低功耗地部署3d cnn,进而实现对视频等高维数据的精确分类以及识别,方案科学合理、切实可行,便于实现。
70、为实现上述目的之一,本发明的第三种技术方案为:
71、一种基于分块循环矩阵的三维神经网络处理系统,包括分块循环矩阵模块、计算加速模块、全频域模块;
72、分块循环矩阵模块,使用分块循环矩阵表示神经网络的权重,对神经网络的全连接层或/和卷积层进行压缩,得到压缩后的全连接层或/和卷积层;
73、计算加速模块,采用傅立叶变换,对压缩后的全连接层或/和卷积层进行加速计算,得到频域计算结果;
74、全频域模块,选取频域算子,对频域计算结果进行频域内的激活、批归一化以及池化操作,从而完成基于分块循环矩阵的三维神经网络处理。
75、本发明经过不断探索以及试验,通过设置分块循环矩阵模块、计算加速模块、全频域模块,克服以往剪枝等模块压缩方法存在的访存、计算不规则等问题,提出使用分块循环矩阵对三维神经网络3d cnn进行压缩,并且进一步利用快速傅立叶变换fft加速计算,在保持模块结构规则的前提下,取得了显著的存储和计算压缩效果。在此基础上,引入频域内的激活、批归一化和池化操作,进一步消除由于快速傅立叶变换fft带来的频繁的时域/频域切换开销,从而实现了全频域计算,进一步降低了3d cnn模块推理时的计算开销。
76、进而,本发明采用基于分块循环矩阵的三维神经网络处理系统,适用于各种类型的卷积核尺寸、步长,适用范围广,具有较强的通用性。此外,该三维神经网络处理系统不会给模块的训练过程带来额外的计算复杂度,方案科学合理、切实可行,便于实现,能够妥善解决3d cnn的处理效率问题,使其能够部署在能效/资源受限场景下。
77、为实现上述目的之一,本发明的第四种技术方案为:
78、一种计算机可读存储介质,其上存储有计算机程序;
79、该程序被处理器执行时实现上述的一种基于分块循环矩阵的三维神经网络处理方法
80、或/和,该程序被处理器执行时实现上述的一种基于三维神经网络的图像处理方法。
81、与现有技术相比,本发明具有以下有益效果:
82、本发明经过不断探索以及试验,通过构建分块循环矩阵模型、计算加速模型、全频域模型,克服以往剪枝等模型压缩方法存在的访存、计算不规则等问题,提出使用分块循环矩阵对三维神经网络3d cnn进行压缩,并且进一步利用快速傅立叶变换fft加速计算,取得了显著的存储和计算压缩效果。在此基础上,引入频域内的激活、批归一化和池化操作,进一步消除由于快速傅立叶变换fft带来的频繁的时域/频域切换开销,从而实现了全频域计算,进一步降低了3d cnn模型推理时的计算开销。
83、进而,本发明采用基于分块循环矩阵的三维神经网络处理方法,适用于各种类型的卷积核尺寸、步长,适用范围广,具有较强的通用性。此外,该三维神经网络处理方法不会给模型的训练过程带来额外的计算复杂度,方案科学合理、切实可行,便于实现,能够妥善解决三维神经网络处理方法3d cnn的处理效率问题,使其能够部署在能效/资源受限场景下。
84、进一步,本发明经过不断探索以及试验,采用一种基于分块循环矩阵的三维神经网络处理方法对视频图像进行处理,能够高性能、低功耗地部署3d cnn,进而实现对视频等高维数据的精确分类以及识别,方案科学合理、切实可行,便于实现。
85、再进一步,本发明经过不断探索以及试验,通过设置分块循环矩阵模块、计算加速模块、全频域模块,克服以往剪枝等模块压缩方法存在的访存、计算不规则等问题,提出使用分块循环矩阵对三维神经网络3d cnn进行压缩,并且进一步利用快速傅立叶变换fft加速计算,在保持模块结构规则的前提下,取得了显著的存储和计算压缩效果。在此基础上,引入频域内的激活、批归一化和池化操作,进一步消除由于快速傅立叶变换fft带来的频繁的时域/频域切换开销,从而实现了全频域计算,进一步降低了3d cnn模块推理时的计算开销。
- 还没有人留言评论。精彩留言会获得点赞!