多智能体系统分块策略评估方法及装置
本发明属于多智能体系统强化学习,尤其涉及多智能体系统分块策略评估方法及装置。
背景技术:
1、策略评估一直是多智能体强化学习中长期存在的挑战,阻碍多智能体评估算法发展的原因主要有两个。首先,当考虑大量智能体存在时,联合策略空间的大小呈指数爆炸;其次,智能体潜在的博弈动态中可能会表现出循环行为,难以给出适当的评估结果。在这样的前提下,传统的多智能体评估算法如elo、trueskill等无法给出能够体现策略循环现象的解。ying wen等人将纳什均衡的概念被引入到多智能体的评估之中,虽然可以在一定程度上体现策略间的循环,但由于多智能体博弈往往会收敛于极限环,使得其求解方法有着很高的计算复杂度。
2、2019年提出的α-rank方法采用了马尔可夫康利链来强调博弈动力学中循环的存在,并使用了种群的概念和复制器动力学作为策略转移的依据,通过计算策略间状态转移矩阵的平稳分布来得到联合策略的排名。但是α-rank作为一种可以很好的描述策略间循环转移的评估方法,也存在着一定的局限性。为了得到联合策略之间的状态转移矩阵,需要先行计算出包含每一种策略组合收益的收益矩阵,随着多智能体系统的复杂化,将策略与环境交互得到收益矩阵在有限时间上是不可实现的。
3、为了减少策略与环境交互的次数,近年来提出了许多种针对α-rank的改进。αα-rank使用了一种双随机优化机制来减少计算策略排名所需要的计算资源,首先,在策略间状态转移矩阵计算平稳分布的过程中引入了随机梯度下降方法来得到一个关于稳态分布的近似解,其次,采用了随机抽样的方法将博弈分解为多个子博弈,并使用oracle机制对子博弈中智能体的策略进行扩充,以此来减小每一次所需策略和环境所需交互的次数。但αα-rank方法只适用于智能体数量较少的场合,在智能体数量较多的场景中仍然无法解决高复杂的问题。opteval方法基于多智能体博弈后收益矩阵的低秩属性,通过对随机选择采样的不完整收益矩阵使用矩阵补全算法实现了对完整收益矩阵的还原,并以此得到了策略排名的近似解,但受到矩阵补全算法的限制,该评估方法只适用于两智能体博弈的场景中。
4、david biagioni等人构建了一系列由多个智能楼宇构成的电网环境,但在该类场景中多智能体系统仅在策略演化的邻域得到了应用,有多种方法可以给出电网环境下的智能体控制策略,但缺少在策略评估邻域的方法,目前缺少一种可以在电网中智能体数量较多且每个智能体具有多个可用个体策略情况下,给出收敛最优联合策略的技术。因此针对规模较大、智能体数量较多的多智能体系统,需要设计合适算法对联合策略空间进行分块,以实现在较短时间内对所有联合策略进行评估,得到收敛最优策略。
技术实现思路
1、本技术实施例的目的是提供一种多智能体系统分块策略评估方法及装置,以解决相关技术中存在的大规模多智能体策略评估中计算难度大、处理时间长的技术问题。
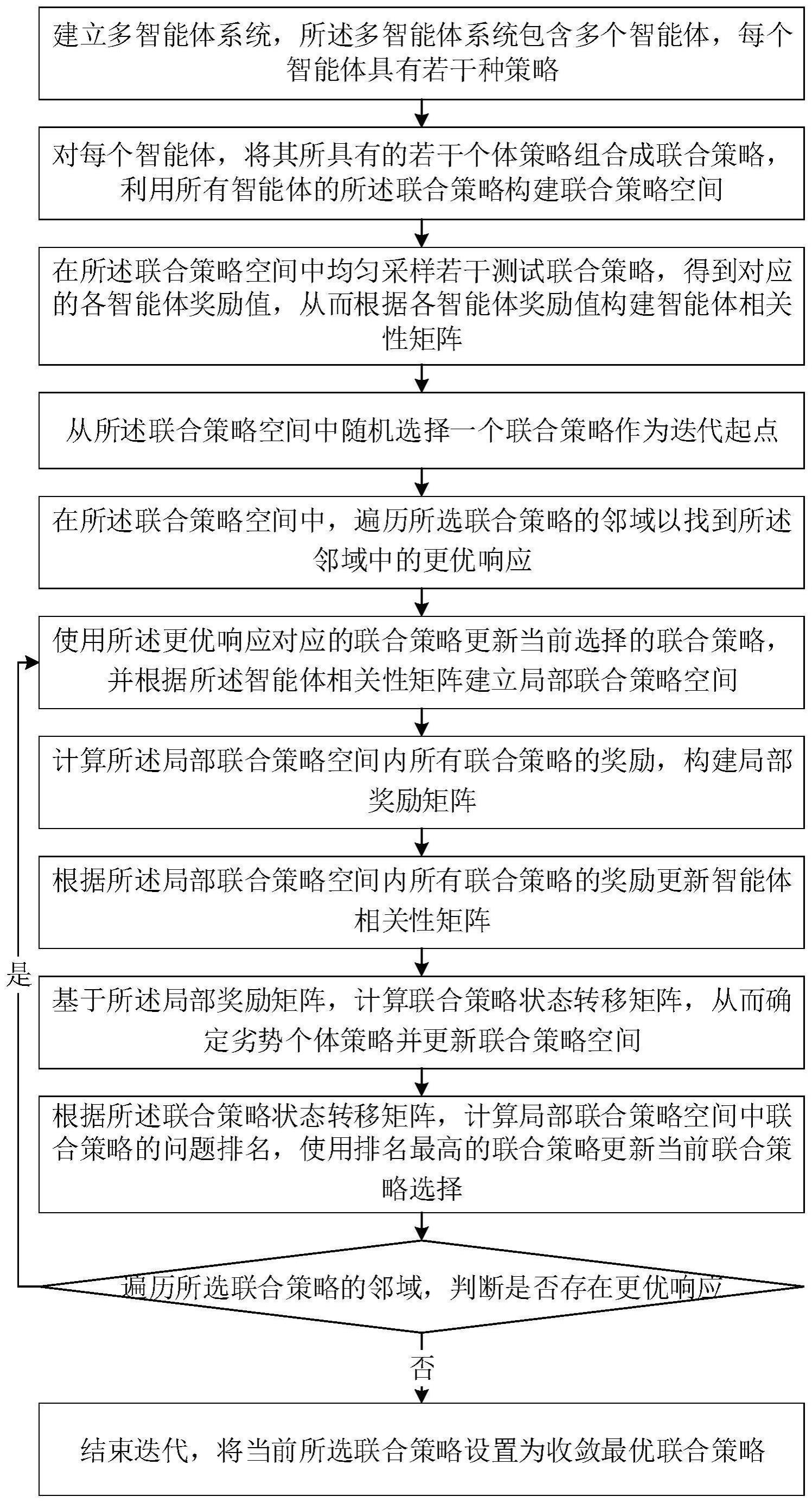
2、根据本技术实施例的第一方面,提供一种多智能体系统分块策略评估方法,包括:
3、s1:建立多智能体系统,所述多智能体系统包含多个智能体,每个智能体具有若干种策略;
4、s2:对每个智能体,将其所具有的若干个体策略组合成联合策略,利用所有智能体的所述联合策略构建联合策略空间;
5、s3:在所述联合策略空间中均匀采样若干测试联合策略,得到对应的各智能体奖励值,从而根据各智能体奖励值构建智能体相关性矩阵;
6、s4:从所述联合策略空间中随机选择一个联合策略作为迭代起点;
7、s5:在所述联合策略空间中,遍历所选联合策略的邻域以找到所述邻域中的更优响应;
8、s6:使用所述更优响应更新当前选择的联合策略,并根据所述智能体相关性矩阵建立局部联合策略空间;
9、s7:计算所述局部联合策略空间内所有联合策略的奖励,构建局部奖励矩阵;
10、s8:根据所述局部联合策略空间内所有联合策略的奖励更新智能体相关性矩阵;
11、s9:基于所述局部奖励矩阵,计算联合策略状态转移矩阵,从而确定劣势个体策略并更新联合策略空间;
12、s10:根据所述联合策略状态转移矩阵,计算局部联合策略空间中联合策略的问题排名,使用排名最高的联合策略更新当前联合策略选择;
13、s11:遍历所选联合策略的邻域,判断是否存在更优响应,若存在则返回步骤s6继续迭代,若不存在则结束迭代,将当前所选联合策略设置为收敛最优联合策略。
14、进一步地,在所述联合策略空间中均匀采样若干测试联合策略,得到对应的各智能体奖励值,从而根据各智能体奖励值构建智能体相关性矩阵,包括:
15、在所述联合策略空间中均匀采样若干测试联合策略,将各测试联合策略与测试环境交互,得到各个测试联合策略的奖励值;
16、根据所述各个测试联合策略的奖励值,为每个智能体建立关于测试联合策略选择的第一奖励序列;
17、将智能体两两组合,计算两个智能体的第一奖励序列之间的第一皮尔逊相关性系数,并依据所述第一皮尔逊相关性系数建立智能体相关性矩阵。
18、进一步地,所选联合策略的邻域为所选联合策略的所有相邻联合策略的集合,所选联合策略的相邻联合策略为与所选联合策略相比只有一个智能体的策略发生变化的联合策略。
19、进一步地,对于所选联合策略的更优响应,策略发生变化的智能体在更优响应中的奖励值高于在所选联合策略中的奖励值。
20、进一步地,使用所述更优响应更新当前选择的联合策略,并根据所述智能体相关性矩阵建立局部联合策略空间,包括:
21、确定更优响应与当前选择的联合策略相比改变了个体策略的智能体,将该智能体作为局部评估的中心智能体;
22、将更优响应作为新的当前选择联合策略;
23、根据智能体相关性矩阵,确定与中心智能体的相关性大于相关性阈值的强相关智能体;
24、根据中心智能体及其强相关智能体的所有策略和其他智能体在当前选择联合策略中的策略,建立局部联合策略空间。
25、进一步地,根据所述局部联合策略空间内所有联合策略的奖励更新智能体相关性矩阵,包括:
26、使用新的联合策略奖励值为每个智能体建立关于联合策略选择的第二奖励序列;
27、将智能体两两组合,根据所述第二奖励序列计算智能体奖励序列之间的第二皮尔逊相关性系数;
28、根据所述第一皮尔逊相关性系数和第二皮尔逊相关性系数更新智能体相关性矩阵。
29、进一步地,基于所述局部奖励矩阵,计算联合策略状态转移矩阵,从而确定劣势个体策略并更新联合策略空间,包括:
30、根据局部奖励矩阵,得到每两个相邻联合策略之间的个体策略发生变化的智能体对应的奖励差;
31、基于智能体的奖励差,计算联合策略之间的状态转移概率,从而建立联合策略状态转移矩阵;
32、获取联合策略状态转移矩阵中各个策略向外转移的次数,若策略的向外转移次数大于阈值,则判定其为劣势个体策略;
33、将所有包含劣势个体策略的联合策略从所述联合策略空间中移除,从而更新联合策略空间。
34、根据本技术实施例的第二方面,提供一种多智能体系统分块策略评估装置,包括:
35、建立模块,用于建立多智能体系统,所述多智能体系统包含多个智能体,每个智能体具有若干种策略;
36、第一构建模块,用于对每个智能体,将其所具有的若干个体策略组合成联合策略,利用所有智能体的所述联合策略构建联合策略空间;
37、采样模块,用于在所述联合策略空间中均匀采样若干测试联合策略,得到对应的各智能体奖励值,从而根据各智能体奖励值构建智能体相关性矩阵;
38、选择模块,用于从所述联合策略空间中随机选择一个联合策略作为迭代起点;
39、遍历模块,用于在所述联合策略空间中,遍历所选联合策略的邻域以找到所述邻域中的更优响应;
40、第一更新模块,用于使用所述更优响应更新当前选择的联合策略,并根据所述智能体相关性矩阵建立局部联合策略空间;
41、第二构建模块,用于计算所述局部联合策略空间内所有联合策略的奖励,构建局部奖励矩阵;
42、第二更新模块,用于根据所述局部联合策略空间内所有联合策略的奖励更新智能体相关性矩阵;
43、第一计算模块,用于基于所述局部奖励矩阵,计算联合策略状态转移矩阵,从而确定劣势个体策略并更新联合策略空间;
44、第二计算模块,用于根据所述联合策略状态转移矩阵,计算局部联合策略空间中联合策略的问题排名,使用排名最高的联合策略更新当前联合策略选择;
45、迭代模块,用于遍历所选联合策略的邻域,判断是否存在更优响应,若存在则返回第一更新模块继续迭代,若不存在则结束迭代,将当前所选联合策略,作为收敛最优联合策略。
46、根据本技术实施例的第三方面,提供一种电子设备,包括:
47、一个或多个处理器;
48、存储器,用于存储一个或多个程序;
49、当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如第一方面所述的方法。
50、根据本技术实施例的第四方面,提供一种计算机可读存储介质,其上存储有计算机指令,该指令被处理器执行时实现如第一方面所述方法的步骤。
51、本技术的实施例提供的技术方案可以包括以下有益效果:
52、由上述实施例可知,本技术采用皮尔逊相关性系数,将联合策略空间中采样得到的奖励只作为输入,计算了智能体之间的相关性,构建了智能体相关性矩阵,并基于相关性矩阵实现了对大规模评估问题的分块评估,减少了评估所需的计算量和时间;采用基于局部评估的结果,根据联合策略向其他策略转移的次数的统计结果,判断劣势个体策略并将其移除,实现了动态更新待评估策略空间,在迭代过程中减少待评估策略数量。具体地,在由智能楼宇构成的电网环境中,本技术可以通过选择合适的智能楼宇用电、发电策略,在保证各个智能楼宇收益相对均衡的前提下,优化太阳能发电系统在电网中的使用,降低系统中各个节点的电压波动,提升电网的稳定性。
53、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
- 还没有人留言评论。精彩留言会获得点赞!