一种视网膜眼底图像的硬渗出液的分割方法
本发明涉及图像处理,尤其是涉及一种视网膜眼底图像的硬渗出液的分割方法。
背景技术:
1、在临床实践中,硬渗出液通常是诊断糖尿病视网膜病变(diabetic retinopathy,dr)的重要依据,因此,硬渗出液的准确分割对于早期dr诊断和预防视力丧失非常重要。然而,硬渗出液在整个视网膜图像中所占的比例相对较小,其形状往往不规则,对比度通常不够高容易受到视盘的干扰,这就容易导致分割准确性和效率低下。
2、硬渗出液的分割方法主要可分为三大类:无监督、粗到细的有监督和端到端的有监督。无监督的方法主要是利用硬渗出液的亮度特征,靠形态学和阈值的方法实现,这类方法的优点是不需要标签,但是缺点是精确度不高而且需要去除血管和视盘,对预处理的要求很高。
3、粗到细的有监督的方法,需要专家医生的标签。它由两个阶段组成:(1)粗检测阶段,提取硬渗出液的候选检测区域;(2)细检测阶段,分割出候选区域的硬渗出液。这类方法通常先去除眼底图像的血管和视盘,再利用形态学操作或者分类网络选出硬渗出液的候选区域,最后利用支持向量机或者阈值的方法实现对硬渗出液的分割。这类方法相比较无监督的方法,准确率得到明显提升,但是仍对图像的预处理提出了极高的要求。而且如何高效的选出硬渗出液的候选块也是值得思考的问题。
4、端到端的有监督的方法主要是利用深度学习模型实现。如u-net、全卷积残差网络(fully convolution residual network,fcrn)和hed-net等变体,但是这类模型只是在45度或者50度视场角的眼底图像上进行硬渗出液的分割,而200度视场角下的眼底图像背景环境和光照更加复杂,因此,现有技术无法准备对200度视场角下的眼底图像硬渗出液进行分割。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种视网膜眼底图像的硬渗出液的分割方法。
2、本发明的目的可以通过以下技术方案来实现:
3、本发明提供一种视网膜眼底图像的硬渗出液的分割方法,将经过预处理的视网膜眼底图像输入预先构建并训练好的rmcau-net模型中,得到硬渗出液的分割结果;
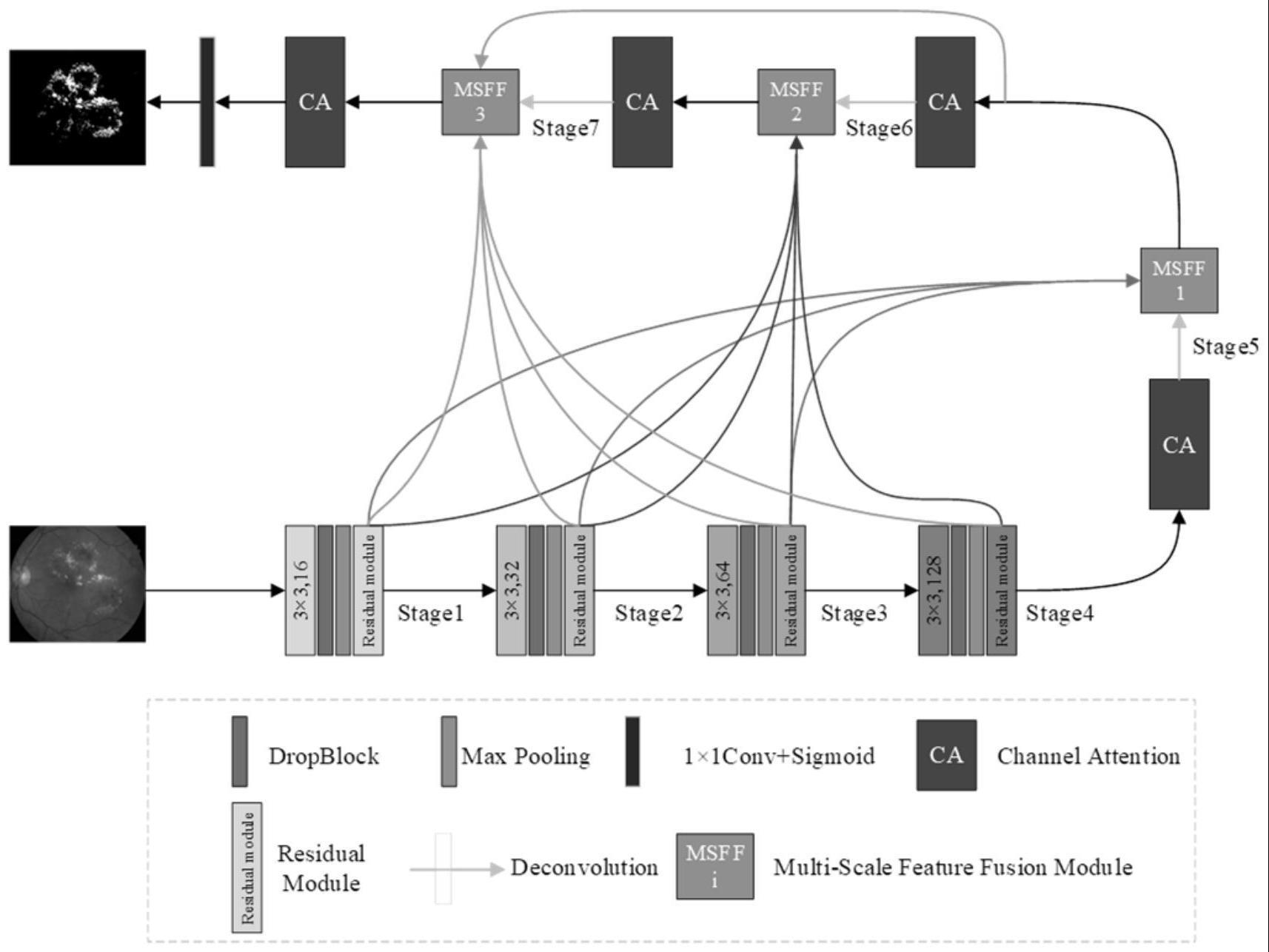
4、所述rmcau-net模型包括编码器和解码器,所述编码器包括多个编码阶段,每个所述编码阶段均包括依次连接的卷积层、dropblock模块、最大池化层和双残差模块,每个所述解码器包括多个解码阶段,每个所述解码阶段包括依次连接的通道注意力模块、反卷积层和多尺度特征融合模块,所述通道注意力模块用以利用最有用的特征通道,所述多尺度特征融合模块用以引导模型融合多尺度语义信息和全局上下文特征,各解码阶段中多尺度特征融合模块的输入包括所有编码阶段的输出和上一解码阶段的输出。
5、优选地,所述双残差模块包括两个相同的残差块,每个所述残差块包括依次连接的两个残差块层,每层残差块层均包括依次连接的归一化层、relu激活函数、3×3卷积层和dropblock模块。
6、优选地,描述每一残差块的结构的计算公式如下所示:
7、x1h,w,c=db(conv3×3(relu(bn(xh,w,c)))
8、x2h,w,c=db(conv3×3(relu(bn(x1h,w,c)))
9、x3h,w,c=conv1×1(xh,w,c)+x2h,w,c
10、式中,xh,w,c为该残差块的输入,h,w,c分别为特征图的高、宽和通道数,db代表dropblock层,conv3×3和conv1×1分别代表3×3和1×1卷积,x3h,w,c为该残差块的输出,x1h,w,c和x2h,e,c分别为前一个残差块层和后一个残差块层的输出。
11、优选地,所述通道注意力模块包括并行的平均池化分支和最大池化分支,用以获取更多的特征信息,描述通道注意力模块结构的计算公式如下所示:
12、
13、
14、ca(f)=σ(con1d(fap)+con1d(fmp))
15、f=fc+fc×ca(f)
16、式中,fc为输入的特征层,和分别代表最大池化和平均池化,σ为sigmoid函数,f为输出的特征层,h,w,c分别代表特征层的高、宽和通道数。
17、优选地,当前解码阶段的多尺度特征融合模块的处理过程具体为:
18、对所有编码阶段输出的特征层进行处理,包括1×1卷积和dropblock正则化操作,若处理后的编码阶段的特征层,与上一解码阶段输出的特征层大小不同,则处理成相同大小的特征层,将五个阶段相同大小的所有特征层进行拼接,再经过经过3×3卷积、dropblock模块和残差模块对通道进行调整。
19、优选地,描述多尺度特征融合模块操作的计算如下所示:
20、xah,w,c=pool2(db(conv1×1(x1h,w,c)))
21、xbh,w,c=db(conv1×1(x2h,w,c))
22、xch,w,c=up2(db(conv1×1(x3h,w,c)))
23、xdh,w,c=up4(db(conv1×1(x4h,w,c)))
24、xfh,w,c=concat(xah,w,c,xbh,w,c,xch,w,c,xch,w,c,x5h,w,c)
25、xch,w,c=rs(db(conv3×3(xfh,w,c)))
26、式中,x1h,w,c、x2h,w,c、x3h,w,c和x4h,w,c分别为各编码阶段输出的特征层,x5h,w,c为上一解码阶段输出的特征层,db为dropblock模块,pool2为2×2池化,conv1×1为1×1卷积,up2为2倍反卷积,up4为4倍反卷积,concat为拼接操作,conv3×3为3×3卷积,rs为残差模块,h,w,c分别代表特征层的高、宽和通道数。
27、优选地,所述rmca u-net模型使用的损失函数为二元交叉熵损失函数,计算公式如下所示:
28、
29、其中,x,y分别表示分割结果图和标签,h、w分别表示像素点在x、y中的坐标。
30、优选地,对于200度视场角下的视网膜眼底图像,该图像的预处理过程包括:
31、采用u-net模型对200度视场角下的视网膜眼底图像进行掩膜提取和感兴趣区域提取。
32、优选地,对于45度和50度视场角下的视网膜眼底图像,该图像的预处理过程包括随机反转、添加高斯噪声和对比度增强实现数据集的扩充,并对图像进行零填充。
33、优选地,通过pr曲线和roc曲线衡量训练好的模型的分割结果。
34、与现有技术相比,本发明具有以如下有益效果:
35、本发明提供的一种视网膜眼底图像的硬渗出液的分割方法,将双残差模块加入u-net的编码器中、多尺度特征融合模块代替原来的跳跃连接以及将改进的通道注意力模块融入到u-net解码器中,从而实现对硬渗出液的端到端分割。该方法可以有效避免图像中睫毛、设备边框以及光照不均衡带来的干扰,实现对硬渗出液的精准分割,且对不同视场角下的眼底图像均具有很强的鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!