用于多智能体强化学习的方法、系统、设备和存储介质与流程
本技术一般涉及多智能体。更具体地,本技术涉及一种用于多智能体强化学习的方法、系统、设备和计算机可读存储介质。
背景技术:
1、多智能体是指驻留在某一环境下的多个实体,它们可以解释从环境中获得的反映环境中所发生事件的数据,并执行对环境产生影响的行动。其中,多个多智能体可以是硬件(例如机器人),也可以是软件。多智能体强化学习(multi-agent reinforcementlearning,“marl”)是指让多个智能体处于相同的环境中,每个智能体独立与环境交互,利用环境反馈的奖励改进自己的策略,以获得更高的回报,其应用于例如多个机器人的控制、语言的交流及多玩家的游戏等场景。
2、现有多智能体强化学习有两种主要的技术路径:一种是集中式的训练和分布式的执行,一种是独立学习。其中,集中式的训练指在训练时智能体共享包括观察和行动在内的所有信息,而分布式的执行指在部署时,智能体不再共享信息而是独立运行。这种设置在某些情况下使训练更有稳定性,但在应用到大规模的多智能体训练时却会带来较大的通信开销,而且难以实现部署后的策略优化。对于独立学习而言,训练过程和执行过程都是去中心化的,智能体之间不共享信息,而且每个智能体都将其他智能体认为是环境。独立训练避免了额外的通信开销而且使得部署后优化成为可能,其最常用的算法为独立近端策略优化算法(independent proximal policy optimization,“ippo”)。然而,ippo算法是根据未来累计奖励估计梯度来调整行动的对数概率,这种累积奖励奖励也受到其他因素(例如当前状态和其他智能体的行动等因素)的影响,而使梯度估计存在较高的方差,从而导致较低的采样效率和较低的最终性能。
3、有鉴于此,亟需提供一种用于多智能体强化学习的方案,以便降低梯度估计的方差,提高采样效率和性能。
技术实现思路
1、为了至少解决如上所提到的一个或多个技术问题,本技术在多个方面中提出了用于多智能体强化学习的方案。
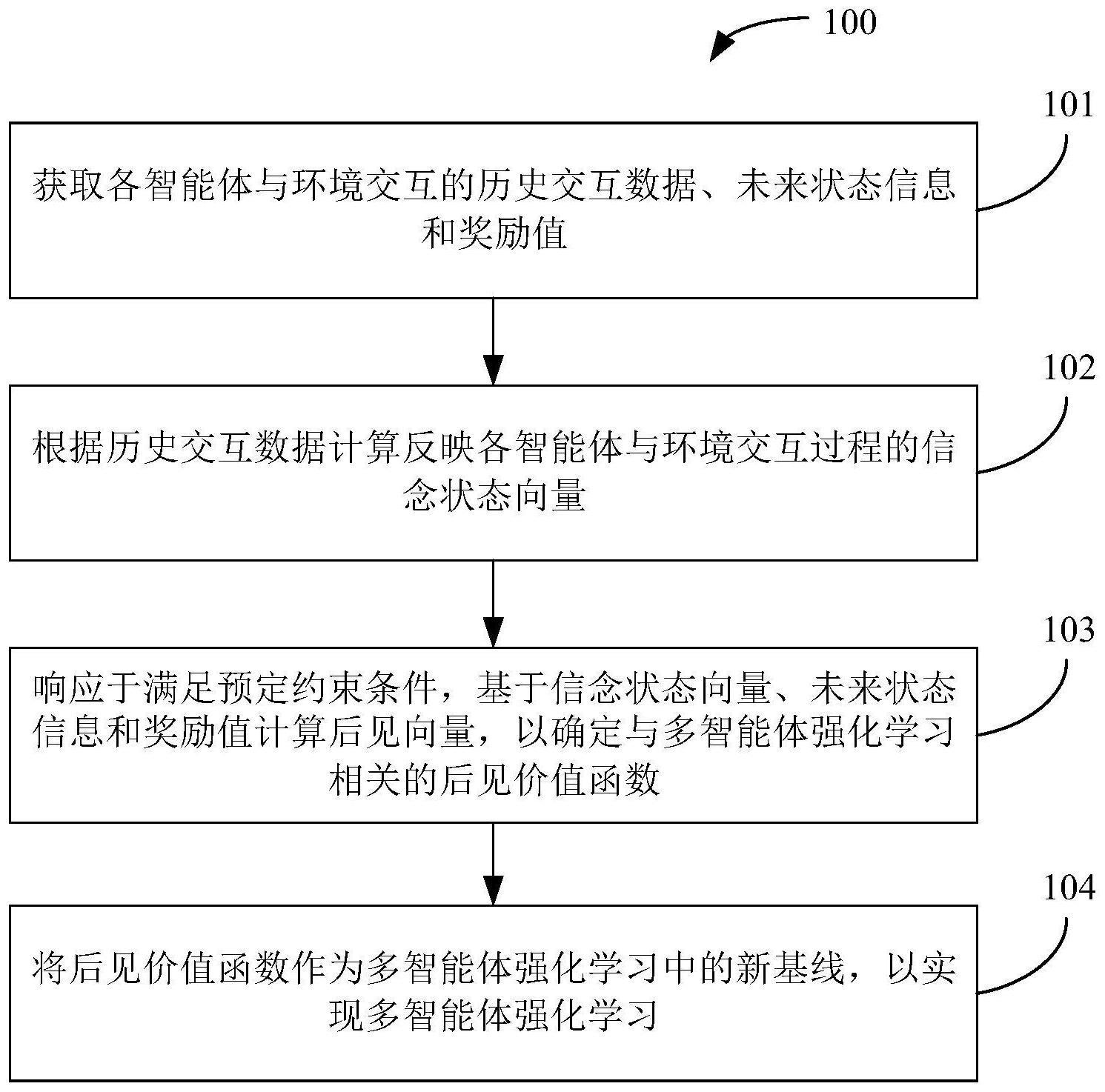
2、在第一方面中,本技术提供一种用于多智能体强化学习的方法,包括:获取各智能体与环境交互的历史交互数据、未来状态信息和奖励值;根据所述历史交互数据计算反映所述各智能体与环境交互过程的信念状态向量;响应于满足预定约束条件,基于所述信念状态向量、所述未来状态信息和所述奖励值计算后见向量,以确定与多智能体强化学习相关的后见价值函数;以及将所述后见价值函数作为多智能体强化学习中的新基线,以实现多智能体强化学习。
3、在一个实施例中,其中所述历史交互数据包括所述各智能体的历史状态信息和历史执行动作,并且根据所述历史交互数据计算反映所述各智能体与环境交互过程的信念状态向量包括:基于所述各智能体的历史状态信息和历史执行动作,使用信念状态网络进行计算,以获得反映所述各智能体与环境交互过程的信念状态向量。
4、在另一个实施例中,所述方法还包括:基于所述信念状态向量,使用估计网络进行估计,以获得与所述各智能体的状态和奖励有关的估计向量;以及根据所述估计向量更新所述估计网络和所述信念状态网络。
5、在又一个实施例中,其中根据所述估计向量更新所述估计网络和所述信念状态网络包括:根据所述估计向量、所述未来状态信息和所述奖励值构建第一损失函数;以及基于所述第一损失函数更新所述估计网络和所述信念状态网络。
6、在又一个实施例中,其中基于所述第一损失函数更新所述估计网络和所述信念状态网络包括:基于所述第一损失函数更新所述估计网络和所述信念状态网络各自对应的第一参数和第二参数;以及利用更新后的第一参数和第二参数分别更新所述估计网络和所述信念状态网络。
7、在又一个实施例中,其中响应于满足预定约束条件,基于所述信念状态向量、所述未来状态信息和所述奖励值计算后见向量包括:响应于满足预定约束条件,基于所述信念状态向量、所述未来状态信息和所述奖励值,使用后见向量网络进行计算获得所述后见向量。
8、在又一个实施例中,所述方法还包括:响应于满足所述预定约束条件,使用分布网络进行分布估计,以获得预定信念状态下后见向量的分布信息;根据所述分布信息构建第二损失函数;以及基于所述第二损失函数更新所述后见向量网络。
9、在又一个实施例中,所述方法还包括:对所述分布网络进行更新,以获得更新后的分布网络;以及根据所述更新后的分布网络和所述第二损失函数更新所述后见向量网络。
10、在又一个实施例中,其中根据所述更新后的分布网络和所述第二损失函数更新所述后见向量网络包括:根据所述更新后的分布网络和所述第二损失函数更新所述后见向量网络对应的第三参数;以及利用更新后的第三参数更新所述后见向量网络。
11、在又一个实施例中,所述方法还包括:响应于满足所述预定约束条件,使用辅助网络辅助所述后见向量网络进行计算,以获得所述后见向量。
12、在又一个实施例中,其中使用辅助网络辅助所述后见向量网络进行计算包括:响应于满足所述预定约束条件,使用辅助网络进行预测,以获得与所述各智能体的状态和奖励有关的预测向量;以及根据所述预测向量更新所述辅助网络,以辅助所述后见向量网络进行计算。
13、在又一个实施例中,其中根据所述预测向量更新所述辅助网络包括:根据所述预测向量、所述未来状态信息和所述奖励值构建第三损失函数;以及基于根据所述更新后的分布网络和所述第三损失函数更新所述辅助网络。
14、在又一个实施例中,其中基于根据更新后的分布网络和所述第三损失函数更新所述辅助网络包括:根据所述更新后的分布网络和所述第三损失函数更新所述辅助网络对应的第四参数;以及利用更新后的第四参数更新所述辅助网络。
15、在又一个实施例中,其中所述信念状态网络包括长短期记忆网络,所述估计网络、所述分布网络、所述辅助网络和所述后见向量网络均包括全连接网络。
16、在第二方面中,本技术提供一种用于多智能体强化学习的系统,包括:数据获取单元,其用于获取各智能体与环境交互的历史交互数据、未来状态信息和奖励值;第一计算单元,其用于根据所述历史交互数据计算反映所述各智能体与环境交互过程的信念状态向量;第二计算单元,其用于响应于满足预定约束条件,基于所述信念状态向量、所述未来状态信息和所述奖励值计算后见向量,以确定与多智能体强化学习相关的后见价值函数;以及强化学习单元,其用于将所述后见价值函数作为多智能体强化学习中的新基线,以实现多智能体强化学习。
17、在第三方面中,本技术提供一种用于多智能体强化学习的设备,包括:处理器;以及存储器,其中存储有用于多智能体强化学习的程序指令,当所述程序指令由所述处理器执行时,使得所述设备实现前述第一方面中的多个实施例。
18、在第四方面中,本技术提供一种计算机可读存储介质,其上存储有用于多智能体强化学习的计算机可读指令,该计算机可读指令被一个或多个处理器执行时,实现前述第一方面中的多个实施例。
19、通过如上所提供的用于多智能体强化学习的方案,本技术实施例通过历史交互数据确定各智能体与环境交互过程的信念状态向量,并结合未来状态信息和奖励值计算后见向量,并确定后见价值函数。即,本技术实施例考虑了多个智能体的整个交互过程以及其他智能体的行为,形成后见价值函数。接着,将后见价值函数作为多智能体强化学习中的新基线,以实现多智能体强化学习。基于此,可以消除其他智能体的行为对累积奖励的影响,从而能够降低梯度估计的方差,提高采样效率和性能。进一步地,本技术实施例通过多个网络构建了后见价值函数的学习框架,使其独立于智能体的当前动作,以确保梯度估计的近似无偏性。
- 还没有人留言评论。精彩留言会获得点赞!