风格化人脸驱动方法和设备、模型构建及训练方法和装置与流程
本公开涉及虚拟/增强现实,尤其涉及虚拟数字人,特别涉及一种风格化人脸驱动方法和设备、模型构建及训练方法和装置。
背景技术:
1、相关技术人脸卡通化技术主要是通过的方法对人脸进行风格迁移,基本都能够达到比较明显的风格化效果,如jojogan。
2、相关技术可以实现人脸驱动方法有fomm、mgcnet、deca、nerface等,其中,fomm是基于大量的网络采访视频学习人脸的位姿与表情,deca则是基于人脸模型学习表情和位姿。
技术实现思路
1、发明人通过研究发现:相关技术只能两阶段来实现风格化人脸驱动任务,可以划分为两种:一、先风格化再驱动;二、先驱动再风格化。相关技术无法同时很好地完成人脸风格化和人脸驱动这两个任务。相关技术通过两阶段将人脸风格化和人脸驱动结合到一起会产生3d不一致性。
2、鉴于以上技术问题中的至少一项,本公开提供了一种风格化人脸驱动方法和设备、模型构建及训练方法和装置,可以同时实现人脸风格化和人脸驱动这两个任务。
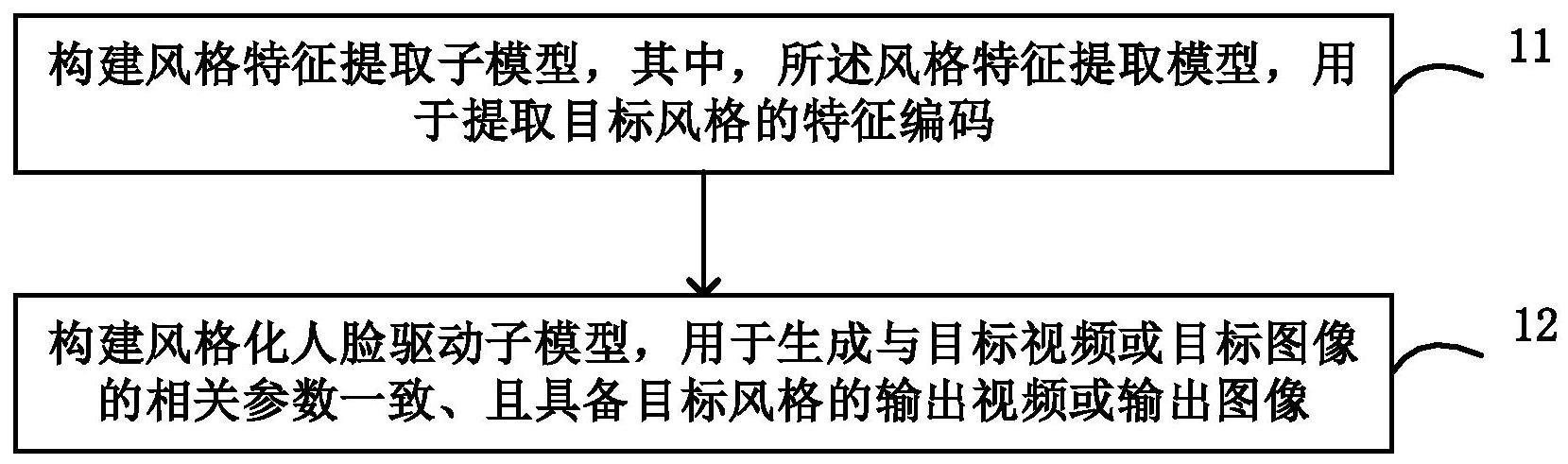
3、根据本公开的一个方面,提供一种风格化人脸驱动模型构建方法,包括:
4、构建风格特征提取子模型,其中,所述风格特征提取模型,用于提取目标风格的特征编码;
5、构建风格化人脸驱动子模型,其中,所述风格化人脸驱动子模型,用于根据目标视频或目标图像的相关参数、目标风格的特征编码,生成与目标视频或目标图像的相关参数一致、且具备目标风格的输出视频或输出图像,相关参数包括人脸位置和表情参数。
6、在本公开的一些实施例中,所述风格化人脸驱动模型包括所述风格特征提取子模型和所述风格化人脸驱动子模型。
7、在本公开的一些实施例中,所述构建风格化人脸驱动子模型包括:
8、构建光线体积密度确定分模型,其中,所述光线体积密度确定分模型,用于根据目标视频或目标图像的相关参数,确定目标视频或目标图像的三维点坐标的光线体积密度;
9、构建颜色确定分模型,其中,所述颜色确定分模型,用于根据目标视频或目标图像的相关参数,以及风格特征提取模型提供的目标风格的特征编码,确定三维点坐标的颜色;
10、构建风格化人脸驱动分模型,其中,所述风格化人脸驱动分模型,用于根据三维点坐标的光线体积密度和颜色,生成与目标视频或目标图像的相关参数一致、且具备目标风格的输出视频或输出图像。
11、在本公开的一些实施例中,所述风格化人脸驱动子模型包括所述光线体积密度确定分模型、所述颜色确定分模型和所述风格化人脸驱动分模型。
12、在本公开的一些实施例中,所述风格化人脸驱动模型构建方法还包括:
13、构建预处理子模型,其中,所述预处理子模型,用于从目标视频或目标图像中提取相关参数,并将目标视频或目标图像由二维像素坐标转换为三维点坐标;所述光线体积密度确定分模块,用于根据目标视频或目标图像的相关参数、可学习表情参数和目标视频或目标图像的三维点坐标,确定目标视频或目标图像的三维点坐标的光线体积密度,所述相关参数还包括相机内参。
14、在本公开的一些实施例中,所述风格化人脸驱动模型还包括所述预处理子模型。
15、根据本公开的另一方面,提供一种风格化人脸驱动模型训练方法,包括:
16、采用目标视频或目标图像、和目标风格的特征编码对风格化人脸驱动模型进行训练,使得训练完成的风格化人脸驱动模型用于生成与目标视频或目标图像的相关参数一致、且具备目标风格的输出视频或输出图像,其中,所述风格化人脸驱动模型为根据如上述任一实施例所述的风格化人脸驱动模型构建方法构建的风格化人脸驱动模型。
17、在本公开的一些实施例中,所述采用目标视频或目标图像、和目标风格的特征编码对风格化人脸驱动模型进行训练包括:
18、采用多种目标风格的特征编码以及原始风格的特征编码,对风格化人脸驱动模型进行训练,其中,所述原始风格为目标视频或目标图像的风格。
19、在本公开的一些实施例中,所述风格化人脸驱动模型训练方法还包括:
20、采用分层采样的方式对风格化人脸驱动子模型进行训练。
21、在本公开的一些实施例中,所述采用分层采样的方式对风格化人脸驱动子模型进行训练包括:
22、对每个训练帧中采样多个相机光线;
23、沿着每条相机光线,采样第一预定数量的采样像素点作为第一采样网络的输入,其中,所述第一采样网络为第一次输入的风格化人脸驱动子模型;
24、根据第一采样网络的输出调整采样概率,重新采样第二预定数量的采样像素点作为第二采样网络的输入,其中,所述第二采样网络为第二次输入的风格化人脸驱动子模型。
25、在本公开的一些实施例中,所述风格化人脸驱动模型训练方法还包括:
26、确定可学习表情参数的损失函数;
27、确定风格化人脸驱动子模型的损失函数;
28、根据可学习表情参数的损失函数、风格化人脸驱动子模型的损失函数,确定风格化人脸驱动模型的总损失函数;
29、根据风格化人脸驱动模型的总损失函数对风格化人脸驱动模型进行优化。
30、在本公开的一些实施例中,所述确定可学习表情参数的损失函数包括:
31、根据可学习表情参数的数量、每个可学习表情参数,确定可学习表情参数的损失函数。
32、在本公开的一些实施例中,所述确定风格化人脸驱动子模型的损失函数包括:
33、根据图像的采样像素点的在第一采样网络的生成颜色和该图像在该采样像素点的真实颜色,确定第一损失函数,其中,第一损失函数为第一采样网络的损失函数;
34、根据图像的采样像素点的在第二采样网络的生成颜色和该图像在该采样像素点的真实颜色,确定第二损失函数,其中,第二损失函数为第二采样网络的损失函数;
35、根据第一损失函数和第二损失函数确定风格化人脸驱动子模型的损失函数。
36、在本公开的一些实施例中,所述确定风格化人脸驱动子模型的损失函数还包括:
37、根据第一采样网络参数、目标风格的特征编码、训练图像的人脸位置和表情参数、可学习表情参数、采样像素点的三维点坐标,确定该训练图像的采样像素点的在第一采样网络的生成颜色;
38、根据第二采样网络参数、目标风格的特征编码、训练图像的人脸位置和表情参数、可学习表情参数、采样像素点的三维点坐标,确定该训练图像的采样像素点的在第二采样网络的生成颜色。
39、根据本公开的另一方面,提供一种风格化人脸驱动方法,包括:
40、接收输入的目标视频或目标图像、和目标风格的特征编码;
41、采用风格化人脸驱动模型,根据输入的目标视频或目标图像、和目标风格的特征编码,生成与目标视频或目标图像的相关参数一致、且具备目标风格的输出视频或输出图像,其中,所述风格化人脸驱动模型为根据如上述任一实施例所述的风格化人脸驱动模型训练方法训练得到的。
42、根据本公开的另一方面,提供一种风格化人脸驱动模型构建装置,包括:
43、第一构建模块,用于构建风格特征提取子模型,其中,所述风格特征提取模型,用于提取目标风格的特征编码;
44、第二构建模块,用于构建风格化人脸驱动子模型,其中,所述风格化人脸驱动子模型,用于根据目标视频或目标图像的相关参数、目标风格的特征编码,生成与目标视频或目标图像的相关参数一致、且具备目标风格的输出视频或输出图像,相关参数包括人脸位置和表情参数。
45、在本公开的一些实施例中,所述风格化人脸驱动模型包括所述风格特征提取子模型和所述风格化人脸驱动子模型。
46、根据本公开的另一方面,提供一种风格化人脸驱动模型训练装置,包括:
47、模型训练模块,用于采用目标视频或目标图像、和目标风格的特征编码对风格化人脸驱动模型进行训练,使得训练完成的风格化人脸驱动模型用于生成与目标视频或目标图像的相关参数一致、且具备目标风格的输出视频或输出图像,其中,所述风格化人脸驱动模型为根据如上述任一实施例所述的风格化人脸驱动模型构建方法构建的风格化人脸驱动模型。
48、根据本公开的另一方面,提供一种风格化人脸驱动设备,包括:
49、数据接收模块,用于接收输入的目标视频或目标图像、和目标风格的特征编码;
50、风格化人脸驱动模块,用于采用风格化人脸驱动模型,根据输入的目标视频或目标图像、和目标风格的特征编码,生成与目标视频或目标图像的相关参数一致、且具备目标风格的输出视频或输出图像,其中,所述风格化人脸驱动模型为根据如上述任一实施例所述的风格化人脸驱动模型训练方法训练得到的。
51、在本公开的一些实施例中,所述风格化人脸驱动设备还包括如上述任一实施例所述的风格化人脸驱动模型训练装置、和/或上述任一实施例所述的风格化人脸驱动模型构建装置。
52、根据本公开的另一方面,提供一种计算机装置,包括:
53、存储器,用于存储指令;
54、处理器,用于执行所述指令,使得所述计算机装置执行实现如上述任一实施例所述的风格化人脸驱动模型构建方法、如上述任一实施例所述的风格化人脸驱动模型训练方法、或如上述任一实施例所述的风格化人脸驱动方法的操作。
55、根据本公开的另一方面,提供一种计算机可读存储介质,其中,所述计算机可读存储介质存储有计算机指令,所述指令被处理器执行时实现如上述任一实施例所述的风格化人脸驱动模型构建方法、如上述任一实施例所述的风格化人脸驱动模型训练方法、或如上述任一实施例所述的风格化人脸驱动方法。
56、本公开可以同时实现人脸风格化和人脸驱动这两个任务,本公开可以在实现风格化人脸驱动任务地同时,能够很好地保持3d一致性。
- 还没有人留言评论。精彩留言会获得点赞!