一种基于Transformer的井下低光照图像增强方法与流程
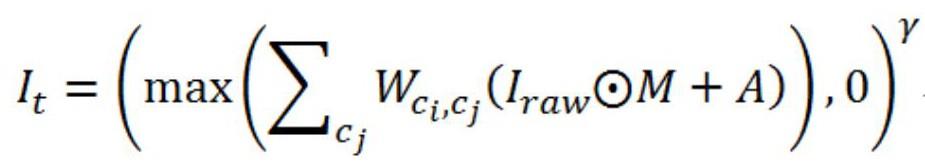
本发明涉及计算机视觉,具体涉及一种基于transformer的井下低光照图像增强方法。
背景技术:
1、transformer最初应用于自然语言处理任务,受其启发,transformer被扩展到视觉计算领域。transformer代替卷积神经网络成为视觉应用的基本组件,并应用到各种视觉计算任务中。transformer因其优异性能被广泛应用到视觉计算,其主要特点有:(1)强序列建模能力,从空间维度上看,图像在空间上被划分为多个区域(block),将一幅图像转化成一个按照空间顺序排列的 block 集合,保证了不丢失视觉信息;从时间维度上看,视频是由图像帧组成,将每一帧图像看作一个基本单元,根据时间序列把每个基本单元组织起来,应用transformer进行后续的特征提取。(2)可以感知全局信息,相较于卷积神经网络的感知信息只能从局部开始,transformer 从输入开始,每一层结构都可以感知所有的信息,建立基本单元之间的关联,意味着transformer 能够处理更加复杂的问题。
2、目前,图像增强方法大多针对光源相对良好、质量较高的图像进行增强处理,然而针对井下低光照图像进行图像增强的方法通用性低,泛化能力弱,结构复杂。因此,搭建一个针对井下低光照图像、通用性高、建模能力强、泛化能力好且结构轻量化的图像增强算法模型对监测井下安全有重要意义。
技术实现思路
1、本发明的目的是要提供一种针对井下低光照图像进行亮度增强的方法,以克服在进行井下低光照图像增强时容易出现颜色失真、细节丢失等图像问题,并实现模型整体轻量化、通用性强、泛化能力好的算法模型,使对井下低光照图像增强效果得到提高。
2、为解决上述技术问题,本发明提出一种基于transformer的井下低光照图像增强方法,其步骤如下:
3、步骤1)获取煤矿井下低光照红绿蓝rgb格式的图像i,将所述图像i的格式转化为原始rawrgb,得到图像iraw,其中所述图像i是在所述煤矿井下光照强度小于设定强度阈值的条件下采集得到的;
4、步骤2)搭建基于移动视觉转换器mobilevit模块的两个分支,并采用所述mobilevit 模块的两个分支,基于所述图像iraw,预测乘法图m与加法图a;
5、步骤3) 搭建基于交叉注意力cross attention模块的支路,采用所述crossattention模块的支路,基于所述图像iraw,得到3×3的最终色彩矩阵和参数;
6、步骤4)根据所述图像iraw、所述乘法图m、所述加法图a、所述最终色彩矩阵和所述参数,建立图像增强数学模型,以得到增强后的图像。
7、可选地,rawrgb格式的所述图像iraw是相机内部最原始的图像,所述图像iraw中每个像素包括红r、绿g、蓝b中的一种颜色;rgb格式的所述图像i是相机通过内部图像信号处理isp模块对所述图像iraw进行计算得到的;所述步骤1)的具体过程为:
8、步骤11)对于所述图像i,按照设定的映射原则,将所述图像i逆映射为所述图像iraw;其中,所述映射原则包括:在所述图像iraw中的第一像素点的颜色为r时,将所述图像iraw中所述第一像素点的邻域内的颜色为g的像素点的像素值的平均值,作为所述图像i中与所述第一像素点对应的第二像素点的g的像素值,将所述图像iraw中所述第一像素点的邻域内的颜色为b的像素点的像素值的平均值,作为所述图像i中与所述第一像素点对应的第二像素点的b的像素值;其中,所述第二像素点的r的像素值与所述第一像素点的r的像素值相同;在所述第一像素点的颜色为g时,将所述图像iraw中所述第一像素点的邻域内的颜色为r的像素点的像素值的平均值,作为所述图像i中与所述第一像素点对应的第二像素点的r的像素点的像素值,将所述图像iraw中所述第一像素点的邻域内的颜色为b的像素点的像素值的平均值,作为所述图像i中与所述第一像素点对应的第二像素点的b的像素值;其中,所述第二像素点的g的像素值与所述第一像素点的g的像素值相同;在所述第一像素点颜色为b时,将所述图像iraw中所述第一像素点的邻域内的颜色为r的像素点的像素值的平均值,作为所述图像i中与所述第一像素点对应的第二像素点的r的像素值,将所述图像iraw中所述第一像素点的邻域内的颜色为g的像素点的像素值的平均值,作为所述图像i中与所述第一像素点对应的第二像素点的g的像素值;其中,所述第二像素点的b的像素值与所述第一像素点的b的像素值相同。
9、可选地,所述步骤2)的具体过程为:
10、步骤21)采用3×3的卷积核对所述图像iraw进行通道维度扩展,以得到扩展通道维度后的图像iraw;
11、步骤22)搭建跳跃连接的两个分支,并采用两个所述分支对步骤21)中的所述扩展通道维度后的图像iraw进行处理,以得到两个所述分支分别输出的特征图,其中,每个所述分支包括三个所述mobilevit模块;
12、步骤23) 将步骤22)两个所述分支输出的特征图,分别通过一个3×3的卷积核,以得到所述乘法图m和所述加法图a。
13、可选地,所述步骤3)的具体过程为:
14、步骤31)通过2个堆叠的3×3的卷积核对所述图像iraw进行处理,得到编码结果;
15、步骤32)将步骤31)的所述编码结果,通过所述cross attention模块,以得到所述cross attention模块输出的3×3的色彩矩阵和参数gamma;
16、步骤33)将所述色彩矩阵和所述参数gamma分别输入至1×1的卷积核,以得到最终色彩矩阵和参数。
17、可选地,所述步骤4)的具体过程为:
18、根据所述图像iraw、所述乘法图m、所述加法图a、所述最终色彩矩阵和所述参数,建立图像增强数学模型:
19、
20、式中:为增强后的图像,。
21、可选地,所述步骤22)的具体过程如下:
22、步骤221)将所述扩展通道维度后的图像iraw,作为各所述分支的输入张量,并利用各所述分支中的三个mobilevit模块对所述输入张量的局部信息和全部信息进行建模,以得到各所述分支中所述输入张量的局部特征图和全局特征图;
23、步骤222)对步骤221)中的各所述分支中所述输入张量的局部特征图和全局特征图进行融合,以得到各所述分支输出的特征图。
24、可选地,所述乘法图m和所述加法图a是通过两个所述分支中的三个所述mobilevit模块预测得到的图像,所述乘法图m,用于将所述乘法图m与所述图像iraw进行乘法运算,以将所述乘法图m和所述图像iraw对应的灰度值或彩色分量进行相乘,用于所述图像iraw的掩膜处理,抑制所述图像iraw的部分区域,得到掩膜图像,其中,对于所述图像iraw中保留下来的第一区域,将所述掩膜图像中所述第一区域的值置为1,对于所述图像iraw中被抑制的第二区域,将所述掩膜图像中所述第二区域的值置为0;其中,响应于对所述图像iraw的亮度进行增强,设置所述掩膜图像的值大于1;所述加法图a,用于将所述加法图a与所述图像iraw与所述乘法图m相乘后得到的图像相加,其中,所述相加的过程为:将所述加法图a与所述相乘后得到的图像中对应像素的灰度值或彩色分量进行相加,以通过叠加相同的图像,对所述图像iraw进行去噪。
25、可选地,各所述mobilevit模块中包括tramsformer子模块,所述transformer子模块是由编码器encoder和解码器decoder组成,encoder和decoder主要由自注意力网络selfattention和前馈网络两个组件构成;其中,所述encoder由多头注意力层multi headattention ->残差&标准化层add&norm ->前馈网络->add&norm组成,add&norm层有经过multi head attention处理和直接输入两个输入路径,其公式如下:layernorm(x+multiheadattention(x));layernorm(x+feedforward(x));其中,x+multiheadattention(x)和x+feedforward(x) 是残差网络结构,layernorm将每一层的神经元的输入进行均值和方差;其中,所述decoder包含两个multi head attention层,第一个multi headattention层采用了掩码masked操作,第二个multi head attention层的key矩阵和value矩阵使用编码器输出的编码信息矩阵进行计算,query矩阵使用所述第一个multi headattention层的输出值进行计算,最后采用激活 softmax 层对所述第二个multi headattention层的输出值进行激活。
26、可选地,所述cross attention模块是将所述cross attention的源端得到的selfattention加入到所述cross attention的目标端得到的attention中,所述crossattention输入的query来自所述源端得到的self attention的输出,而key和value来自transformer子模块的编码器的输入,并将所述cross attention作为所述transformer子模块的解码器。
27、本发明的技术方案取得了如下有益的技术效果:
28、本发明方法利用transformer作为核心模型,在此模型基础上搭建以mobilevit为核心的分支模块,构建了一个轻量级通用且对移动设备友好的网络,使整个算法有优秀的泛化能力和鲁棒性,同时在借鉴目标检测detection transformer中动态query学习策略,采用attention模块获取全局信息产生彩色矩阵以及参数值来完成图像增强任务。
29、本发明附加的方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
- 还没有人留言评论。精彩留言会获得点赞!