一种基于高分辨率网络与边界增强的MRI图像分割方法
本发明属于图像分割,涉及一种基于高分辨率网络与边界增强的mri图像分割方法。
背景技术:
1、深度学习是机器学习领域中一系列试图使用多重非线性变换对数据进行多层抽象的算法,不仅学习输入和输出之间的非线性映射,还学习输入数据向量的隐藏结构,以用来对新的样本进行智能识别或预测。随着深度学习的发展,深度学习方法开始展示其在图像处理任务中的强大能力。深度学习方法的潜力使其成为图像分割的主要选择,尤其是医学图像分割。近几年,基于深度学习技术的图像分割受到了广泛的关注,深度学习在医学图像分割方面的突破对于医学领域的发展至关重要。
2、主流分割方法大多基于fcn架构,该架构中编码器逐渐降低空间分辨率,以获得更大的感受野,从而学习更多高层语义信息。而对于分割这样的密集任务而言,分辨率的降低势必会造成信息的丢失,从而影响分割的效果。体现在脑肿瘤图像分割任务就是,由于神经胶质瘤的类内具有多变的形状、位置和规律性,对于一些体积过小的增强肿瘤将会随着模型的分辨率降低而被遗漏,从而在分割性能上有所降低。另一方面,新型的网络架构transformer在分割领域展现出很强的竞争力,因其天然自带的长距离特性,该模型可以在不降低分辨率的情况下捕获全局视野,因此,该模型有望解决分辨率降低带来的信息丢失问题。部分学者引入transformer作为主干网络,然而,该网络存在参数量大、模型难以训练等问题,因此主流的做法有两种,1)切块(patch),vit模型的patch大小为16×16,这无疑也是一种分辨率的降低。2)局部自注意力(local selfattention),swin transformer模型采用局部自注意力加上块合并(patch merging)的分层方案,该方案也是一种逐层降低分辨率的做法。如何提出一个新的方案,尽可能的保留原分辨率完成分割任务是解决信息丢失的关键。
3、现有的脑肿瘤mri图像分割方法主要以深度学习模型为基础,而基于深度学习的脑肿瘤图像分割任务面临着两个问题:1)医学图像分割通常采用u-net网络作为主干网络,该模型采用卷积神经网络(convolutional neural networks,cnn)作为编码器,由于cnn的conv算子感受野比较局限,为了扩大网络的关注区域,需要堆叠多层(卷积-池化),这会带来分辨率的降低,从而导致信息的丢失;2)因为肿瘤通常被健康的脑组织包围,例如脑脊液、灰质、白质等,导致肿瘤边界模糊,使得基于深度学习技术的方法对于边界区域难以区分。
技术实现思路
1、为实现上述目的,本发明提供一种基于高分辨率网络与边界增强的mri图像分割方法,解决了现有脑肿瘤mri图像分割时分辨率降低以及边界区域难以区分的问题。
2、本发明所采用的技术方案是,一种基于高分辨率网络与边界增强的mri图像分割方法,包括以下步骤:
3、步骤s1、对于需要进行分割的mri图像,进行预处理操作;
4、步骤s2、预处理后的图像数据分别输入第一个高分辨率分割网络模型model1和第二个高分辨率分割网络模型model2,两个模型均为基于swin transformer的高分辨率分割网络模型hrswinnet,其中model2采用边界增强方法;
5、所述边界增强方法为基于自适应权重的边界增强学习方法和/或基于知识蒸馏的边界增强学习方法;
6、步骤s3、将model1最终的输出结果output1和model2最终的输出结果output2进行平均运算得到最终分割结果。
7、进一步地,所述步骤s1中预处理包括图像裁剪、重采样和标准化三种方法。
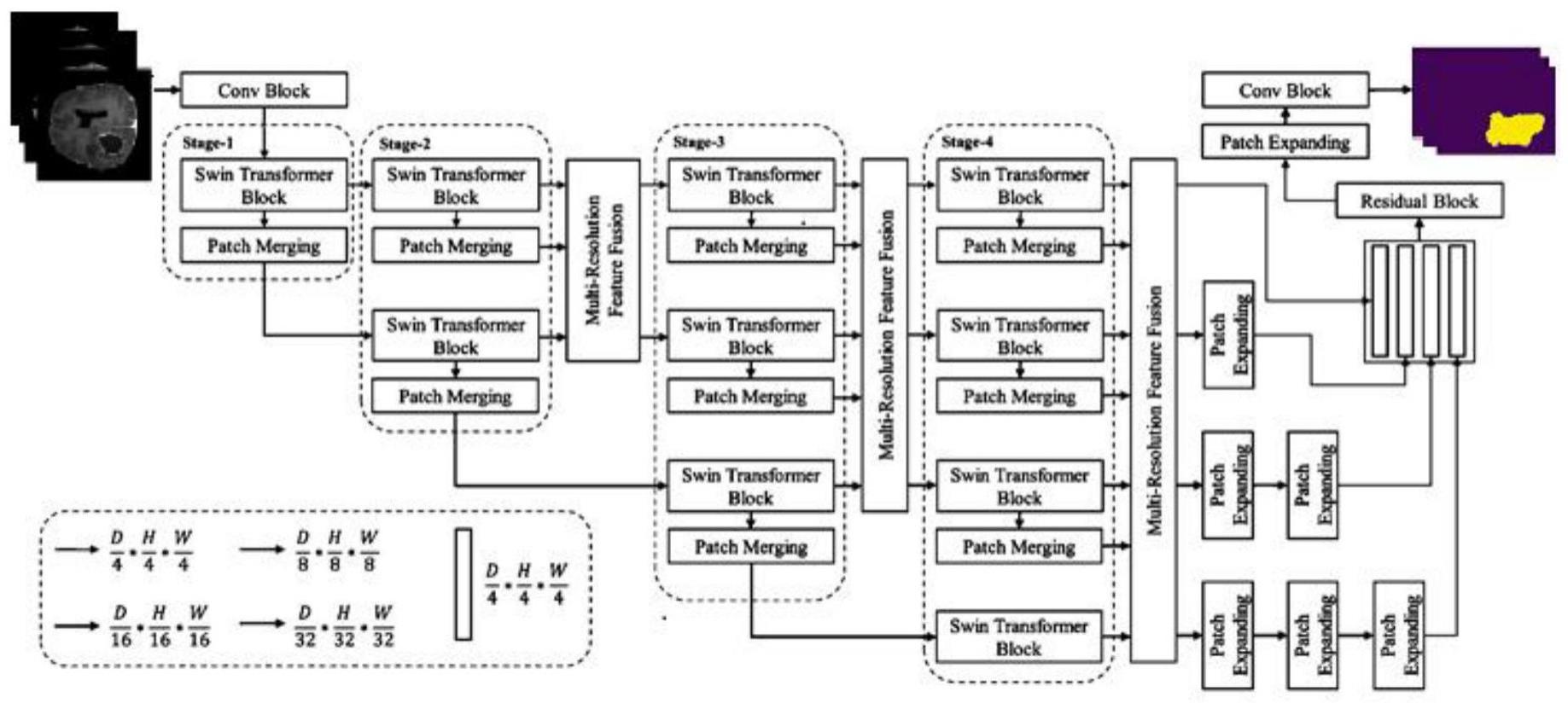
8、进一步地,所述hrswinnet模型包含编码阶段stage,每个stage之间顺序连接,在每个stage之间都有多分辨率特征融合模块mrff插入;除最后一个stage外第n个stage包含n个并行的swin transformer模块和patch merging模块,最后一个stage包含n个并行的swin transformer模块和n-1个patch merging模块;最后一个多分辨率特征融合模块mrff的输出依次与残差模块、patch expanding模块和conv模块相连;其中,patch merging模块和patch expanding模块分别用于对特征图进行下采样、上采样。
9、进一步地,所述swin transformer模块包含两个级联层,第一层基于窗口的多头自注意力模块w-msa,第二层基于移位窗口的多头自注意力模块sw-msa,一个w-msa模块和一个sw-msa模块依次连接;
10、连续的swin transformer模块计算过程如下:
11、
12、
13、
14、
15、公式中,和zl分别代表w–msa模块、mlp模块在l层的输出特征,l-1表示上一层的输出,l+1表示下一层的输出;ln为层归一化,mlp为多层感知机。
16、进一步地,所述hrswinnet模型的损失函数为:
17、
18、其中,i表示图像体素数;j是类别编号;yi,j和gi,j分别表示在体素i处类为j的输出概率、一个one-hot编码的真实值。
19、进一步地,所述步骤s2中基于自适应权重的边界增强学习方法具体为:
20、首先对高分辨率分割网络模型hrswinnet进行常规训练,将训练后的模型记作model1;将训练数据输入model1和待训练模型model2,model1的输出结果为logits,经过softmax(logits)得到概率值prob,计算prob和真实值target的交叉熵c=crossentropy(output,target),之后将c的值经过sigmoid函数,将其映射到(0,δ)之间,此时获取的值为要对model2加权的权重w值,采用权重w对model2进行加权,得到增强后的模型model2;
21、所述model2训练过程中计算损失的时候通过与权重w计算内积,最终结果即为加权之后的损失。
22、进一步地,所述步骤s2中基于知识蒸馏的边界增强学习方法具体为:
23、首先对高分辨率分割网络模型hrswinnet进行常规训练,将训练后的模型记作model1;训练数据同时进入model1和待训练模型model2,model1的输出结果为logits1,随后对logits1做softmax操作,得到一个像素点的四维向量,向量的每一个方向的长度就代表所述像素点是其对应类别的概率;对四维向量各个方向的值计算方差variance,variance越大,位于边界区域的概率越大;将方差值variance小于超参数v的点的硬标签值替换为软标签,将model2与新的软标签target2计算损失,从而获得一个更强的分割模型model2。
24、本发明的有益效果是:
25、1)本发明提出的基于swin transformer的高分辨率复合网络将做到真正的高分辨率,从而在脑肿瘤图像分割任务性能上有所提升。
26、2)本发明分割方法的边界区分能力强,模型训练简单,模型精度高。
- 还没有人留言评论。精彩留言会获得点赞!