基于单视角彩色图像的三维人群数据生成方法
本发明涉及基于单视角彩色图像的三维人群数据生成方法,属于计算机视觉及计算机图形学领域。
背景技术:
1、人群三维数据生成在人群行为分析、人群安全监督、体育运动广播等方面有着重要的作用。随着人体动作捕捉技术、人体三维重建技术的迅速发展,现实商业应用对人体三维数据的需求量逐渐增大。现有的基于单视角彩色图像的人体数据生成方法仅针对单一人体或较小规模场景下的少量人体,难以实现对于大场景下人群三维数据的生成。基于单视角彩色图像生成三维人群数据,以满足相关应用对于大规模三维人群数据的需求,已经成为亟待解决的问题。然而,这一问题面临以下几个难点:首先是现有方法利用游戏引擎、渲染等技术合成产生的三维人群数据往往不具备足够的真实性,难以模拟真实人群行为,因而训练得到的网络模型无法较好地泛化到现实场景;另外现有的数据生成方法在网络模型构建过程中没有利用人群深度、位置关系的约束,导致网络模型生成的三维人体数据往往与实际人群情况有较大的差异。因此,通过现有人体数据集来合成满足模型训练需求的大场景、大规模人群数据以及在训练过程中构建全新的、高效的约束方式以避免人群深度、位置关系的错误预测将有望推动目前三维人群数据生成方法的进步。
技术实现思路
1、发明目的:本发明提出一种基于单视角彩色图像的三维人群数据生成方法。该方法首先利用现有三维人体数据在构建的虚拟场景中合成人群训练数据,利用虚拟数据训练三维人体回归网络,基于单视角人群视频或现有大场景人体数据集获取单视角彩色图像,经过目标检测、二维姿态估计和掩膜分割后,输入训练完的三维人体回归网络并构建相关约束对网络进行微调,迭代优化后输出估计的三维人群数据,实现大规模场景三维人群数据生成。
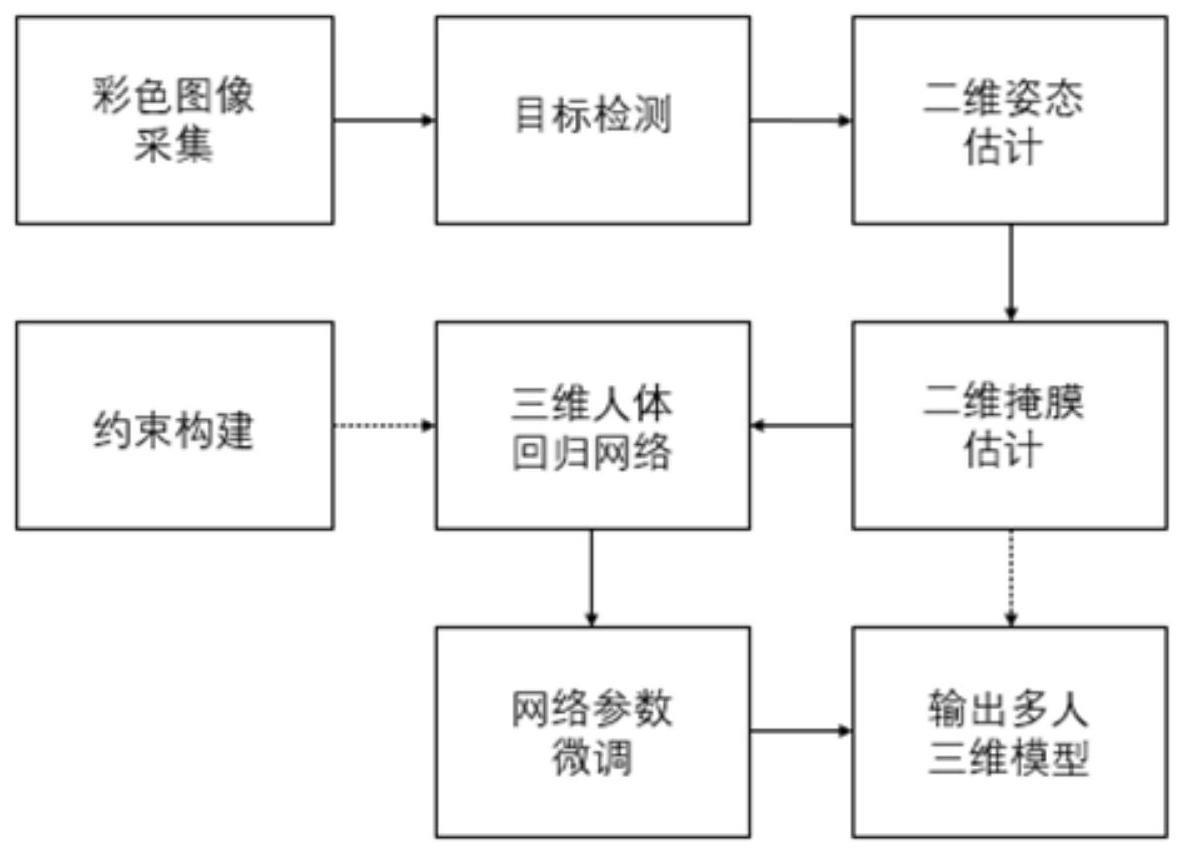
2、技术方案:本发明所述的基于单视角彩色图像的三维人群数据生成方法,包括以下步骤:
3、s1.基于现有三维人体数据合成虚拟训练数据:设计一个大型场景,基于该大型场景随机采样人群位置,基于现有数据集中的三维人体数据生成三维蒙皮人体模型并放置于采样位置,通过随机采样相机位置以及改变相机姿态角将三维蒙皮人体模型的关节点投影至二维图像平面获取人体二维关节点,根据二维关节点计算得到人体边界框,实现虚拟训练数据的合成过程;
4、s2.基于虚拟数据训练三维人体回归网络:步骤s1中合成的虚拟训练数据将用于训练三维人体回归网络,三维人体回归网络以端到端的方式进行训练,将虚拟训练数据中的人体边界框、人体二维关节点和二维掩膜输入三维人体回归网络,回归得到估计的三维人体模型参数,通过重投影误差、人体模型参数误差、人体3d关节位置误差、人群位置关系构建约束项,实现三维人体回归网络的训练;
5、s3.单视角人群彩色图像采集:采用从两种方法来采集单视角人群彩色图像,一是截取互联网中的单视角人群视频片段,二是选择现有大场景人群数据集中的合适图片;
6、s4.人体二维特征估计:使用现有开源目标检测,二维姿态估计和掩膜分割方法获取步骤s3中采集的单视角人群彩色图像中的估计人体边界框,估计人体二维关节点和估计二维掩膜;
7、s5.三维人群数据生成:利用步骤s4中获得的人体二维掩膜构建人体遮挡关系约束及正则项,与重投影误差、人群位置关系组成损失函数,在每张步骤s3中采集的单视角人群彩色图像上对三维人体回归网络进行微调,输出估计的三维人体模型参数。
8、进一步地,步骤s1的具体方法包括:
9、s11:虚拟场景设计:设计一个虚拟的大型场景,场景尺寸范围为x∈[-x0,x0],y∈[-x1,x1],z∈[x2,x2],其中x、y、z分别表示场景在不同坐标轴上的范围,x0、x1、x2分别表示具体的坐标数值,并通过相机视角的变化来增加场景视图的多样性,将相机姿态角中的俯仰角范围约束为pa∈[p0°,p1°],pa表示俯仰角范围,p0表示俯仰角角度下限,p1表示俯仰角角度上限,翻滚角范围约束为ra∈[r0°,r1°|,ra表示翻滚角范围,r0表示翻滚角角度下限,r1表示翻滚角角度上限,偏航角范围约束为ya∈[y0°,y1°],ya表示偏航角范围,y0表示偏航角角度下限,y1表示偏航角角度上限;
10、s12:单人三维蒙皮人体模型采样与位置生成:在步骤s11设计的虚拟场景中随机采样50至250个位置,从现有数据集中采集三维人体模型参数,其中包含10个代表人体体型的β参数及72个表示人体关节轴角的θ参数,基于三维人体模型参数生成三维蒙皮人体模型,并放置于采样位置;
11、s13:投影视角生成:根据人群位置的中心以及步骤s11中限定的相机姿态角范围采样相机位置,选取的视场角γ°计算相机焦距,由相机位置和相机焦距构建相机参数;
12、s14:虚拟三维数据生成:利用变换矩阵基于步骤s12中获取的三维蒙皮人体模型生成三维关节点位置,利用步骤s13获得的相机参数将三维关节投影至二维图像平面得到人体二维关节点,并将三维蒙皮人体模型依据相机参数渲染到二维平面构成合成图像,由此获得的人体三维关节点、人体二维关节点、合成图像以及步骤s12中得到的三维人体模型参数、采样位置以及步骤s13中获得的相机参数共同构成了训练所需的虚拟三维数据。
13、进一步地,步骤s2的具体方法包括:
14、s21:三维人体回归网络构建:基于单人人体回归网络构建骨干网络,充分利用步骤s1中构建的虚拟训练数据集进行训练,将虚拟训练数据集中的人体边界框和人体二维姿态作为输入,基于hrnet网络提取人体特征用于回归三维人体模型参数和相机参数[fc,tx,ty],fc表示相机焦距,tx表示相机主点在x方向的偏移,ty表示相机主点在y方向的偏移,基于回归的相机参数转换得到人体绝对位移:
15、
16、其中人体绝对位移t=[tx,ty,tz],tx,ty,tz分别表示人体绝对位移在x,y,z方向上的具体数值,(cx,cy)为边界框在原始图像中的位置,d为边界框大小,f为步骤s13中获取的相机焦距,基于回归得到的三维人体模型参数生成三维蒙皮人体模型,利用变换矩阵将三维蒙皮人体模型转换为人体三维关节点;
17、s22:三维人体约束构建:三维人体约束共包含四项,第一项重投影误差约束lreproj:
18、
19、其中n表示人体总数,n表示第n个人体,π表示基于步骤s13获取的相机参数进行投影操作,表示三维人体回归网络估计的人体三维关节,tn表示步骤三维人体回归网络估计的人体绝对位移,表示步骤s14中得到的人体二维关节点位置;
20、第二项用于监督步骤s21估计的三维人体模型参数约束lsmpl:
21、
22、其中βn,θn代表三维人体回归网络估计的三维人体模型参数,代表步骤s12采集的三维人体模型参数;
23、第三项用以约束步骤s21中估计的人体三维关节点位置约束ljoint:
24、
25、其中为三维人体回归网络估计的人体三维关节点位置,为s14中生成的人体三维关节点位置;
26、第四项利用人群特征约束人体空间位置约束lcrowd:
27、lcrowd=std(jroot·l)
28、其中std(·)表示取标准差,jroot∈rn×3表示图像中所有人体三维关节点中的根关节点位置,·表示作点乘运算,l表示人群法向量方向:
29、
30、其中表示三维人体回归网络估计的人体三维关节点中头部关节点的位置,表示三维人体回归网络估计的人体三维关节点中两脚踝关节点的中点;
31、s23:三维人体回归网络训练:步骤s21构建的三维人体回归网络以端到端的方式进行训练,通过以下损失函数进行约束直至网络收敛:
32、l=λ1lreproj+λ2lsmpl+λ3ljoint+λ4lcrowd
33、其中λ1,λ2,λ3,λ4为损失权重。
34、进一步地,步骤s5的具体方法包括:
35、s51:三维人体模型参数初始估计:将步骤s4获取的估计人体边界框和估计人体二维关节点作为输入,基于步骤s23训练得到的三维人体回归网络直接估计三维人体模型参数和相机参数[fc,tx,ty],基于回归的相机参数转换得到人体绝对位移t,转换公式与步骤s21相同,对于标定图像,公式中相机焦距f为标定值,对于未标定图像,公式中相机焦距f由原始图像对角线长度作为近似值;
36、s52:微调网络参数:针对步骤s3中获取的每张图像利用下述约束对网络参数进行微调:
37、lpseudo=lreproj_pred+lcrowd+ldepth+lprior
38、其中,lpseudo为网络微调过程的整体约束,ldepth为遮挡关系约束损失函数,lprior为正则项,lreproj_pred为利用估计得到的人体二维关节点构建的重投影误差:
39、
40、其中π表示基于步骤s51中的焦距f和步骤s3获取图像的长宽尺寸构建的相机内参进行的投影操作,和tn分别表示三维人体回归网络获取的人体三维关节和估计的人体绝对位移,表示步骤s14中得到的估计人体二维关节点位置;
41、lcrowd与步骤s22中的构建方式完全相同;
42、遮挡关系约束通过考虑人体深度排序过程中的误差来构建损失函数,并通过一个可微的深度渲染器来惩罚人群间不一致的深度顺序,损失函数如下:
43、
44、其中y(u),分别表示在像素点u处的人体深度顺序的真值与预测值,其中深度顺序真值通过步骤s4中预测的二维掩膜得到,dy(u)(u)第y(u)人在u处的绝对深度,s表示具有错误深度排序结果的图片集;
45、正则项通过约束三维人体回归网络估计的结果和步骤s51中获取的初始估计结果的差异来防止过拟合:
46、
47、其中表示通过步骤s51获取的三维人体模型参数,在此损失约束下针对每张图像微调网络参数,即可得到最终所需的三维人体数据;
48、在以上约束下迭代多次后,取出最后一次三维人体回归网络输出的结果作为最终的三维人体数据。
49、有益效果:与现有技术相比,本发明的有益效果为:1.本发明所提出的基于现有数据集合成三维人群虚拟数据的方法有效解决了缺乏大场景三维人群训练数据的问题,同时此种获得数据的方法具有高效、低成本的特点。2.本发明提出的合成虚拟数据的方法可以充分利用现有的常规人群场景的数据集,训练数据的多样性有效提升了模型的泛化性能。3.本发明利用人群特征约束个体信息解决深度歧义性以及人群交互遮挡问题,有效提高了最终生成的三维人群数据的精度。4.本发明仅依赖单一视角彩色图片即可实现人群三维数据的生成,生成成本低,便于应用。
- 还没有人留言评论。精彩留言会获得点赞!