一种仿真度高的三维虚拟形象口型匹配方法、介质及系统与流程
本发明属于三维虚拟,具体而言,涉及一种仿真度高的三维虚拟形象口型匹配方法、介质及系统。
背景技术:
1、口型是角色面部动画的关键视点,口型动画是否逼真、自然直接影响到角色面部整体动画的真实度,因此,口型动画的制作在电影、游戏以及虚拟现实等人机交互方式中占据着重要地位。
2、现有技术中,多数采用音素口型法进行三维虚拟形象的口型匹配,由于人类语言中的每个发音的口型与发音拆解为音素的口型存在一定的区别,导致三维虚拟形象发音不流畅;另外平面口型简单转化为三维口型过程中存在不自然的现象。
3、本技术人申请的一项中国发明专利,公告号为cn115690280b,申请号为cn202211687841.5,公开了一种三维形象发音口型模拟方法,具体步骤包括:在测试人员嘴部粘贴多个小色块,测试人员朗读文本,采集测试人员的朗读录像;对朗读录像按照音频中的音素进行拆分,得到音素录像集并处理得到相邻录像对应的音素变化过程的小色块运动轨迹记为音素变化小色块轨迹集;建立三维虚拟人嘴部模型,并根据单音素小色块稳定坐标集建立每个音素对应的口型模型;根据需要读取的文本,建立口型模型序列,并对所述口型模型序列中相邻的口型,以音素变化小色块轨迹集构建口型变动过程。
4、上述专利中,采用测试人员朗读文本的方法,利用三台摄像机进行录像进行采集口型,这一过程采集工作量极大。
技术实现思路
1、有鉴于此,本发明提供一种仿真度高的三维虚拟形象口型匹配方法、介质及系统,能够解决现有技术中,多数采用音素口型法进行三维虚拟形象的口型匹配,由于人类语言中的每个发音的口型与发音拆解为音素的口型存在一定的区别,导致三维虚拟形象发音不流畅的技术问题。
2、本发明是这样实现的:
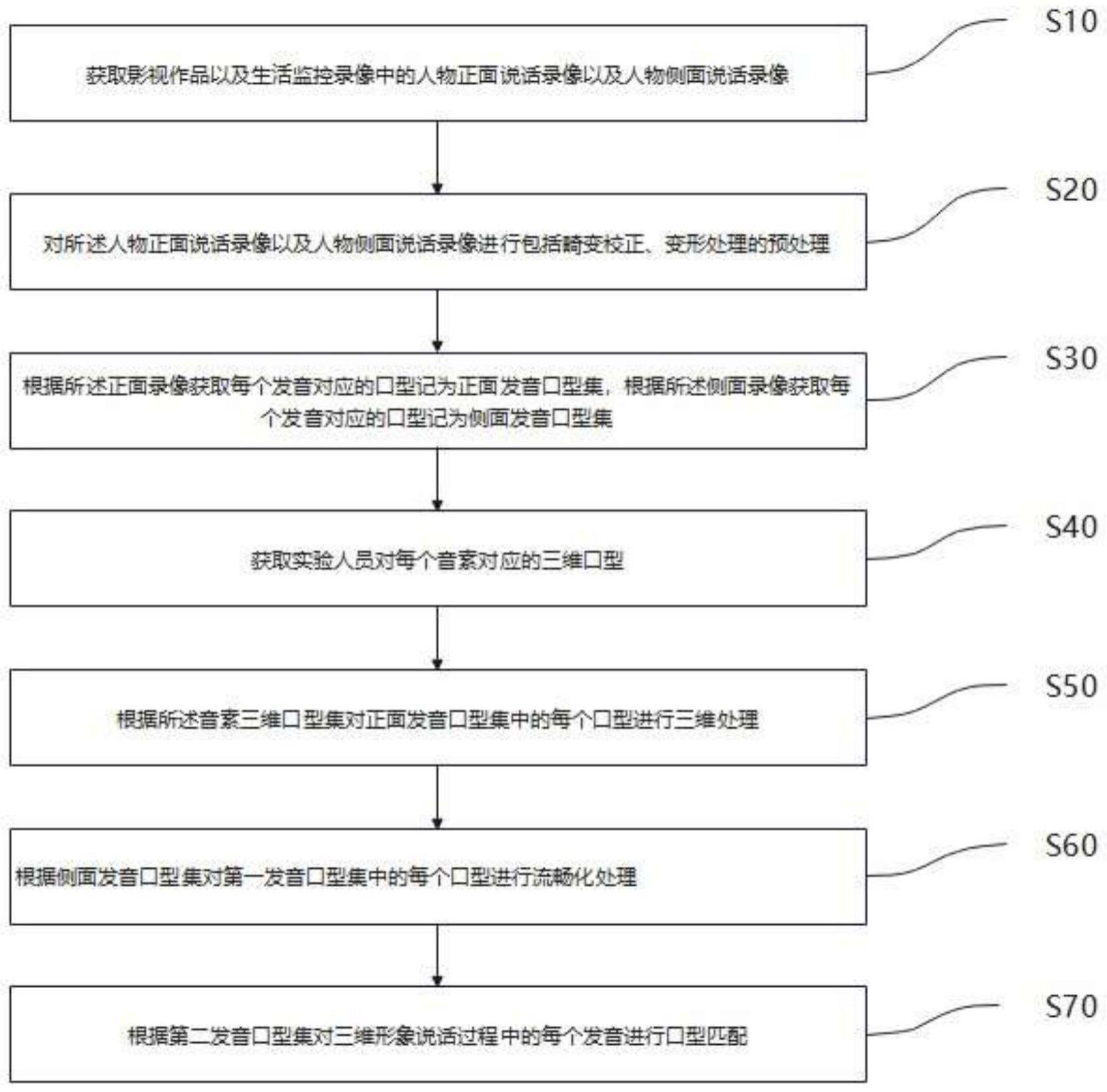
3、本发明的第一方面提供一种仿真度高的三维虚拟形象口型匹配方法,其中,包括以下步骤:
4、s10:获取影视作品以及生活监控录像中的人物正面说话录像以及人物侧面说话录像,其中所述人物正面说话录像为所述人物的全部嘴部区域均能显示的连续帧组成的录像;所述人物侧面说话录像为所述人物的全部嘴部区域部分显示的连续帧组成的录像;
5、s20:对所述人物正面说话录像以及人物侧面说话录像进行畸变校正得到正面录像以及侧面录像;
6、s30:根据所述正面录像获取每个发音对应的口型记为正面发音口型集,根据所述侧面录像获取每个发音对应的口型记为侧面发音口型集;
7、s40:获取实验人员对每个音素对应的三维口型,记为音素三维口型集;
8、s50:根据所述音素三维口型集对正面发音口型集中的每个口型进行三维处理,得到第一发音口型集;
9、s60:根据侧面发音口型集对第一发音口型集中的每个口型进行流畅化处理,得到第二发音口型集;
10、s70:根据第二发音口型集对三维形象说话过程中的每个发音进行口型匹配,生成三维形象说话口型序列。
11、本发明提供的一种仿真度高的三维虚拟形象口型匹配方法的技术效果如下:通过采集影视作品以及生活监控录像中的人物正面说话录像以及人物侧面说话录像,可以低成本的获得大量的人物说话录像,无需对每个口型进行实验人员采集;对每个音素的三维口型进行实验人员采集,并采用得到的音素三维口型对正面发音口型集中的每个口型进行三维处理,可以将正面发音口型由二维转换为三维;利用侧面发音口型对第一发音口型集进行处理,使得口型更加流畅。
12、在上述技术方案的基础上,本发明的一种仿真度高的三维虚拟形象口型匹配方法还可以做如下改进:
13、其中,根据所述正面录像获取每个发音对应的口型记为正面发音口型集的步骤,具体包括:
14、提取正面发音口型集的音频,记为正面音频;
15、在所述正面音频中,提取反映所述正面音频的语音信号幅值变化趋势的波峰点连接所形成的正面波峰曲线;
16、对所述正面波峰曲线进行平滑及归一化处理得到第一正面曲线;
17、对所述第一正面曲线进行幅值切割,得到多个曲线段的集合,记为第一正面曲线段集;
18、以所述第一正面曲线段集中的曲线段作为每个发音对应的语音信号,所述语音信号的起止时间为所述发音对应的起止时间;
19、根据所述发音对应的起止时间,将所述正面录像分割为多个正面发音口型集。
20、进一步的,所述对曲线进行幅值切割得到多个曲线段的集合的步骤,具体包括:
21、获取所述曲线的波谷;
22、以所述波谷所在点为切割点,对所述曲线进行幅值切割,得到多个曲线段的集合。
23、其中,根据所述侧面录像获取每个发音对应的口型记为侧面发音口型集的步骤,具体包括:
24、提取侧面发音口型集的音频,记为侧面音频;
25、在所述侧面音频中,提取反映所述侧面音频的语音信号幅值变化趋势的波峰点连接所形成的侧面波峰曲线;
26、对所述侧面波峰曲线进行平滑及归一化处理得到第一侧面曲线;
27、对所述第一侧面曲线进行幅值切割,得到多个曲线段的集合,记为第一侧面曲线段集;
28、以所述第一侧面曲线段集中的曲线段作为每个发音对应的语音信号,所述语音信号的起止时间为所述发音对应的起止时间;
29、根据所述发音对应的起止时间,将所述侧面录像分割为多个侧面发音口型集。
30、进一步的,所述获取实验人员对每个音素对应的三维口型的步骤,具体包括:
31、获取激光扫描仪对实验人员朗读文本过程中对应的激光数据;
32、根据所述激光数据建立点云模型;
33、所述点云模型中的点至少包括dlib面部识别算法中嘴部对应的关键点;
34、根据所述点云模型得到每个音素对应的三维口型;
35、所述实验人员朗读的文本为所有音素的集合,所述实验人员对每个音素进行逐一间隔朗读。
36、进一步的,根据所述点云模型得到每个音素对应的三维口型的具体步骤,包括:
37、将点云模型中的关键点进行筛选,仅保留dlib面部识别算法中嘴部对应的关键点,作为口型点云模型;
38、获取所述实验人员朗读的每个音素对应的口型点云模型作为三维口型。
39、其中,根据所述音素三维口型集对正面发音口型集中的每个口型进行三维处理得到第一发音口型集的步骤,具体包括:
40、对所述正面发音口型集中每个口型获取对应的音素;
41、根据对应的音素获取所述三维口型集中对应的三维口型;
42、利用对应的三维口型对所述正面发音口型集中每个口型进行三维处理,具体包括:
43、获取每个口型的dlib面部识别算法中嘴部对应的关键点;
44、对每个关键点的三维坐标根据三维口型中对应关键点的三维坐标进行调整。
45、其中,所述根据侧面发音口型集对第一发音口型集中的每个口型进行流畅化处理得到第二发音口型集的步骤,具体包括:
46、对所述第一发音口型集中每个口型获取对应的音素;
47、根据对应的音素获取所述侧面发音口型集中对应的侧面口型;
48、利用对应的侧面口型对所述第一发音口型集中每个口型进行三维处理,具体包括:
49、获取第一发音口型集中每个口型的dlib面部识别算法中嘴部对应的关键点;
50、对每个关键点的三维坐标根据对应的侧面口型中对应关键点的三维坐标进行调整。
51、本发明的第二方面提供一种计算机可读存储介质,其中,所述计算机可读存储介质中存储有程序指令,所述程序指令运行时用于执行上述的一种仿真度高的三维虚拟形象口型匹配方法。
52、本发明的第三方面提供一种仿真度高的三维虚拟形象口型匹配系统,其中,所述一种仿真度高的三维虚拟形象口型匹配系统包括上述的计算机可读存储介质。
53、与现有技术相比较,本发明提供的一种仿真度高的三维虚拟形象口型匹配方法、介质及系统的有益效果是:
54、1.对每个音素的三维口型进行实验人员采集,并采用得到的音素三维口型对正面发音口型集中的每个口型进行三维处理,可以将正面发音口型由二维转换为三维;利用侧面发音口型对第一发音口型集进行处理,使得口型更加流畅,避免了现有技术中平面口型简单转化为三维口型过程中存在不自然的现象。
55、2.通过采集影视作品以及生活监控录像中的人物正面说话录像以及人物侧面说话录像,可以低成本的获得大量的人物说话录像,无需对每个口型进行实验人员采集。
- 还没有人留言评论。精彩留言会获得点赞!