用于语言信息处理的神经网络训练方法及装置与流程
本公开涉及人工智能领域,更具体地,涉及一种用于语言信息处理的神经网络训练方法、装置、计算机程序产品和存储介质,以及一种语言信息处理方法、装置、计算机程序产品和存储介质。
背景技术:
1、自然语言处理(natural language processing,nlp)技术是与自然语言的计算机处理有关的所有技术的统称,其目的是使计算机能够分析、理解人类自然语言输入的指令,从而完成语言翻译、语义分析等功能。自然语言处理技术的核心为语义分析。语义分析是一种基于自然语言进行语义信息分析的方法,主要包括词语级语义分析、词语级语义分析、以及篇章级语义分析。词语级语义分析关注如何理解某个词汇的含义,目前研究方向主要包括:词义消歧以及词义表示和学习。句子级的语义分析试图根据句子的句法结构和句中词的词义等信息,推导出能够反映这个句子意义的某种形式化表示。篇章结构分析旨在分析出一个篇章中,子句、句子或语段间具有的层次结构和语义关系。
2、目前的语义分析一方面只关注于分析语句中的主体信息(例如,句子中的主语、动词等)之间的关系,忽略了语句中的属性信息(例如,情感信息等);另一方面只基于有限的训练集数据进行训练,并没有利用知识库的信息。因此,目前的语言信息处理模型的语言分析准确率仍然需要提高。
技术实现思路
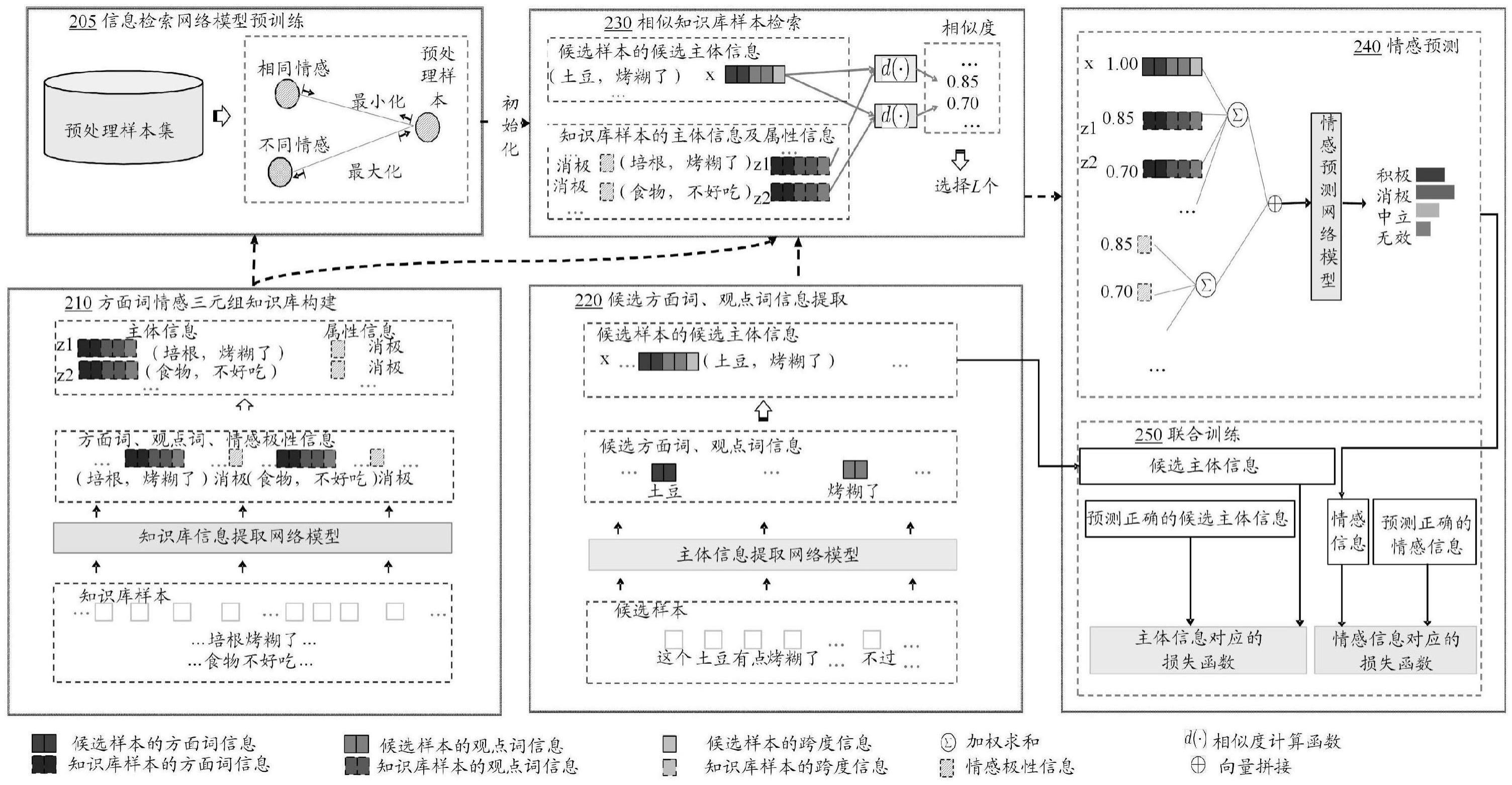
1、为了解决上述问题,本公开提供了一种用于语言信息处理的神经网络训练方法、装置、计算机程序产品和存储介质,以及一种语言信息处理方法、装置、计算机程序产品和存储介质。本公开提供的用于语言信息处理的神经网络训练方法包括:通过主体信息提取网络模型针对候选训练集中的每个候选样本提取多个候选主体信息;对于所述每个候选样本的每个候选主体信息,在知识库中检索主体信息与该候选主体信息对应的至少一个知识库样本,其中,每个所述知识库样本具有主体信息以及属性信息;将所述每个候选主体信息、以及与其对应的所述至少一个知识库样本的主体信息和属性信息进行融合,以得到融合向量,并通过属性确定网络模型来确定所述融合向量所对应的属性分类;以及基于所述候选训练集中的每个候选样本的每个候选主体信息的所述融合向量对所述主体信息提取网络模型,以及所述属性确定网络模型进行联合训练,以迭代更新所述主体信息提取网络模型,以及所述属性确定网络模型的网络参数。
2、本公开的用于语言信息处理的神经网络训练方法,能够充分利用知识库中的数据来提升用于语言信息处理的神经网络模型的分析准确度。此外,本公开的神经网络模型能够同时考虑待分析语句的主体信息以及属性信息来进行语言信息处理,因此语言信息处理的准确度得到明显提高。
3、根据本公开的实施例,所述通过主体信息提取网络模型针对候选训练集中的每个候选样本提取多个候选主体信息包括:对每个候选样本所对应的多个主体信息进行筛选,以确定该候选样本的多个候选主体信息。
4、根据本公开的实施例,所述对每个候选样本所对应的多个主体信息进行筛选,以确定该候选样本的多个候选主体信息包括:通过所述主体信息提取网络模型计算该候选样本的各主体信息被正确分类的预测概率,并且对各主体信息所对应的预测概率进行排序,并将预测概率最高的第一数量的主体信息作为该候选样本的多个候选主体信息,或者将所述预测概率大于第一阈值的候选样本以作为该候选样本的多个候选主体信息。
5、根据本公开的实施例,所述主体信息包括方面词信息及观点词信息,所述属性信息包括情感信息,其中,所述对每个候选样本所对应的多个主体信息进行筛选,以确定该候选样本的多个候选主体信息,包括:对于该候选样本,从该候选样本中提取多个方面词信息,并基于每个方面词信息的预测概率,确定该候选样本的预测概率最高的第二数量的方面词信息;从该候选样本中提取多个观点词信息,并基于每个观点词信息的预测概率,确定该候选样本的预测概率最高的第三数量的观点词信息,所述第二数量与第三数量是相同或不同的整数;对所述第二数量的方面词信息和所述第三数量的观点词信息进行两两配对,以形成该候选样本的多个候选主体信息。
6、根据本公开的实施例,所述将所述每个候选样本的主体信息和与其对应的知识库样本的主体信息、知识库样本的属性信息进行融合,以得到融合向量包括:将所述每个候选样本的主体信息和与其对应的知识库样本的主体信息、知识库样本的属性信息进行拼接,以得到所述融合向量。
7、根据本公开的实施例,所述将所述每个候选样本的主体信息和与其对应的知识库样本的主体信息、知识库样本的属性信息进行拼接还包括:对于与所述候选主体信息所对应的每个知识库样本,将每个知识库样本的主体信息与知识库样本的属性信息进行拼接,得到第一拼接向量;对所有与所述候选主体信息所对应的知识库样本的第一拼接向量进行加权求和,得到第二拼接向量;将所述每个候选样本的候选主体信息和与其对应的所述第二拼接向量进行拼接,以得到所述融合向量。
8、根据本公开的实施例,所述基于所述候选训练集中的每个候选样本的每个候选主体信息的所述融合向量对所述主体信息提取网络模型,以及所述属性确定网络模型进行联合训练包括:对于所述候选训练集中的每个候选样本的每个候选主体信息,通过所述主体信息提取网络模型来计算表示所述候选主体信息被正确预测的第一预测概率;对于所述候选训练集中的每个候选样本的每个候选主体信息,基于所述候选主体信息的所述融合向量通过所述属性确定网络模型来计算表示所述属性信息被正确预测的第二预测概率;基于所述候选训练集中的各候选样本的每个候选主体信息的所述第一预测概率和所述第二预测概率构建交叉熵损失函数,并基于所述交叉熵损失函数对所述主体信息提取网络模型,以及所述属性确定网络模型进行联合训练。
9、根据本公开的实施例,在利用信息检索网络模型在知识库中检索主体信息与该候选主体信息对应的至少一个知识库样本之前,利用预处理样本集对所述信息检索网络模型进行预训练,以使属性信息相同样本之间的相关性分数增高,属性信息相反的样本之间的相关性分数降低,其中,所述预处理样本集与所述候选训练集不同。
10、根据本公开的实施例,所述利用预处理样本集对所述信息检索网络模型进行预训练包括:利用所述主体信息提取网络模型提取所述预处理样本集中的每个预处理样本的主体信息;利用所述属性确定网络模型获取每个所述预处理样本的预测属性信息;对于每个预处理样本,通过所述信息检索网络模型检索所述预处理样本集和所述知识库中,主体信息与所述预处理样本的主体信息的相似度大于第二阈值的样本作为备选样本集,并且基于所述备选样本集中,属性信息与该预处理样本的所述预测属性信息相同的第一样本,和属性信息与该预处理样本的所述预测属性信息相反的第二样本进行比对学习,以对所述信息检索网络模型进行预训练。
11、根据本公开的实施例,对于所述每个候选样本的每个候选主体信息,利用信息检索网络模型在知识库中检索主体信息与该候选主体信息对应的至少一个知识库样本,其中,对于每个所述知识库样本,通过知识库信息提取网络模型来获取该知识库样本的主体信息以及属性信息;以及基于所述候选训练集中的每个候选样本的每个候选主体信息的所述融合向量对所述主体信息提取网络模型、所述属性确定网络模型、所述信息检索网络模型以及所述知识库信息提取网络模型进行联合训练,以迭代更新所述主体信息提取网络模型、所述属性确定网络模型、所述信息检索网络模型以及所述知识库信息提取网络模型的网络参数。
12、根据本公开的实施例,所述对于所述每个候选样本的每个候选主体信息,利用信息检索网络模型在知识库中检索主体信息与该候选主体信息对应的至少一个知识库样本包括:对于每个候选主体信息,通过所述信息检索网络模型来计算各知识库样本的主体信息与该候选主体信息之间的相似度,并且对所述相似度进行排序,并将所述相似度最高的第四数量个知识库样本作为与该候选主体信息对应的知识库样本,或者将所述相似度大于第三阈值的知识库样本作为与该候选主体信息对应的知识库样本。
13、本公开的实施例还提供了一种语言信息处理方法,包括:获取待分析语句及与所述待分析语句相关的知识库;利用语言信息处理神经网络模型在所述知识库中检索与所述待分析语句之间的相似度高于预定阈值的知识库样本,并基于所述待分析语句以及与所述待分析语句之间的相似度高于预定阈值的所述知识库样本来确定所述待分析语句的主体信息和属性信息,其中,所述语言信息处理神经网络模型包括通过上述神经网络训练方法训练的主体信息提取网络模型以及属性确定网络模型;以及基于所提取的所述主体信息和所述属性信息进行语义分析,以获取对应于所述待分析语句的语义分析结果。
14、根据本公开的实施例,所述基于所提取的所述主体信息和所述属性信息进行语义分析包括以下中的至少一项:对所述待分析语句进行关键信息分析、对所述待分析语句进行情感分析、根据所述待分析语句进行相关信息推荐。
15、本公开的实施例还提供了一种用于语言信息处理的神经网络训练装置,包括:主体信息提取模块,被配置为通过主体信息提取网络模型针对候选训练集中的每个候选样本提取多个候选主体信息;检索模块,被配置为对于所述每个候选样本的每个候选主体信息,在知识库中检索主体信息与该候选主体信息对应的至少一个知识库样本,其中,每个所述知识库样本具有主体信息以及属性信息;融合模块,被配置为将所述每个候选主体信息、以及与其对应的所述至少一个知识库样本的主体信息和属性信息进行融合,以得到融合向量,并通过属性确定网络模型来确定所述融合向量所对应的属性分类;以及联合训练模块,被配置为基于所述候选训练集中的每个候选样本的每个候选主体信息的所述融合向量对所述主体信息提取网络模型,以及所述属性确定网络模型进行联合训练,以迭代更新所述主体信息提取网络模型,以及所述属性确定网络模型的网络参数。
16、本公开的实施例还提供了一种语言信息处理装置,包括:语句获取模块,被配置为获取待分析语句及与所述待分析语句相关的知识库;语句信息确定模块,被配置为利用语言信息处理神经网络模型在所述知识库中检索与所述待分析语句之间的相似度高于预定阈值的知识库样本,并基于所述待分析语句以及与所述待分析语句之间的相似度高于预定阈值的所述知识库样本来确定所述待分析语句的主体信息和属性信息,其中,所述语言信息处理神经网络模型包括通过上述神经网络训练方法训练的主体信息提取网络模型以及属性确定网络模型;以及结果获取模块,被配置为基于所提取的所述主体信息和所述属性信息进行语义分析,以获取对应于所述待分析语句的语义分析结果。
17、本公开的实施例提供了一种计算机程序产品,计算机程序产品包括计算机软件代码,计算机软件代码在被处理器运行时,提供上述方法。
18、本公开的实施例提供了一种计算机可读存储介质,其上存储有计算机可执行指令,指令在被处理器执行时,提供上述方法。
19、本公开的用于语言信息处理的神经网络训练方法,通过利用知识库中的数据,并同时考虑待分析语句的主体信息以及属性信息来对主体信息提取网络模型、属性确定网络模型进行联合训练,能够明显提升用于语言信息处理的神经网络模型的分析准确度。
20、此外,本技术的用于语言信息处理的神经网络训练方法通过利用与候选训练集不同的其它预处理样本集对信息检索网络模型进行预训练,能够使属性信息相同样本之间的相关性分数增高,属性信息相反的样本之间的相关性分数降低,从而使用于语言信息处理的神经网络模型的属性信息预测更为准确,在训练数据有限的情况下,能够防止模型出现过拟合现象,提升了模型的稳定性。
- 还没有人留言评论。精彩留言会获得点赞!