一种基于知识蒸馏轻量化的方面级情感分类方法
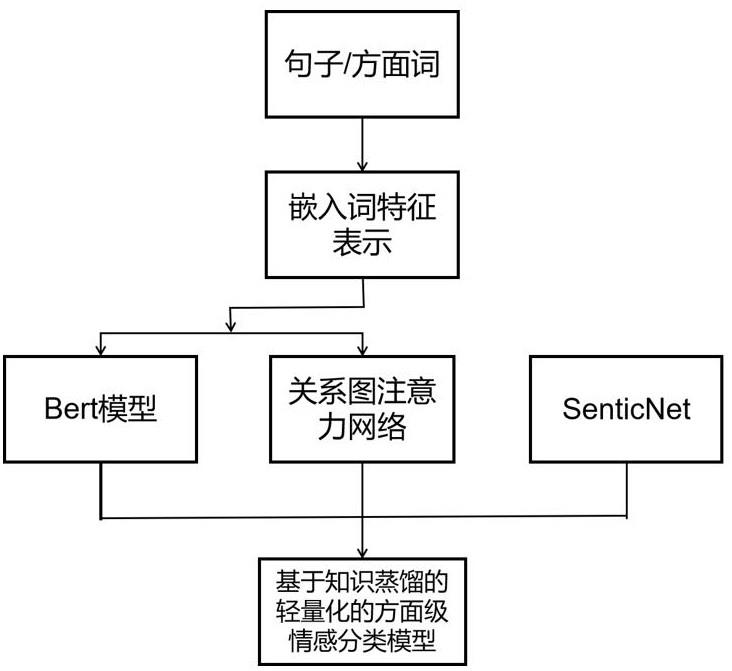
本发明涉及方面级情感分类,尤其是一种基于知识蒸馏的轻量化的方面级情感分类方法。
背景技术:
1、方面级情感分析是人工智能领域一项具有挑战性和实用性的任务,是在句子分析中细粒度的任务,属于一种自然语言处理任务。方面级情感分类(aspect-based sentimentclassification,absc)是方面级情感分析的子任务,是用于对句子中的特定方面词进行情感分类的任务。方面级情感分类是指:给定一个句子和句子中的某个方面词,方面级情感分类的目标是结合句子的上下文和方面词信息,通过对方面词的上下文进行特征表示以及分类来获得该方面词的情感极性。
2、方面级情感分类早期的研究主要采用传统的机器学习方法和简单的神经网络组合。例如通过手工设计的依存规则来获得与方面词相关的词,然后将这些词输入机器学习svm模型中来推断情感极性;又例如基于简单关系网络的方法,使用递归神经网络模型层次化地编码词向量表示,然后使用传统的条件随机场预测最终的答案。这些基于简单特征组合的模型往往无法很好地提取方面词与上文之间的关系,实际模型表现不佳。
3、近几年研究者们也设计了一些新颖的算法来提升方面词情感分类任务的性能。例如采用基于注意力机制的网络模型来对方面词的上下文赋以权重,来实现上下文重要信息的提取;也有方法使用基于依存树的图网络模型,使用依存树加入语法关系信息便于寻找远距离长程依赖;还有方法使用巨大的预训练语言模型例如bert拥有从大量的语料库中学来的知识。上述方法在情感预测准确率上得到了很大的提升,但是在资源受限的设备中部署较为困难。
4、现有技术的方面级情感分类存在着模型参数量大,对存储容量和计算性能的要求高,模型运行时延长,在资源受限的设备中部署较为困难。
技术实现思路
1、本发明的目的是针对现有技术的不足而提供的一种基于知识蒸馏轻量化的方面级情感分类的方法,采用基于一阶谓词逻辑构建轻量化的方面级情感分类模型的方法,向模型中融入了语法关系、情感知识等外部信息,使用基于响应的知识蒸馏、基于特征的知识蒸馏来优化分类模型的效果,更好地挖掘方面词与其上下文之间的依存关系,大大提高了模型的准确率,该具有参数少,逻辑清晰,轻量化的优点,同时融入了语法关系、情感知识等外部信息在一定程度上缓解了轻量化模型因网络深度有限带来的准确率上的影响,方法简便,实用性强,效果好,具有很好的应用前景。
2、实现本发明目的具体技术方案是:一种基于知识蒸馏的轻量化的方面级情感分类的方法,其特点是该方法具体包括以下步骤:
3、步骤1:使用双向长短时记忆网络建模词特征,将词特征表示输入bert模型通过微调得到训练样本的输出,具体如下步骤:
4、1.1:使用预先训练好的glove向量来初始化词嵌入表示。
5、1.2:将词嵌入表示输入到双向长短时记忆网络中,得到的隐层向量表示就是带有上下文信息的词特征表示。
6、1.3:将句子的词嵌入表示按“[cls]sentence[sep]aspect-terms[sep]”的形式输入到bert预训练模型中。
7、1.4:微调bert模型,将训练样本的输出结果记做p1,接下来bert模型将第一个老师使用p1作为训练目标来对关系图注意力模型和轻量化的方面级情感分类模型进行监督。
8、步骤2:使用解析器得到句子的依存树及其邻接矩阵,并在该基础上融入情感知识和方面词信息,具体如下步骤:
9、2.1:使用解析器得到句子的依存树,并根据依存树的连通关系得到0-1邻接矩阵。
10、2.2:利用senticnet向邻接矩阵融入情感信息,邻接矩阵中为1的项如果它两端的节点对应的词包含于senticnet中,则在对应的项上加上该词在senticnet中对应的情感分数。
11、2.3:向邻接矩阵中融入方面词信息,邻接矩阵中为1的项如果它两端其中一个节点对应的词包含于方面词中,则在对应的项上加1。
12、步骤3:将方面词作为根通过对依存树进行剪枝重构,使用多头自注意力机制对带边信息的重构树进行特征融合来提取上下文表示,并融入bert模型的输出进行监督训练,具体如下步骤:
13、3.1:将最开始得到的依存树重构成以方面词为节点的树,将方面词节点作为树的根(如果方面词由多个词组成,则通过双向长短时记忆网络得到方面词整体的特征表示),保留依存树中与方面词直接相连的节点及其边信息,其他与方面词不直接相连的节点使用虚关系n连接(n表示该节点到方面词的相对距离),避免解析器不准确遗漏掉重要的信息。
14、3.2:迭代地更新节点对方面词上下文特征进行特征融合,对得到的重构树的节点使用多头自注意力机制,对及节点之间的边信息映射成向量表示使用多头关系机制,将通过节点聚合得到的向量与通过边关系聚合得到的向量进行连接,使用激活函数(该模型作为第二个老师激活函数中的参数可以和轻量化的方面级情感分类模型共享)将其变换为原来的维度,得到最后更新的节点表示。
15、3.3:沿着重构树的边依次迭代更新各节点,最后取出根结点的上下文特征表示进行softmax得到分类结果,bert模型中的输出结果p1和标签共同作为该模型的训练目标进行监督。
16、步骤4:基于一阶谓词逻辑构造轻量化的方面级情感分类模型,使用基于响应的知识蒸馏、基于特征的知识蒸馏来优化分类模型的效果,具体如下步骤:
17、4.1:使用一阶谓词逻辑构造分类模型,相应谓词的计算模块由简单的神经网络模块构成,谓词表示如下:
18、表示词,a表示方面词;
19、s(x)表示带有情感知识的依存关系;
20、d(x)表示词到方面词的相对距离;
21、k(k,a)表示规则k→a;r(x,a)表示对于特定方面词与之相关的词;
22、则存在
23、4.2:表示句子通过双向长短时记忆网络对应词的隐层输出。
24、4.3:获取句子中带有情感知识的依存关系,即)由下述(a)式表示为:
25、
26、其中,为步骤三中的邻接矩阵,含有被蒸馏出的依存知识、情感常识等信息;w、b与关系图注意网络共享参数,包含了从关系图注意网络中蒸馏出依存关系中边的信息;σ为非线性函数。
27、4.4:将上下文信息根据离方面词的相对距离赋以不同的权重,即),离方面词越近,权重越大,离方面词越远,权重越小。
28、4.5:提取出上下文中与方面词相关的词,即)。
29、4.6:向提取出的上下文中与方面词相关的词中融入之前获得的情感常识、相对距离权重等限制,即)。
30、4.7:最后输入到全连接网络得到情感概率分布。
31、本发明与现有技术相比具有参数少,逻辑清晰,轻量化的优点,能够更好地挖掘方面词与其上下文之间的依存关系,提高了准确率,同时融入了语法关系、情感知识等外部信息在一定程度上缓解了轻量化模型因网络深度有限带来的准确率上的影响,方法简便,实用性强,效果好,具有很好的应用前景。
- 还没有人留言评论。精彩留言会获得点赞!