目标识别方法、装置、电子设备和存储介质与流程
本技术涉及计算机视觉,尤其涉及一种目标识别方法、装置、电子设备和存储介质。
背景技术:
1、从目标的角度感知和理解视觉场景,一直以来是计算机视觉技术发展的主要驱动力,受深度神经网络架构和大规模数据集的助力,目标检测已经取得了巨大的成功。目前,目标检测任务旨在定位图像中的目标并为目标分配一个预先定义好的类别标签,例如“车”、“人”或“树”,但这种定义过度简化了人类对于视觉世界的认知,因为一个目标往往可以从多个方面来表征,例如,一辆车可以具有“黄色的”、“长的”、“金属的”、“动态的”等多种属性,仅通过类别无法充分描述目标,导致对目标的感知程度受限。
技术实现思路
1、本技术提供一种目标识别方法、装置、电子设备和存储介质,可以同时实现对目标进行定位、类别识别以及属性识别,有利于提高对目标的感知程度。
2、第一方面,本技术实施例提供了一种目标识别方法,所述方法包括:
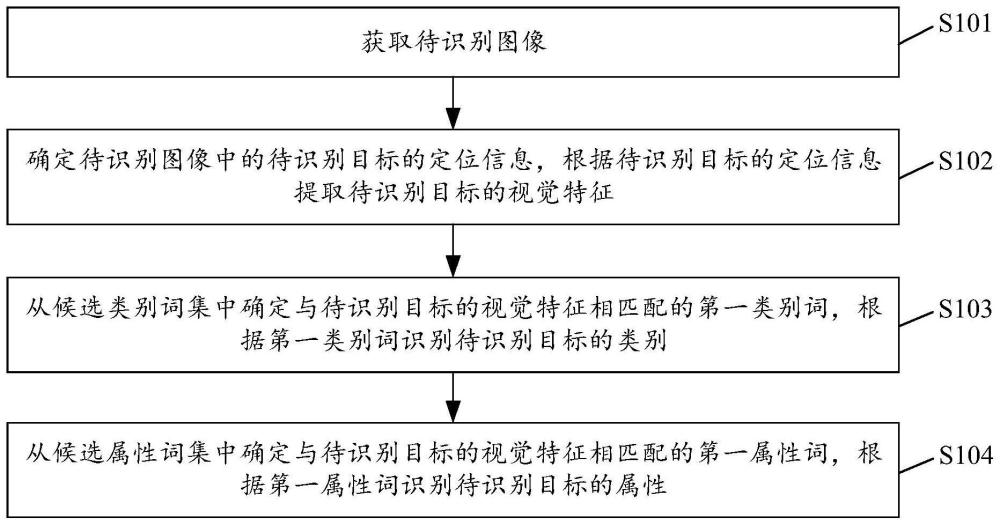
3、获取待识别图像;
4、确定所述待识别图像中的待识别目标的定位信息,根据所述待识别目标的定位信息提取所述待识别目标的视觉特征;
5、从候选类别词集中确定与所述待识别目标的视觉特征相匹配的第一类别词,根据所述第一类别词识别所述待识别目标的类别;
6、从候选属性词集中确定与所述待识别目标的视觉特征相匹配的第一属性词,根据所述第一属性词识别所述待识别目标的属性。
7、通过上述实施例,利用待识别目标的定位信息可以对待识别目标进行定位,根据候选类别词集中与待识别目标的视觉特征相匹配的第一类别词可以识别待识别目标的类别,根据候选属性词集中与待识别目标的视觉特征相匹配的第一属性词可以识别待识别目标的属性,据此可以同时实现对目标的定位、类别识别以及属性识别,有利于提高对目标的感知程度。
8、在一些可能的实施方式中,所述从候选类别词集中确定与所述待识别目标的视觉特征相匹配的第一类别词,包括:
9、计算所述待识别目标的视觉特征与所述候选类别词集中各候选类别词的文本特征之间的相似度,将大于阈值的相似度中的最大相似度所对应的候选类别词确定为所述第一类别词。
10、通过上述实施方式,利用待识别目标的视觉特征与各候选类别词的文本特征之间的相似度,来衡量各候选类别词与待识别目标是否相匹配,将大于阈值的相似度中的最大相似度所对应的候选类别词作为第一类别词,有利于准确识别待识别目标的类别。
11、在一些可能的实施方式中,所述从候选属性词集中确定与所述待识别目标的视觉特征相匹配的第一属性词,包括:
12、计算所述待识别目标的视觉特征与所述候选属性词集中各候选属性词的文本特征之间的相似度,将大于阈值的相似度所对应的候选属性词确定为所述第一属性词。
13、通过上述实施方式,利用待识别目标的视觉特征与各候选属性词的文本特征之间的相似度,来衡量各候选属性词与待识别目标是否相匹配,将大于阈值的相似度所对应的候选属性词作为第一属性词,有利于准确识别待识别目标的属性。
14、在一些可能的实施方式中,所述确定所述待识别图像中的待识别目标的定位信息,根据所述待识别目标的定位信息提取所述待识别目标的视觉特征,包括:
15、利用区域生成网络,基于所述待识别图像对所述待识别目标进行定位,生成所述待识别目标的边界框;
16、根据所述待识别目标的边界框,从所述待识别图像中提取对应所述待识别目标的子图像;
17、利用视觉语言模型中的视觉编码器,基于所述子图像提取所述待识别目标的视觉特征。
18、通过上述实施方式,先利用区域生成网络基于待识别图像对待识别目标进行定位,以便于从待识别图像中提取对应待识别目标的子图像,再利用视觉编码器基于子图像进行特征提取,有利于准确获得待识别目标的视觉特征。
19、在一些可能的实施方式中,还包括:
20、利用所述视觉语言模型中的文本编码器,根据所述候选类别词集中各候选类别词及其扩展信息提取各所述候选类别词的文本特征,根据所述候选属性词集中各候选属性词及其扩展信息提取各所述候选属性词的文本特征;其中,所述扩展信息包括父类词和提示向量。
21、通过上述实施方式,利用父类词和提示向量对候选类别词和候选属性词进行扩充,再利用视觉语言模型中的文本编码器基于扩充后信息进行特征提取,使获得的候选类别词的文本特征和候选属性词的文本特征都能够更好地与待识别目标的视觉特征对齐,从而有利于准确识别目标的类别和属性。
22、在一些可能的实施方式中,所述视觉语言模型的训练方法包括:
23、获取对应第一样本目标的第一样本子图像、以及对应第二样本目标的第二样本子图像,所述第一样本目标设有类别标签,所述第二样本目标设有属性标签;
24、利用预训练视觉语言模型中的视觉编码器,基于所述第一样本子图像提取所述第一样本目标的视觉特征,基于所述第二样本目标图像提取所述第二样本目标的视觉特征;
25、利用所述预训练视觉语言模型中的文本编码器,根据各样本类别词及其扩展信息提取各所述样本类别词的文本特征,根据各样本属性词及其扩展信息提取各所述样本属性词的文本特征;
26、根据所述第一样本目标的视觉特征与各所述样本类别词的文本特征之间的相似度、以及所述第一样本目标的类别标签,计算类别损失;
27、根据所述第二样本目标的视觉特征与各所述样本属性词的文本特征之间的相似度、以及所述第二样本目标的属性标签,计算属性损失;
28、根据所述类别损失和所述属性损失,调整所述待训练视觉语言模型的参数,获得所述视觉语言模型。
29、通过上述实施方式,利用第一样本子图像和第一样本目标的类别标签、以及第二样本子图像和第二样本目标的属性标签进行联合训练,据此获得的视觉语言模型能够同时实现对目标的类别识别和属性识别,并且具有较好的泛化性。
30、在一些可能的实施方式中,所述确定所述待识别图像中的待识别目标的定位信息,根据所述待识别目标的定位信息提取所述待识别目标的视觉特征,包括:
31、利用视觉语言模型中的视觉编码器,基于所述待识别图像提取整体视觉特征图像;
32、利用目标检测模型中的区域生成网络,基于所述整体视觉特征图像对所述待识别目标进行定位,生成所述待识别目标的边界框;
33、根据所述待识别目标的边界框,从所述整体视觉特征图像中提取对应所述待识别目标的视觉特征子图像;
34、利用所述目标检测模型中的特征提取网络,基于所述视觉特征子图像提取所述待识别目标的视觉特征。
35、通过上述实施方式,先利用视觉编码器基于待识别图像提取整体视觉特征图像,再利用区域生成网络基于整体视觉特征图像对待识别目标进行定位,以便于从整体视觉特征图像中提取对应待识别目标的视觉特征子图像,然后利用特征提取网络基于视觉特征子图像进行特征提取,据此有利于快速获得待识别目标的视觉特征。
36、在一些可能的实施方式中,所述目标检测模型的训练方法包括:
37、获取第一样本图像和第二样本图像,所述第一样本图像中的第一样本目标设有标注框和类别标签、所述第二样本图像中的第二样本目标设有标注框和属性标签;
38、利用视觉语言模型中的视觉编码器,基于所述第一样本图像提取第一整体视觉特征图像,基于所述第二样本图像提取第二整体视觉特征图像;
39、利用待训练目标检测模型中的区域生成网络,基于所述第一整体视觉特征图像生成所述第一样本目标的预测框,基于所述第二整体视觉特征图像生成所述第二样本目标的预测框;
40、根据所述第一样本目标的预测框,从所述第一整体视觉特征图像中提取对应所述第一样本目标的第一视觉特征子图像,根据所述第二样本目标的预测框,从所述第二整体视觉特征图像中提取对应所述第二样本目标的第二视觉特征子图像;
41、利用所述待训练目标检测模型中的特征提取网络,基于所述第一视觉特征子图像提取所述第一样本目标的第一视觉特征,基于所述第二视觉特征子图像提取所述第二样本目标的第一视觉特征;
42、利用所述视觉语言模型中的文本编码器,根据各样本类别词及其扩展信息提取各所述样本类别词的文本特征,根据各样本属性词及其扩展信息提取各所述样本属性词的文本特征;
43、根据所述第一样本目标的预测框和标注框、以及所述第二样本目标的预测框和标注框,计算定位损失;
44、根据所述第一样本目标的第一视觉特征与各所述样本类别词的文本特征之间的相似度、以及所述第一样本目标的类别标签,计算类别损失;
45、根据所述第二样本目标的第一视觉特征与各所述样本属性词的文本特征之间的相似度、以及所述第二样本目标的属性标签,计算属性损失;
46、根据所述定位损失、所述类别损失和所述属性损失,调整所述待训练目标检测模型的参数,获得所述目标检测模型。
47、通过上述实施方式,利用第一样本图像以及第一样本目标的标注框和类别标签、第二样本图像以及第二样本目标的标注框和属性标签进行联合训练,据此获得的目标检测模型与视觉语言模型形成的整体识别框架,能够同时实现对目标的定位、类别识别以及属性识别,并且其计算量较小,有利于提高目标识别效率。
48、在一些可能的实施方式中,所述目标检测模型的训练方法还包括:
49、根据所述第一样本目标的标注框,从所述第一样本图像中提取对应所述第一样本目标的第一样本子图像,根据所述第二样本目标的标注框,从所述第二样本图像中提取对应所述第二样本目标的第二样本子图像;
50、利用所述视觉语言模型中的视觉编码器,基于所述第一样本子图像提取所述第一样本目标的第二视觉特征,基于所述第二样本子图像提取所述第二样本目标的第二视觉特征;
51、利用所述视觉语言模型中的文本编码器,根据各新增类别词及其扩展信息提取各所述新增类别词的文本特征,根据各新增属性词及其扩展信息提取各所述新增属性词的文本特征;
52、根据所述第一样本目标的第一视觉特征和第二视觉特征与各潜在类别词的文本特征之间的相似度差异,以及所述第二样本目标的第一视觉特征和第二视觉特征与各潜在属性词的文本特征之间的相似度差异,计算辅助损失,其中,所述潜在类别词包括所述样本类别词和所述新增类别词,所述潜在属性词包括所述样本属性词和所述新增属性词;
53、所述根据所述定位损失、所述类别损失和所述属性损失,调整所述待训练目标检测模型的参数,获得所述目标检测模型,包括:
54、根据所述定位损失、所述类别损失、所述属性损失和所述辅助损失,调整所述待训练目标检测模型的参数,获得所述目标检测模型。
55、通过上述实施方式,在模型训练过程中引入额外的蒸馏项,继承了用于开放性词汇识别的知识,用以帮助模型学习对于新的类别和属性的识别能力,从而有利于提高模型的泛化性。
56、第二方面,本技术实施例提供了一种目标识别装置,所述装置包括:
57、获取单元,用于获取待识别图像;
58、处理单元,用于确定所述待识别图像中的待识别目标的定位信息,根据所述待识别目标的定位信息提取所述待识别目标的视觉特征;
59、类别识别单元,用于从候选类别词集中确定与所述待识别目标的视觉特征相匹配的第一类别词,根据所述第一类别词识别所述待识别目标的类别;
60、属性识别单元,用于从候选属性词集中确定与所述待识别目标的视觉特征相匹配的第一属性词,根据所述第一属性词识别所述待识别目标的属性。
61、在一些可能的实施方式中,所述类别识别单元在从候选类别词集中确定与所述待识别目标的视觉特征相匹配的第一类别词时,具体用于:计算所述待识别目标的视觉特征与所述候选类别词集中各候选类别词的文本特征之间的相似度,将大于阈值的相似度中的最大相似度所对应的候选类别词确定为所述第一类别词。
62、在一些可能的实施方式中,所述属性识别单元在从候选属性词集中确定与所述待识别目标的视觉特征相匹配的第一属性词时,具体用于:计算所述待识别目标的视觉特征与所述候选属性词集中各候选属性词的文本特征之间的相似度,将大于阈值的相似度所对应的候选属性词确定为所述第一属性词。
63、在一些可能的实施方式中,所述处理单元具体用于:
64、利用区域生成网络,基于所述待识别图像对所述待识别目标进行定位,生成所述待识别目标的边界框;
65、根据所述待识别目标的边界框,从所述待识别图像中提取对应所述待识别目标的子图像;
66、利用视觉语言模型中的视觉编码器,基于所述子图像提取所述待识别目标的视觉特征。
67、在一些可能的实施方式中,所述处理单元还用于:
68、利用所述视觉语言模型中的文本编码器,根据所述候选类别词集中各候选类别词及其扩展信息提取各所述候选类别词的文本特征,根据所述候选属性词集中各候选属性词及其扩展信息提取各所述候选属性词的文本特征;其中,所述扩展信息包括父类词和提示向量。
69、在一些可能的实施方式中,所述视觉语言模型的训练方法包括:
70、获取对应第一样本目标的第一样本子图像、以及对应第二样本目标的第二样本子图像,所述第一样本目标设有类别标签,所述第二样本目标设有属性标签;
71、利用预训练视觉语言模型中的视觉编码器,基于所述第一样本子图像提取所述第一样本目标的视觉特征,基于所述第二样本目标图像提取所述第二样本目标的视觉特征;
72、利用所述预训练视觉语言模型中的文本编码器,根据各样本类别词及其扩展信息提取各所述样本类别词的文本特征,根据各样本属性词及其扩展信息提取各所述样本属性词的文本特征;
73、根据所述第一样本目标的视觉特征与各所述样本类别词的文本特征之间的相似度、以及所述第一样本目标的类别标签,计算类别损失;
74、根据所述第二样本目标的视觉特征与各所述样本属性词的文本特征之间的相似度、以及所述第二样本目标的属性标签,计算属性损失;
75、根据所述类别损失和所述属性损失,调整所述待训练视觉语言模型的参数,获得所述视觉语言模型。
76、在一些可能的实施方式中,所述处理单元具体用于:
77、利用视觉语言模型中的视觉编码器,基于所述待识别图像提取整体视觉特征图像;
78、利用目标检测模型中的区域生成网络,基于所述整体视觉特征图像对所述待识别目标进行定位,生成所述待识别目标的边界框;
79、根据所述待识别目标的边界框,从所述整体视觉特征图像中提取对应所述待识别目标的视觉特征子图像;
80、利用所述目标检测模型中的特征提取网络,基于所述视觉特征子图像提取所述待识别目标的视觉特征。
81、在一些可能的实施方式中,所述目标检测模型的训练方法包括:
82、获取第一样本图像和第二样本图像,所述第一样本图像中的第一样本目标设有标注框和类别标签、所述第二样本图像中的第二样本目标设有标注框和属性标签;
83、利用视觉语言模型中的视觉编码器,基于所述第一样本图像提取第一整体视觉特征图像,基于所述第二样本图像提取第二整体视觉特征图像;
84、利用待训练目标检测模型中的区域生成网络,基于所述第一整体视觉特征图像生成所述第一样本目标的预测框,基于所述第二整体视觉特征图像生成所述第二样本目标的预测框;
85、根据所述第一样本目标的预测框,从所述第一整体视觉特征图像中提取对应所述第一样本目标的第一视觉特征子图像,根据所述第二样本目标的预测框,从所述第二整体视觉特征图像中提取对应所述第二样本目标的第二视觉特征子图像;
86、利用所述待训练目标检测模型中的特征提取网络,基于所述第一视觉特征子图像提取所述第一样本目标的第一视觉特征,基于所述第二视觉特征子图像提取所述第二样本目标的第一视觉特征;
87、利用所述视觉语言模型中的文本编码器,根据各样本类别词及其扩展信息提取各所述样本类别词的文本特征,根据各样本属性词及其扩展信息提取各所述样本属性词的文本特征;
88、根据所述第一样本目标的预测框和标注框、以及所述第二样本目标的预测框和标注框,计算定位损失;
89、根据所述第一样本目标的第一视觉特征与各所述样本类别词的文本特征之间的相似度、以及所述第一样本目标的类别标签,计算类别损失;
90、根据所述第二样本目标的第一视觉特征与各所述样本属性词的文本特征之间的相似度、以及所述第二样本目标的属性标签,计算属性损失;
91、根据所述定位损失、所述类别损失和所述属性损失,调整所述待训练目标检测模型的参数,获得所述目标检测模型。
92、在一些可能的实施方式中,所述目标检测模型的训练方法还包括:
93、根据所述第一样本目标的标注框,从所述第一样本图像中提取对应所述第一样本目标的第一样本子图像,根据所述第二样本目标的标注框,从所述第二样本图像中提取对应所述第二样本目标的第二样本子图像;
94、利用所述视觉语言模型中的视觉编码器,基于所述第一样本子图像提取所述第一样本目标的第二视觉特征,基于所述第二样本子图像提取所述第二样本目标的第二视觉特征;
95、利用所述视觉语言模型中的文本编码器,根据各新增类别词及其扩展信息提取各所述新增类别词的文本特征,根据各新增属性词及其扩展信息提取各所述新增属性词的文本特征;
96、根据所述第一样本目标的第一视觉特征和第二视觉特征与各潜在类别词的文本特征之间的相似度差异,以及所述第二样本目标的第一视觉特征和第二视觉特征与各潜在属性词的文本特征之间的相似度差异,计算辅助损失,其中,所述潜在类别词包括所述样本类别词和所述新增类别词,所述潜在属性词包括所述样本属性词和所述新增属性词;
97、所述根据所述定位损失、所述类别损失和所述属性损失,调整所述待训练目标检测模型的参数,获得所述目标检测模型,包括:
98、根据所述定位损失、所述类别损失、所述属性损失和所述辅助损失,调整所述待训练目标检测模型的参数,获得所述目标检测模型。
99、第三方面,本技术实施例提供了一种电子设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述第一方面及其任意一种可能的实施方式中的方法。
100、第四方面,本技术实施例提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序被处理器执行时实现上述第一方面及其任意一种可能的实施方式中的方法。
101、第五方面,本技术实施例提供了一种计算机程序产品,所述计算机程序产品包括计算机程序,所述计算机程序被处理器执行时实现上述第一方面及其任意一种可能的实施方式中的方法。
102、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,而非限制本技术的技术方案。
- 还没有人留言评论。精彩留言会获得点赞!