一种基于虚拟空间的广告投放策略学习方法与流程
本发明涉及虚拟化,为一种基于虚拟空间的广告投放策略学习方法。
背景技术:
1、近年来,新冠病毒的爆发迅速成为所有人关注的焦点新闻。人们持续探讨、刷新疫情进展的新闻,甚至担心将来会是怎样的演变与发展。总之,在客观存在的病毒之外,也同样有这样一种病毒式的时刻,它与信息的极速广泛传播相关,也与随之而来的主观意识相关。上述这个事实把我们再次带到一个相似的情况,病毒疫情中在人群中不断地传播,非常相似于互联网中某个热点内容的爆红,比如:一条推特上的推文、油管上的一个视频、一条品牌的标语,一种模因、instagram或者脸书的一条发布信息,等等诸如此类。给这种火遍全网的内容贴上一个形容词标签—“病毒式的爆发”,这并非偶然,而是存在其一定的流行病学背景。“模因(meme,又称媒因)”,是指一个想法、行为或风格从一个人到另一个人的传播过程。因此,了解调节病毒传播与网络爆红现象两种现象的共同机制,就变得十分有趣,而在此探究过程之中,人工智能技术与数学分析是十分重要的工具。
2、许多学者已经研究出一些有用的数学模型,来描述和预测这种流行现象传播的趋势与动向。最主要是通过一种统计学分析,通过计算大规模收集而来的相关传染进展的数据,对相应机制提出假设,然后再通过后续观察,对其进行确认、完善或修改。尤其值得说明的是,一个好的模型必须能以较好减小模型估计值与实际值之间的差距,也叫作误差,而人工智能算法运用梯度下降等方法使模型能够很好的降低预测值与真实值之间的误差,目前人工智能在人脸识别,物体识别等领域的精确度可达90%以上,在我们的生活中有着十分广泛的应用。
3、除了构建数学模型以外,对热点内容的传播的预测和分析还有一个重要的问题是,预测模型往往与真实世界的存在较大的差异,在理想化环境中训练出来的模型往往不能很好的应用于真实世界,存在着较大的泛化误差。为了解决这个问题,业界提出了许多的方法,目前在工业界和学术界被广泛应用的是基于真实世界构建1:1的数字实体,也就是数字孪生(digital twin,dt)技术,数字孪生最早由美国国防部提出,用于航空航天飞行器的健康维护与保障,是真实物理世界的数字化表示,数字孪生可用于模拟真实世界的运行状态,预测未来的设备运行规律,这些模拟和实验在现实生活中往往需要很高的部署和试错成本,从而实现低成本的设备维护和预测。近年来数字孪生广泛的应用于工程模拟,智能城市,车辆网等应用场景,如模拟飞机飞行状态,提前规划道路中车流量变化。在该数字孪生中进行模拟与训练,并将优化的模型直接用于真实的世界,能够显著的提升训练和预测的效率,并大大减小模拟的成本。
4、近年来很火的元宇宙技术,它可以看成是数字孪生的进化版,元宇宙得益于目前5g甚至未来6g高速网络和强大的计算能力和人工智能技术的支撑,不仅仅是对单个物体进行广泛模型,元宇宙将实现对整个真实的世界实时的模拟,包括人,机器,物体,甚至是天气,声音等一切,是现实世界实时的数字版本。因此,现实生活中的场景和都能在元宇宙中进行提前模拟和展示,并通过ai能力进行最优化,最后将优化后的策略下发回真实世界进行实施,并且由于5g和6g网络支持,这个交互过程将是实时和同步的。
技术实现思路
1、为了实现以上的技术效果,本技术基于人工智能算法和元宇宙的品牌宣传和广告传播模型,通过人工智能进行策略优化,针对用户,广告投放时长、投放位置等,期望投入成本因素等,以寻找最优的宣传策略和用户满意度,并将优化后的策略映射到真实世界,降低了在现实生活中不断部署和试错的成本。
2、为了达到上述目的,本技术实施例采用的技术方案如下:
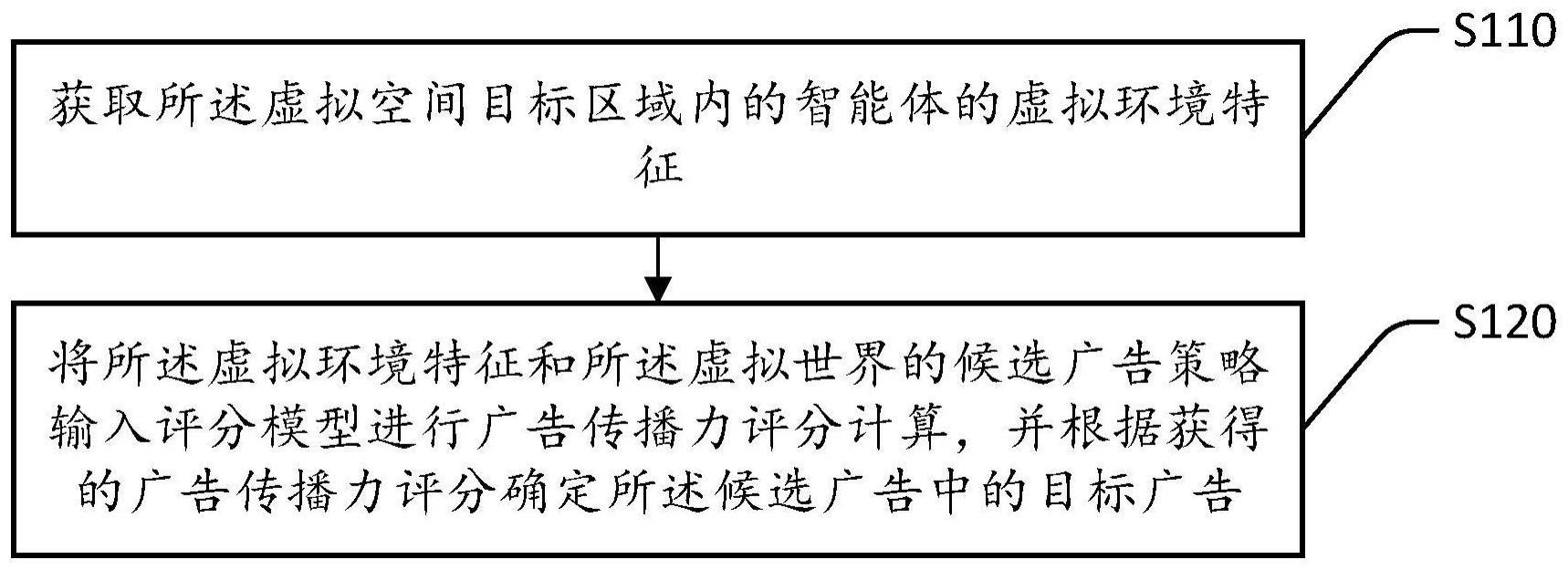
3、第一方面,一种基于虚拟空间的广告投放策略学习方法,应用于服务器,所述方法布置于虚拟空间,所述虚拟空间为元宇宙,所述方法包括:获取所述虚拟空间目标区域内的智能体的虚拟环境特征,所述虚拟环境特征包括环境要素和所述智能体的虚拟用户状态;将所述虚拟环境特征和所述虚拟世界的候选广告输入评分模型进行广告评分计算,并根据获得的广告评分确定所述候选广告中的目标候选广告。
4、进一步的,所述评分模型包括:基于深度强化学习算法构建的强化学习模型;其中,所述深度强化学习模型的模型训练过程中的输入包括:作为训练样本的目标区域内虚拟用户的数量,虚拟用户距离广告的位置,用户采用相应动作的概率,以及运营商期望投入的广告成本进行向量化处理和向量拼接获得的虚拟环境特征。
5、进一步的,所述深度强化学习模型的基础架构为actor-critic网络架构,包括动作网络和评估网络。
6、进一步的,所述方法包括将所述虚拟环境特征输入到所述评估网络和所述动作网络得到基于虚拟环境的广告策略投放动作所对应的及时奖励,并将所述即时奖励形成历史经验;基于所述历史经验进行学习,并基于损失函数更新动作网络。
7、进一步的,所述历史经验的获取具体包括:将所述虚拟环境特征输入到所述评估网络和所述动作网络进行策略学习得到初步策略,所述动作网络将根据所述初步策略和进行动作选取,所述动作用于表征当前广告策略投放的动作,所述动作作用于虚拟环境转移至下一状态并输出所述动作的即时奖励并形成为历史经验。
8、进一步的,所述历史经验存储于经验回放池中。
9、进一步的,基于所述历史经验进行学习,并基于损失函数更新动作网络,包括:评估网络随机抽取回放池中的所述历史经验进行学习,并基于所述损失函数更新动作网络。
10、进一步的,所述损失函数为:
11、
12、其中,ψattention为注意力因子,ψinterest为行为因子,ψsearch为搜索因子,ωaction为行为函数,γshare为分享函数。
13、进一步的,所述行为函数如下所示:
14、
15、其中,sunpurchased用于表征用户感兴趣行为,spurchased用于表征用户实际购买行为,m为当前[0,t]时间段内该广告内容引起受众注意的用户数。
16、进一步的,所述分享函数如下所示:
17、
18、其中,s用于表征用于将内容与其他亲友分享的动作次数,包括社交媒体中的转发、分享行为smedia,还包括实际生活中的面对面分享行为sface;其中α和β为转发行为和分享行为的权重,其中α+β=1;sunpurch用于表征未购买分享的比例,spurch用于表征购买后分享的比例。
19、第二方面,提供一种电子设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述任意一项所述的广告投放策略学习方法。
20、第三方面,提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述任意一项所述的方法。
21、本技术实施例提供的技术方案中,利用深度强化学习方法并结合元宇宙等虚拟化技术,实现在虚拟空间中的广告传播模型构建和策略学习,深度强化学习技术能够根据当前环境学习出最优策略,基于元宇宙的学习能够提高模型训练的效率和策略泛化能力,尤其对于信息不互通的、难以在现实模拟和观测的生活和工业场景,本发明取得的有益效果更为突出。
- 还没有人留言评论。精彩留言会获得点赞!