一种基于领域分类的反向翻译数据构建及训练方法
本发明涉及自然语言处理、机器翻译、数据增强领域,尤其是涉及一种基于领域分类的反向翻译数据构建及训练方法。
背景技术:
1、近年来,神经机器翻译成为机器翻译方法的主流模型,然而神经机器翻译对于数据的依赖性极高,通常而言训练数据越大翻译质量越佳,对于少数语言的机器翻译,其双语平行语料的不足往往成为限制其翻译质量的重要因素,尤其是在特殊领域的机器翻译,高质量的领域语料和大量的通用语料相比十分稀少。需要采取一些数据增强的方法来改善翻译质量,其中典型的方法即利用单语语料进行反向翻译获取伪平行语料。因此,如何有效获取大量高质量的单语语料,并保证其反向翻译过程中质量损失更少以此改善机器翻译模型成为研究目标之一。另一方面,相比较于庞大的单语通用语料而言,特殊领域的单语数据更加稀少以及不平衡问题导致训练过程中领域知识被忽略,翻译模型在实际领域的翻译效果不佳。
2、反向翻译是一种利用单语语料提升训练数据质量的常用方法。将反向翻译方法应用于语料缺乏的机器翻译任务在不同的文献当中都验证了有效性。其中edunov等人(sergey edunov,et al.2018.understanding back-translation at scale.inproceedings of the 2018conference on empirical methods in natural languageprocessing,pages 489–500,brussels,belgium.association for computationallinguistics)对不同场景下反向翻译进行了研究,证明了反向翻译能提升bleu。sennrich等人(rico sennrich,barry haddow,and alexandra birch.2016.improving neuralmachine translation models with monolingual data.in proceedings of the 54thannual meeting of the association for computational linguistics(volume 1:longpapers),pages86–96,berlin,germany.association for computational linguistics.)则利用反向翻译的单语数据和原语料混合后加入训练提高翻译质量,同时他们的进一步研究证明这种目标单语的合成数据对领域自适应有很大帮助(rico sennrich,barryhaddow,and alexandra birch.2016c.neural machine translation of rare wordswith subword units.in proceedings of the 54th annual meeting of theassociation for computational linguistics(volume 1:long papers),pages 1715–1725,berlin,germany,august.association for computational linguistics)。而在领域数据的构建上,一般直接采用现有的人工标记的领域数据集或使用同义词相似性和句子相似性替换的方式构成数据集。面临通用数据和领域内数据的采样问题上,通过增加领域相关权重及改变模型训练目标是常见的方式。如chen等人(boxing chen,colin cherry,george foster,and samuel larkin.2017a.cost weighting for neural machinetranslation domain adaptation.in proceedings of the first workshop on neuralmachine translation,pages 40–46,vancouver.)通过提前训练一个领域分类,并把输出概率迁移到翻译模型中代替实际权重,wang等人(rui wang,masao utiyama,andrewfinch,lemao liu,kehai chen,and eiichiro sumita.2018.sentence selection andweighting for neural machine translation domain adaptation.ieee/acmtransactions on audio,speech,and language processing)则通过句子选择和领域加权进行联合训练。然而这些方法存在一些不足:一是人工标记的领域数据较少,而基于替代的方式过于机械且不符合现实分布;在领域和通用数据集学习上,缺乏领域权重的模型无法解决样本分布不平衡的问题,不能很好学习领域知识,而提前训练额外的分类器在迁移过程中仍需要进行一轮权重调整来适应模型。
技术实现思路
1、本发明的目的在于针对少数语言翻译尤其是特殊领域翻译过程中,由于语料缺乏导致的翻译质量不高问题,提供一种基于领域分类的反向翻译数据构建及训练方法。利用领域主题相似性的方法从文档中构建伪平行语料来增强领域数据集,通过领域分类的联合训练来提升领域适应能力,提高模型的领域识别能力和泛化性能,一方面可以更快更好挖掘高质量领域单语数据,另一方面是使模型更好的学习领域知识,从而增强神经翻译模型对领域翻译的翻译质量。
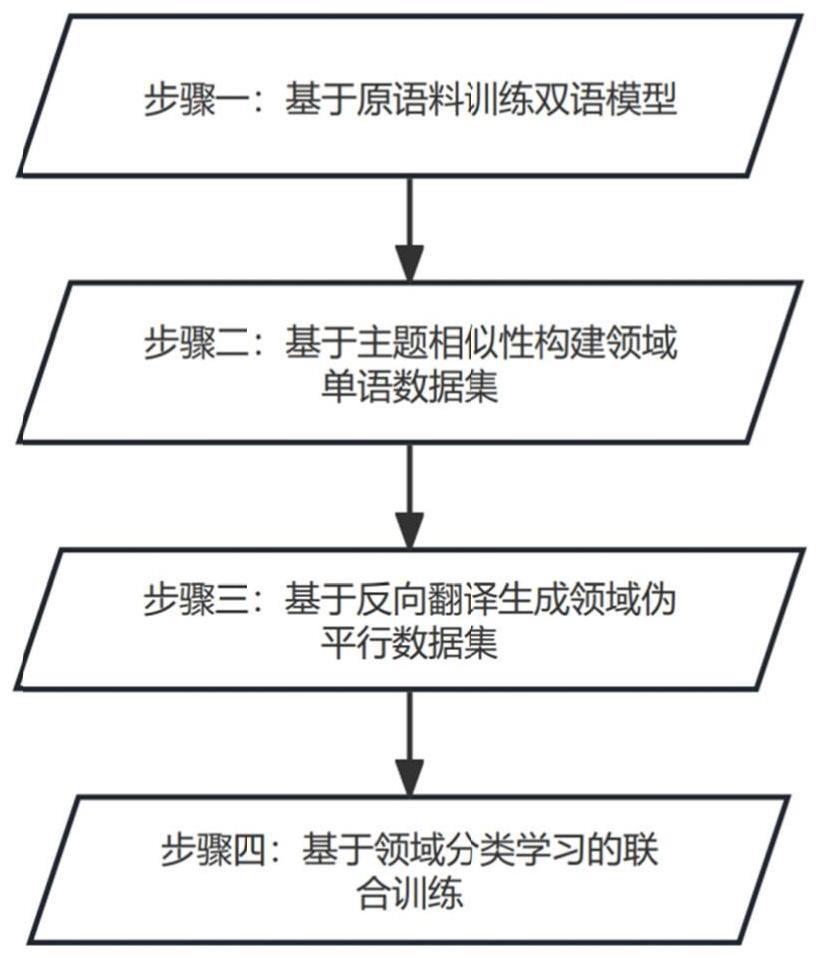
2、本发明包括以下步骤:
3、1)基于原语料训练双语模型:使用transformer神经网络模型,将双语原语料分别作为源端-目标端和目标端-源端训练两个神经机器翻译模型,
4、2)基于关键词和主题相似性构建领域单语数据集;
5、3)基于反向翻译生成领域伪平行数据集:将步骤2)获取的领域单语数据集作为源端数据集,使用步骤1)中训练好的双语模型进行反向翻译获得伪句子对,整理对齐后形成领域伪平行数据集;
6、4)基于领域分类学习的联合训练:将步骤3)所得伪平行数据集标记为领域语料与通用数据进行混合后联合训练。
7、在步骤1)中,所述基于原语料训练双语模型的具体步骤可为:
8、语言模型基于开源transformer的神经网络模型,该模型基于self-attention的编码器-解码器模型,由输入、编码、解码、输出四个模块组成;输入模块将训练文件中读出的输入的文本序列input={s1,s2,s3,…,st},st代表第i个单词,获得初始化词嵌入并与位置编码连接后得到输入向量input embedding={x1,x2,…,xt},送入编码器;编码器每一层由多头注意力机制,前馈神经网络组成,规范化层,残差连接组成,其中核心模型为多头注意力机制由注意力机制演化而来,表达式为:
9、
10、在编码器得到输入的抽象特征表示后,将其输入到解码器中进行解码;解码器与编码器结构基本一致,反过来执行将目标嵌入、编码器状态、解码器状态联系起来进行解码;解码结果经过一个线性层和softmax层输出为标签整体的概率分布;对于机器翻译双语模型而言,常用的训练损失函数为交叉熵损失;基于该模型的使用,将整理好的高质量的原始双语数据集s进行对齐、分词、bpe、统计词表、训练集分割等预处理后,分布训练一个单向模型;基于构造的双语模型,用原始语料进行训练,得到两个双语模型;
11、在步骤2)中,所述基于关键词和主题相似性构建领域单语数据集的具体步骤可为:
12、寻找领域相关的篇章中即通过文档主题相似性扩展数据集,以避免逐句选择的低效性;对任意一个领域,领域内频繁出现的关键词可以代表这个领域的主题,但需要排除掉一些代词,人名等无意义词汇,可以通过程序自动获取的方式构建,具体构建方法:
13、(1)构建一个基本词库,使用python工具包对现有领域数据集进行词频统计,获取前500个常用词汇中后人工筛选出一个词库,过滤掉一些常用词汇,得到一个大小为256的基本词库作为领域主题代表d=[d1,d2,…,dn],di表示第i个单词;
14、(2)提取文档的主题,它和上述过程相似,也可以通过词频统计的方式获取;对文档库中任意一篇文章p=[p1,p2,p3…,pn],pi代表第i个句子;执行内容选择,提取文档的重要句子,提供两种提取方式的混合,一是基于主要结构的提取,通常来说,一篇文档的重要部分主要集中在标题、首段和尾端,按照惯例提取这些部分;二是选择包含某些信息性关键词(如“总的来说”)的句子进行提取;通过两种方式的提取构成子集p1并满足提取总数约束,通用将这些句子进行词频统计过滤获得文章关键词代表集合ds=[dp1,dp2,…,dpn];通过这样的方式,主题相似性可以转化为两个代表主题的关键词集合的相似性,可以通过向量表示的方式来计算二者的相似性;
15、(3)将使用bert词向量将d和ds转化为向量表示,将所有词向量求和获得主题向量表示和
16、
17、
18、使用皮尔森相关系数来表示两者的相似度,用于判断文本主题与词库中词语的相似度,计算公式为:
19、
20、对整个文档库中所有文档进行相似度计算,取文档库中10%的文档作为领域相关数据候选集,基于正则表达式切分文档并进行去重过滤后构建获得新的领域单语数据集
21、在步骤3)中,所述基于反向翻译生成领域伪平行数据集的具体步骤可为:
22、将获取的领域单语数据集作为源端数据集输入x,使用步骤1)中训练好的源语言到目标语言的翻译模型获得伪句子对整理对齐后形成伪双语平行数据集s1;当原平行语料较多时,采样方式使用beam search加上noise的方式,当平行语料较少时,使用的采样方式为beam search;
23、在步骤4)中,所述基于领域分类学习的联合训练,具体步骤包括:
24、为了让模型更好学习领域相关知识,有效区分噪声,同时保证模型的匹配度,将生成的伪双语平行数据集s1和原平行语料s混合重新训练;训练模型采用transformer模型,在训练时的模型中加入一个领域分类的任务进行联合训练;在源语言输入中加入一个标签以区分领域数据和非领域数据用于实现分类;给定句子对的源句子x={x1,…,xw},标签domian={normal|special}和目标句子y={y1,…,yt|,其中,w和t是源句子和目标句子的标记数量,其中机器翻译的训练目标函数如下:
25、
26、其中,θ是可学习的模型参数;
27、领域分类的目标函数如下:
28、
29、其中,为模型领域分类的概率,πy则是正确的分类标签,1表示special,0表示normal;
30、两个参数λ1和λ2为需调整参数,最终损失函数可以表示为:
31、
32、本发明提出一种基于领域分类的反向翻译数据构建及训练方法。基于领域的分类的概念,通过关键词和主题相似性从网络文本中筛选出领域相关的文本进行切分构成领域单语数据集。同时用原语料数据集训练两个双语翻译模型,将获取的领域单语语料进行反向翻译构成伪平行双语语料。将这些伪平行数据标记为领域语料和通用数据进行联合训练,训练模型中加入领域分类用于提高领域内翻译质量。本发明通过利用关键词和主题相似性的方法快速高效构建领域数据集的同时利用反向翻译增强翻译效果,为保证模型更好学习领域和通用数据的分布,通过领域分类的联合训练的方式能让模型在通用数据上的增量的同时保持对领域数据的很好识别效果,同时这种反向翻译有利于提高数据数量,保证模型质量提高,在获取高质量的相关领域的知识的同时,有效利用通用领域知识,提高翻译性能,保证翻译质量。
- 还没有人留言评论。精彩留言会获得点赞!