一种基于视频理解的矿井下异常动作识别方法
本发明涉及一种视频检测方法,一种基于视频理解的矿井下异常动作识别方法。
背景技术:
1、矿井安全生产是矿石企业经济效益得以保证的基础,也是其生产经营的主要内容和首要环节。过去近10年,我国矿石产量先后经历了供给侧改革前后的上涨、下跌和回升,然而矿井安全水平却在不断提升,百万吨死亡率基本成逐年下降趋势,这要得益于煤矿机械化、智能化推进对少人化、无人化的推动,以及政策层面对于安全生产的高度重视。矿产资源是经济社会发展的重要物质基础,开发利用矿产资源是现代化建设的必然要求。矿井下普遍有着环境错综复杂,矿工数量较多,机器设备庞大等特点,如果不能对矿工的行为进行有效监控,矿工在工作过程中很可能发生安全事故,对人员生命和设备安全造成危害。通过调查近些年的井下事故,可以发现大部分的事故都是作业人员行为不规范,做出异常动作导致的。国内行业对井下作业人员的行为监控仍采用传统人工监控方法,即监控人员通过采集到的监控视频对井下情况进行监测。但是,这种依靠人工的方法存在一系列问题。第一,监控人员长时间观看井下视频,身体容易产生疲劳,随着时间的增加,监控人员难以保持专注,反应力会下降,当发现井下工作人员进行异常行为动作,比如横跨轨道时,不能及时地对异常动作做出反应,因此人工监测存在较大的安全隐患。第二,井下地形复杂、区域众多,监控人员无法同时对多处区域的视频进行有效监控,容易遗漏部分区域。并且,由于工人数量多,行为动作复杂,有时会在短时间内发生人数的变化以及较大的动作幅度,人工同时对多个视频的监测能力有限,与智能化监控相比,工作效率低。第三,井下的图像细节模糊、曝光不均,在光线弱、粉尘多的地方,监控人员的辨别能力会大幅减弱。同时因为井下巷道狭窄、矿石等障碍物多,易形成视野盲区,仅通过人眼观测,难以精准地监测到矿工行为动作的细节,可能做出错误判断,因此监控效果不佳。
2、综上所述,传统的矿井下异常动作识别大量依赖人工处理,存在着无法保持高效监测、容易遗漏区域、图像辨别能力弱等技术问题。
技术实现思路
1、对于上述现有技术存在的问题,提出了基于视频理解的矿井下异常动作识别系统,目的为了避免矿井下工人异常行为的发生。包括:通过摄像头获取井下视频数据;预处理视频数据进行视频剪裁与抽帧,先将图片帧中的人物进行识别与标记;再将标记的人物目标绑定id进行前后帧跟踪;视频结果送入预设的3d-resnet网络并获得权重;将样本输入至slowfast网络获得动作识别结果;根据追踪目标的具体动作,发现异常行为并发出警告。本发明解决了矿井下矿工异常动作判断智能化水平低的问题。
2、本发明解决技术问题采用如下技术方案:
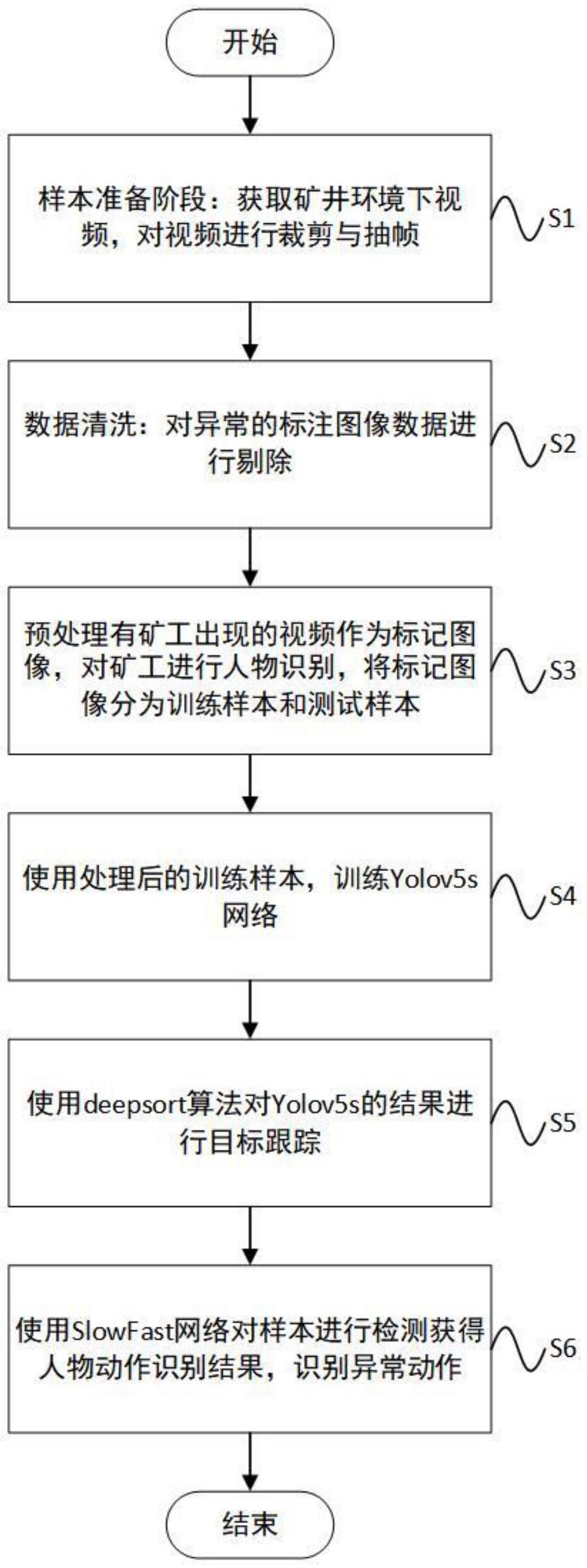
3、1、一种基于视频理解的矿井下异常动作识别方法,用于对矿井场景中矿工异常动作进行智能识别,其特征是按以下步骤进行:
4、a、样本准备阶段,获取矿井下工作环境视频,对视频进行剪裁与抽帧,预处理有矿工出现的视频作为标记图像,将所述处理标记图像按7:3分为训练样本和测试样本,对异常的标注图像数据进行剔除后得到训练用的数据集;
5、b、使用处理后的训练样本训练yolov5s网络,对有矿工出现的视频进行人物识别;
6、c、使用deepsort算法对yolov5s的结果进行人物id绑定进行目标跟踪;
7、d、通过所述的训练好的slowfast网络进行检测获得人物动作识别结果,识别到可能存在的异常动作;
8、2、如权利要求1所述基于视频理解的矿井下异常动作识别方法,其特征是所述步骤a样本准备阶段获取矿井下工作环境的步骤,包括:
9、(1)在矿井车上或者井下工作区域安装摄像头采集有矿工出现的视频流数据;
10、(2)按照一定的时间间隔抽取视频中的关键帧并保存为图像数据;
11、3、如权利要求1所述基于视频理解的矿井下异常动作识别方法,其特征是所述步骤a样本准备阶段预处理步骤,包括:
12、(1)采用标注软件对所述图像数据进行标注,获得并保存标注后的标记数据集;
13、(2)对抽取的视频帧进行整合和缩减帧;
14、(3)从标注后的数据集中按照7:3分成训练样本和测试样本;
15、4、如权利要求1所述基于视频理解的矿井下异常动作识别方法,其特征是所述步骤a样本准备阶段对异常数据剔除步骤,包括:
16、(1)剔除没有矿工等人物目标出现的数据;
17、(2)剔除人物目标出现但是人物信息不完整的数据;
18、5、如权利要求1所述基于视频理解的矿井下异常动作识别方法,其特征是所述步骤b对有矿工出现的视频进行人物识别,包括:
19、(1)输入端主要对输入的图片进行预处理,整个过程包括mosaic数据增强、自适应锚框计算和自适应图片缩放。
20、(2)主干网络部分主要包括focus层、卷积块(cbl)、跨阶段局部网络(cross stagepartial network,cspnet)和空间金字塔池化(spatial pyramid pooling,spp)模块。通过切片操作对输入图像进行裁剪和堆叠,将图片长宽缩小到原始的一半,通道数为原来的4倍,可减少模型计算量,且不会带来信息损失。具体流程为:首先切片操作将输入的原始640×640×3通道的图像分成4个切片,每个切片的大小为320×320×3。其次,利用32个卷积核的卷积操作将4个部分concat操作深度连接起来,再通过32个卷积组成的卷积层,输出大小为320×320×32的特征图。由conv卷积层+batchnorm层+leakyrelu激活函数共同组成cbl,即输入部分先经过卷积层(conv),提取输入特征,找到特定的局部图像特征;接着通过batchnorm层,进行归一化,将每次的梯度分布都控制在原点附近,使各个batch的偏差不会过大;最后再由leakyrelu激活函数将输出结果传到下一层卷积。
21、
22、leakyrelu通过把x的非常小的线性分量给予负输入来调整负值的零梯度问题,通常a的值为0.01左右。csp:在yolov5s中有两种csp结构,其中csp1_x在backbone网络中实现特征提取,csp2_x在neck结构中使用进行预测。主干网络的csp1_x模块由支路1和支路2组成,支路1由卷积层、批量归一化和激活函数组成,支路2由卷积层、批量归一化、激活函数和x个残差单元组成;所述neck网络的csp2_x模块由支路3和支路4组成,支路3和支路4均由卷积层、批量归一化和激活函数组成。经过两条支路,通道数都会减半,再经过concat拼接起来,通道数保持不变。csp1_x模块解决了backbone结构中网络优化的梯度信息重复的问题,减少了yolov5s网络结构模型的参数量,保证检测速度和准确率的同时,减少了模型的尺寸。
23、spp:先进行conv卷积提取特征输出,接着采用1×1、5×5、9×9、13×13四种尺度的最大池化,然后由concat进行拼接实现多尺度特征融合,能够解决输入图像尺寸不统一的问题。
24、backbone网络得到尺寸为80×80×128、40×40×256、20×20×512三种不同尺度的特征图并送入neck端;其中,尺寸为80×80×128的特征图包含的低级层特征占大多数,以加强模型小目标检测性能;尺寸为20×20×512的特征图包含高级层特征占大多数,以加强模型大目标检测性能;尺寸为40×40×256的特征图的低级和高级特征信息占比相当,用于中等目标检测。
25、(3)neck网络利用了特征金字塔网络(feature pyramid networks,fpn)将深层的语义特征传到浅层,而路径聚合网络(path aggregation network,pan)则可以将浅层的位置信息传递到更深层,从而提高了定位能力。fpn+pan结构不仅获得了丰富的语义特征,还获得了较强的定位特征,增强特征融合效果。具体流程为:首先fpn网络对图像金字塔spp处理后的特征图进行卷积操作,卷积过程的卷积核大小为1*1、步长为2,经过卷积特征提取后得出尺寸大小为20*20的特征图,与来自主干网络提取出的同样大小为20*20的特征图进行2倍的上采样特征融合,得到尺寸大小40*40的特征图,接着将处理得到的40*40特征图继续重复进行卷积操作,卷积过程的卷积核大小为1*1、步长为2,经过卷积特征提取后得出尺寸大小为40*40的特征图,与来自主干网络提取出的同样大小为40*40的特征图进行2倍的上采样特征融合,得到尺寸大小80*80的特征图,然后pan网络对fpn的特征图同样进行3次卷积核大小为3*3,步长为2的卷积操作,提取到的特征图与fpn提取出的[80*80,40*40,20*20]的特征图进行下采样特征融合,最终得出3个特征预测图,三个特征预测图的尺寸大小同样为[80*80,40*40,20*20]。
26、(4)预测端经过8倍下采样、16倍下采样和32倍下采样输出三个尺寸的特征图,并通过非极大值抑制(non maximum suppression,nms)输出置信度最高的预测框信息,从而获得检测结果。在目标检测中,在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,所以需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。具体流程为:首先对所有预测框的置信度降序排序,接着选出置信度最高的预测框,确认其为正确预测,并计算他与其他预测框的iou,然后根据计算的iou去除重叠度高的,iou大于阈值即删除,剩下的预测框返回第1步,直到没有剩下的为止,最后即找到最佳的目标边界框。
27、(5)yolov5s的损失函数包括置信度损失(objectness loss)、分类损失(classification loss)和边框回归损失(bounding box regeression loss)。
28、总损失公式定义为:
29、loss=a1lobj+a2lcla+a3lbbox
30、其中a1、a2、a3为权重系数。
31、objectness loss和classification loss由二元交叉熵损失函数(bce loss)计算得出:
32、
33、其中xa是二元标签值0或者1,p(xa)是属于xa标签值的概率。
34、边框回归损失由ciou函数(complete intersection over union)计算得出:
35、
36、式中:
37、
38、
39、
40、iou表示两个重叠矩形框之间的交并比;x和xgt表示两个重叠矩形框的中心点;d表示两个重叠矩形框之间的欧氏距离;y表示两个重叠矩形框的闭包区域的对角线距离;m衡量两个矩形框相对比例的一致性;β表示权重系数。损失函数考虑了两个框的重合面积、中心点的距离和长宽比的相似性,使预测框更加符合真实框,可以达到收敛速度更快、精度更高的效果。
41、评估指标:为了准确评估网络模型性能,使用精准率(precision,p)和召回率(recall,r)、平均精度均值(mean average precision,map)以及每秒传输帧数(framesper second,fps)作为评估指标,具体公式如下:
42、
43、
44、
45、
46、
47、其中t为正确检测目标个数,f为错误检测目标个数,n为漏检目标个数,ap表示precision-recall曲线下的面积,对该图片每一类的平均精度求均值即map,n表示被测样本数,α表示测试全部样本所需的时间。
48、6、如权利要求1所述基于视频理解的矿井下异常动作识别方法,如权利要求1所述基于视频理解的矿井下异常动作识别方法,其特征是所述步骤c使用deepsort算法对yolov5s网络的检测结果进行目标跟踪,包括:
49、(1)根据上述检测步骤得到检测框,采用一个cnn网络来提取目标的运动特征预测框坐标值、人物目标的坐标值,使用卡尔曼滤波进行轨迹预测,采用deep associationmetric提取外观特征,采用级联匹配、iou匹配的匹配机制;
50、(2)设置网络训练策略,包括:训练batch大小,初始化学习率,权重衰减率,优化方法,loss函数;
51、(3)将训练数据送入网络模型,得到新的特征提取网络。使用如下损失函数计算网络提取的外观特征与真实结果的差异:
52、
53、
54、其中ai为特征向量,(1)计算softmax函数结果y(ai)即为预测结果,w(ai)真实结果。
55、(4)通过步骤(3)中训练的网络得到当前帧检测框的外观特征(记作bm),通过如下公式计算当前帧检测框的外观特征与所有的外观特征的最小距离:
56、
57、其中属于所有帧的外观特征集合。
58、(5)通过如下公式加权融合外观特征信息和运动特征信息:
59、tm,n=αd1(m,n)+(1-α)d(m,n)
60、其中d1(m,n)为马氏距离,d(m,n)为余弦定理,α为权重系数。
61、7、如权利要求1所述基于视频理解的矿井下异常动作识别方法,其特征是所述步骤c构建网络模型;将所述的slowfast网络对deepsort的跟踪结果进行异常动作识别,包括:
62、(1)使用3d卷积神经网络(cnn)提取视频帧中的特征;设置resnet3d网络,主干网络分为慢速路径与快速路径。慢速路径使用resnet3d网络,第一层使用1个大小为7*7的卷积核,在低帧率下运行,捕获空间语义,获得环境信息;快速路径使用resnet3d网络,基础通道数目为8,第一层使用5个大小为7*7的卷积核,在高帧率下运行,以捕获精细时间分辨率的运动。头部分类网络使用slowfast头,特征连接的通道数为2048+256。
63、(2)特征融合,网络采用将fast通道的数据通过侧向连接被送入slow通道,即将快速路径提取的信息融合到慢速路径中。卷积核的尺寸记作{t×s2,c},其中t、s和c分别表示采样次数、空间分辨率和卷积核数量。跳帧率为α=8,通道比为1/β=1/8。fast通道的单一数据样本为{αt,s2,βc},slow通道的单一数据样本为{t,s2,αβc}。本发明通过使用2βc输出通道和步幅为α对5×12内核进行三维卷积的方式进行数据变换。
64、(3)在每个通道的末端执行全局平均池化,之后组合快速慢速通道的结果并送入一个全连接分类层,该层使用softmax来识别图像中矿井工人正在进行的动作。
65、如上所述,通过本发明所提供的一种基于基于视频理解的矿井下异常动作识别方法,通过摄像头获取井下视频数据;预处理视频数据进行视频剪裁与抽帧,先将图片帧中的人物进行识别与标记;再将标记的人物目标绑定id进行前后帧跟踪;视频结果送入预设的resnet3d网络并获得权重;将样本输入至slowfast网络获得动作识别结果;根据追踪目标的具体动作,发现异常行为并发出警告。不需要采用手工提取复杂特征,检测效率高。本发明突破了传统井下安全检测中大量人工观测和操作导致检测错误率高,提高了系统检测井下异常动作识别的准确率,并增强了针对恶劣条件下的检测能力,本发明提出的技术方案更加有利于复杂的工业的使用。
66、综上,本发明提供了基于视频理解的矿井下异常动作识别系统,解决了矿井下矿工异常动作判断智能化水平低、识别准确率低的问题。
- 还没有人留言评论。精彩留言会获得点赞!