一种基于BERT-BiLSTM-CRF的医药实体识别方法
本发明为自然语言处理中的知识图谱领域,具体为一种引入bert预训练模型进行医药知识图谱构建方法。
背景技术:
1、
2、中文医疗知识图谱还处于快速发展阶段,于彤等基于中医药学语言系统(tcmls),构建了中医药知识图谱,融合了各类基础医学、文献、医院临床等多种数据,规模达20多亿个三元组。中国中医科学院贾李蓉等人开发了中医药学语言系统,系统集合了中医药及其相关学科的领域概念术语,该系统中采集了包含12万余个中医药概念,60万余个术语,形成语义关系127万余个的中医药知识图谱,为中医药学科的信息化提供了术语支持。wang提出了一个具有两阶段查询扩展策略的新型医学信息检索系统,它能够有效地建模并纳入潜在语义关联以提高性能。由北京大学和郑州大学联合开发的中文医学知识图谱cmekg(chinese medical knowledge graph)涵盖疾病的临床症状、发病部位、药物治疗、手术治疗等30余种常见关系类型,描述的概念关系实例及属性三元组达100余万。
3、在知识图谱构建中,实体识别重要性不言而喻,因为知识图谱的基本构成单位是实体和实体之间的关系,如果无法正确地识别实体,就无法正确地构建知识图谱,实体识别的目的是从文本中自动识别出具有特定含义的实体,并将其标注为特定的类型。在医药领域中,实体可以是疾病、药品、治疗方法等等,这些实体对于构建医药知识图谱都是非常重要的。医药存在大量的非结构化数据,需要通过实体识别技术进行实体抽取,并使用关系抽取技术得到结构化三元组,才能存入知识库中。
技术实现思路
1、构建知识图谱的主要目标是将具有复杂关系网络的非结构化数据转换为易于存储和查询的结构化三元组数据,而知识抽取是这一过程中最重要的任务之一,它包括实体识别和关系抽取。本发明基于在命名实体识别中的成功应用的bilstm-crf模型,并结合bert预训练模型,进一步提高模型的语义解析能力,能更好地抓取词语特征、增加句子的语义化,从而提高医药实体的准确性和语义丰富度。
2、本发明采用的技术方案为一种基于bert-bilstm-crf的医药实体识别方法,包括以下步骤:
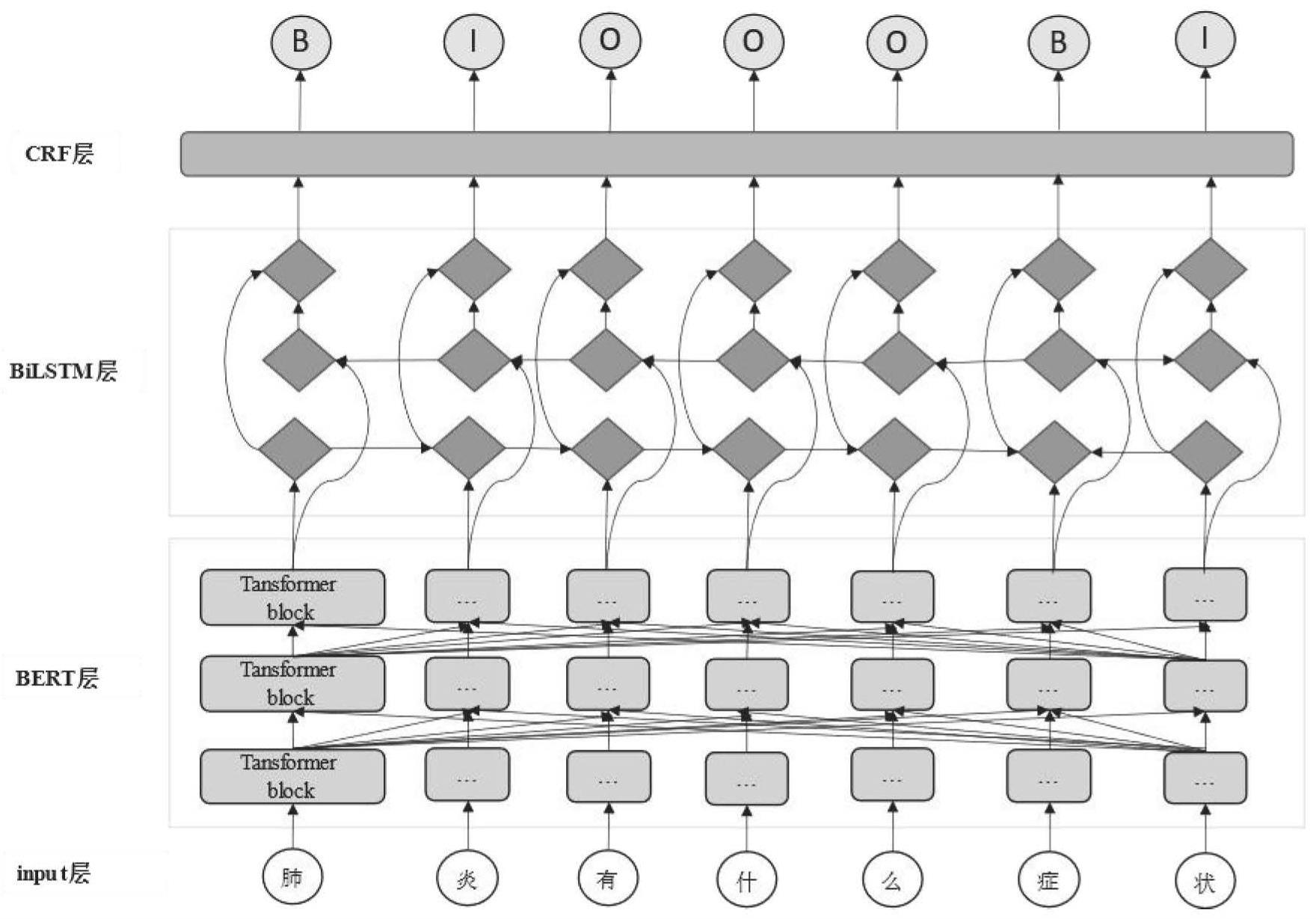
3、步骤1,input层中,输入医药实体文本序列,将预处理后的医药实体文本序列输入至bert层。
4、步骤2,bert层中,医药实体文本序列通过bert层生成具有丰富语义的医药实体词向量w=(w0,w1,w2,...,wn),其中n是医药实体句子长度,w0-wn分别为医药实体词向量元素。使用bert模型生成词向量方法对层次结构复杂、关联性强的医药数据特征捕捉能力更强。bert模型通常采用12层或24层双向transformer编码器组成的结构,并利用注意力机制对文本进行建模。模型的输入层由词嵌入层、分段嵌入层和位置嵌入层三部分组成。此外,句子的头部和尾部分别使用特殊的标记符号[cls]和[sep],用于表示句子的开始和结束,以便区分不同的句子。分段嵌入层和位置嵌入层则用于区分不同句子以及编码词向量的位置信息。bert生成词向量步骤如下:1)输入预处理:将输入句子进行标记化和分段处理,并添加特殊的开始和结束标记。2)生成位置嵌入:bert使用位置嵌入向量来表示每个单词在句子中的位置,以便模型可以了解每个单词的上下文环境。3)生成类型嵌入:bert使用类型嵌入向量来表示输入的文本是原始文本还是下一句话(用于训练next sentence prediction任务),以便模型可以了解上下文信息。4)多层transformer编码器:bert使用多层transformer编码器来学习单词之间的交互作用,并生成每个单词的向量表示。5)池化:通过对所有单词的向量表示进行平均池化或最大池化,生成整个句子的向量表示。6)全连接层:使用一个或多个全连接层来进一步处理池化向量,并生成最终的输出向量表示。7)输出:输出语义特征丰富的词向量。
5、步骤3,bilstm层中,通过双向lstm结构捕捉上下文医药实体信息,经过bilstm层能得到表示单词上下文的向量,然后经过线性层为每个输入数据打一个标签的预测分值。在bilstm层中,前向lstm在词t处从左到右计算序列并表示为后向lstm则反向计算同一序列表示为通过连接其左右上下文表示来得到词t的表示然后,在bilstm层之上的tanh层被用来预测具有每个可能标签的单词的置信度分数p,为单词对应每个实体种类的打分,作为预测分数。bilstm层由两个lstm组成,一个从前向后处理输入序列,另一个从后向前处理输入序列。两个lstm的输出在时间维度上进行拼接,从而得到双向的输出。bilstm层具体编码步骤如下:1)输入:bert层的输出作为bilstm层的输入。2)双向lstm层:这个层包括前向lstm和后向lstm,它们分别从左到右和从右到左地处理输入矩阵中的单词,生成前向和后向的隐状态序列。前向lstm和后向lstm分别使用不同的权重矩阵进行计算。3)合并:将前向和后向lstm的输出进行合并,得到每个单词的上下文向量。合并的方式可以是将前向和后向的向量拼接在一起,也可以是对它们求平均值。4)输出:输出词向量对应每个类型的分数
6、步骤4,crf层中,bilstm层输出的预测分值再传输给crf层,通过医药实体信息学习数据集中标签之间的转移概率从而修正bilstm层的输出,即加一些约束保证预测标签的合法性,从而保证预测标签的合理性。crf层具体实现步骤如下:1):crf层的输入是bilstm层输出的上下文向量序列,每个向量都对应输入句子中的一个单词。2)提取:为了将上下文向量序列标注为实体序列,需要先从上下文向量中提取有用的特征。这些特征通常基于单词和上下文的属性,如前缀、后缀、词性等。3)状态转移矩阵:crf模型需要学习一个状态转移矩阵,该矩阵表示了实体序列中不同状态(即实体标签)之间的转移概率。转移矩阵的每个元素表示从一个状态转移到另一个状态的概率。4)发射概率矩阵:crf模型还需要学习一个发射概率矩阵,该矩阵表示在给定状态下,生成不同标签的概率。发射概率矩阵的每个元素表示在给定状态下,生成特定标签的概率。5)动态规划算法:为了找到最优的实体序列,crf模型使用动态规划算法,对状态转移矩阵和发射概率矩阵进行计算,找到最优的标签序列。6)输出:crf层的输出是最优的实体序列,即对每个单词进行标注的实体标签序列。最后按照实体识别常用的bio标注法对预测的标签序列进行顺序整理达到ner目的。其中bio标注法中,每个单词被标注为三种状态之一:begin(表示单词是命名实体的开始),inside(表示单词在命名实体中),outside(表示单词不属于任何命名实体)
7、与现有技术相比,本发明结合bert预训练模型与bilstm-crf模型的优点得到了用于实体识别的bert-bilstm-crf模型。相较于传统的bilstm-crf模型,bert-bilstm-crf模型通过使用bert模型提取更丰富的语义特征,改善了原模型在embedding层仅依靠简单方式训练的词向量的表现。借助bert模型的强大的特征抽取能力,通过bert预训练模型得到单词的embedding,能使词语特征表达更强,且bert预训练出来的是动态词向量,能够在不同的语境中表达不同的语义,而传统的语言预训练模型训练出来的是静态词向量,无法表达一词多义,因此引入bert预训练模型能更好抓取词语特征、增加句子的语义化。在医药信息处理任务中,由于医药信息结构复杂且相关性强,通过引入bert能够更准确、丰富地表达医药信息的相关特征。
8、在深度学习中实体识别任务实际上是序列标注任务,模型的输入是文本序列,例如“肺炎是疾病”,模型输出是由bio标签体系定义的一串标签,其中b是词的开始,i是词的中间到结尾,o是其他类型词,所以可得输出序列为“biobi”,分词结果为“肺炎/是/疾病”。
- 还没有人留言评论。精彩留言会获得点赞!