文本聚类方法、装置、电子设备及存储介质与流程
本发明涉及人工智能,尤其涉及一种文本聚类方法、装置、电子设备及存储介质。
背景技术:
1、文本聚类作为一种常见的手段广泛应用于对话机器人的项目冷启动阶段中,对话机器人的项目冷启动阶段,需要对自然语言处理任务中的大量未标注数据进行分析整理,以提高工作效率,尤其广泛应用于归纳会话意图,梳理场景剧本等方面。
2、现有技术中,通常利用基于深度学习的大型语言预训练模型处理文本后,再利用文本聚类算法进行分析整理,以提升文本聚类效率,但此种方法基于深度学习的大型语言预训练模型和文本聚类算法进行文本处理时,由于语言预训练模型和文本聚类算法所表征的语义空间具有差异性,使得文本聚类的准确性较低。
技术实现思路
1、本发明提供一种文本聚类方法、装置、电子设备及存储介质,其主要目的在于提高文本聚类的准确性。
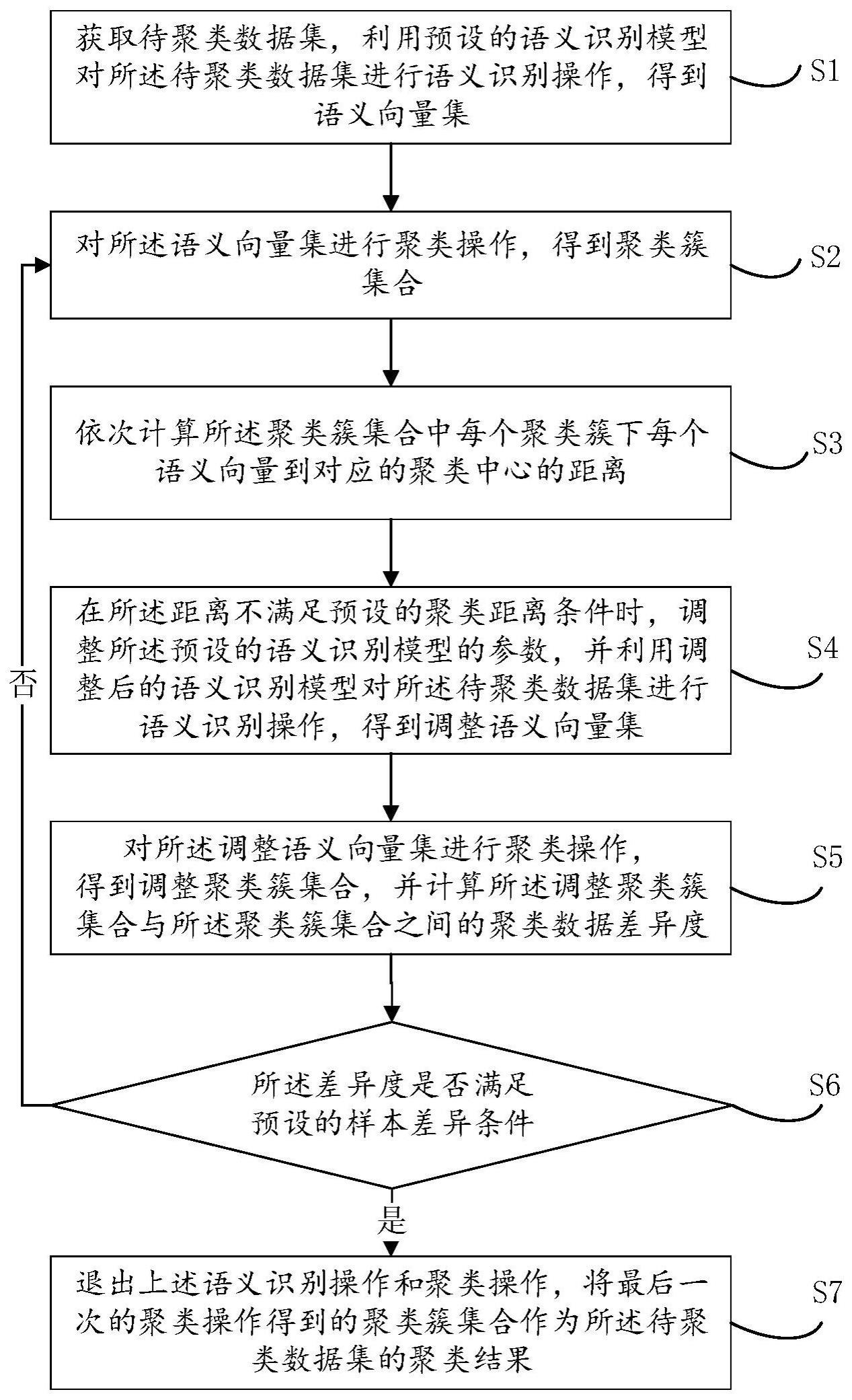
2、为实现上述目的,本发明提供的一种文本聚类方法,包括:
3、获取待聚类数据集,利用预设的语义识别模型对所述待聚类数据集进行语义识别操作,得到语义向量集;
4、对所述语义向量集进行聚类操作,得到聚类簇集合;
5、依次计算所述聚类簇集合中每个聚类簇下每个语义向量到对应的聚类中心的距离;
6、当所述距离不满足预设的聚类距离条件时,调整所述预设的语义识别模型的参数,并利用调整后的语义识别模型对所述待聚类数据集进行语义识别操作,得到调整语义向量集;
7、对所述调整语义向量集进行聚类操作,得到调整聚类簇集合,并计算所述调整聚类簇集合与所述聚类簇集合之间的聚类数据差异度;
8、当所述样本差异度不满足预设的样本差异条件时,返回上述对所述语义向量集进行聚类操作,得到聚类簇集合的步骤,直到相邻两次聚类操作后得到的聚类簇集合之间的聚类数据差异度满足所述预设的聚类数据差异条件时,或者所述距离满足所述预设的聚类距离条件时,退出上述语义识别操作和聚类操作,将最后一次的聚类操作得到的聚类簇集合作为所述待聚类数据集的聚类结果。
9、可选地,所述利用预设的语义识别模型对所述待聚类数据集进行语义识别操作,得到语义向量集,包括:
10、在所述待聚类数据集中的每个待聚类数据前添加文本起始符;
11、根据所述文本起始符,利用所述预设的语义识别模型接收所述待聚类数据集,并将所述待聚类数据集在所述预设的语义识别模型中进行文本向量映射,得到多个文本向量映射结果;
12、汇总所述多个文本向量映射结果,得到所述语义向量集。
13、可选地,所述对所述语义向量集进行聚类操作,得到聚类簇集合,包括:
14、从所述语义向量集中随机选取预设个数的语义向量作为聚类中心;
15、根据所述语义向量集中每个语义向量到所述聚类中心的距离,对所述语义向量集中剩余语义向量执行聚类划分,得到所述聚类簇集合。
16、可选地,依次计算所述聚类簇集合中每个聚类簇下每个语义向量到对应的聚类中心的距离,包括:
17、采用mse距离公式依次计算所述聚类簇集合中每个聚类簇下每个语义向量到对应的聚类中心的距离:
18、
19、其中,所述为所述聚类簇集合中每个聚类簇下第i个语义向量到对应的聚类中心的距离,γ为调节所述mse函数贡献度的超参数,f(xi)为第i个语义向量的向量表示,mi为所述第i个语义向量对应的聚类簇的聚类中心的语义向量。
20、可选地,所述计算所述调整聚类簇集合与所述聚类簇集合之间的聚类数据差异度,包括:
21、统计所述调整聚类簇集合与所述聚类簇集合之间的差异语义向量的数量;
22、计算所述差异语义向量的数量占全部语义向量数量的比例,得到所述聚类数据差异度。
23、可选地,所述在利用预设的语义识别模型对所述待聚类数据集进行语义识别操作,得到语义向量集之前,所述方法还包括:
24、获取意图标注样本,并提取所述意图标注样本中标注类别相同的样本,得到批次意图标注样本集;
25、随机选取所述批次意图标注样本集中的一个标注样本作为意图标注正样本,并将所述批次意图标注样本中剩余标注样本作为意图标注负样本集;
26、将所述意图标注正样本以及所述意图标注负样本集作为训练语料对所述预设的语义识别模型进行重构预训练,得到正样本语义向量以及负样本语义向量集;
27、计算所述负样本语义向量集中每个负样本语义向量与所述正样本语义向量之间的损失值;
28、在所述损失值满足预设的损失条件时,结束所述预设的语义识别模型的序列重构预训练过程。
29、可选地,所述计算所述意图标注负样本对应的负样本语义向量与所述意图标注正样本对应的正样本语义向量之间的损失值,包括:
30、采用下述损失函数公式:
31、
32、其中,lreqa为所述意图标注负样本对应的负样本语义向量与所述意图标注正样本对应的正样本语义向量之间的损失值,b为所述批次意图标注样本总数,τ为温度参数,为所述批次意图标注样本中第i个作为意图标注正样本的语义向量,为所述批次意图标注样本中第j个作为意图标注负样本的语义向量,q为所述批次意图标注样本中的意图标注正样本,a为所述批次意图标注样本中的意图标注负样本。
33、为了解决上述问题,本发明还提供一种文本聚类装置,所述装置包括:
34、待聚类数据集处理模块,用于获取待聚类数据集,利用预设的语义识别模型对所述待聚类数据集进行语义识别操作,得到语义向量集;
35、初始聚类模块,用于对所述语义向量集进行聚类操作,得到聚类簇集合;
36、模型优化模块,用于依次计算所述聚类簇集合中每个聚类簇下每个语义向量到对应的聚类中心的距离;当所述距离不满足预设的聚类距离条件时,调整所述预设的语义识别模型的参数,并利用调整后的语义识别模型对所述待聚类数据集进行语义识别操作,得到调整语义向量集;对所述调整语义向量集进行聚类操作,得到调整聚类簇集合,并计算所述调整聚类簇集合与所述聚类簇集合之间的聚类数据差异度;
37、文本聚类结果生成模块,用于当所述样本差异度不满足预设的样本差异条件时,返回上述对所述语义向量集进行聚类操作,得到聚类簇集合的步骤,直到相邻两次聚类操作后得到的聚类簇集合之间的聚类数据差异度满足所述预设的聚类数据差异条件时,或者所述距离满足所述预设的聚类距离条件时,退出上述语义识别操作和聚类操作,将最后一次的聚类操作得到的聚类簇集合作为所述待聚类数据集的聚类结果。
38、为了解决上述问题,本发明还提供一种电子设备,所述电子设备包括:
39、至少一个处理器;以及,
40、与所述至少一个处理器通信连接的存储器;其中,
41、所述存储器存储有可被所述至少一个处理器执行的计算机程序,所述计算机程序被所述至少一个处理器执行,以使所述至少一个处理器能够执行上述所述的文本聚类方法。
42、为了解决上述问题,本发明还提供一种计算机可读存储介质,所述计算机可读存储介质中存储有至少一个计算机程序,所述至少一个计算机程序被电子设备中的处理器执行以实现上述所述的文本聚类方法。
43、本发明实施例通过语义识别模型对待聚类数据集进行语义识别操作,并对识别后的语义向量集进行聚类操作,通过聚类簇中的每个语义向量到对应聚类中心的距离,调整所述语义识别模型,重复语义识别操作,并重新对新生成的语义向量集进行聚类,并通过相邻两次聚类操作得到的聚类簇之间的聚类数据差异度,重复聚类操作,相较于传统的先进行语义识别操作后再进行多次聚类操作的情况,上述语义识别操作与聚类操作相互结合,使得语言预训练模型和文本聚类算法皆使用同一语义空间内表征的数据进行语义识别操作以及聚类操作,并不断调整优化语义识别操作和聚类操作的结果,提升了文本聚类的准确性。
- 还没有人留言评论。精彩留言会获得点赞!