一种基于动态注意力的密集型LSTM残差网络去噪方法
本发明属于计算机视觉和图像处理领域,具体涉及到一种基于动态注意力的密集型lstm残差网络去噪方法。
背景技术:
1、近年来,随着信息化社会的不断发展,图像信息已经成为人们接收信息的一种主要方式。数字图像在采集、传输过程中受环境、设备、人为因素等影响,不可避免的引入噪声,从而降低图像质量,影响图像的可读性。图像去噪是提高图像质量非常重要的方法之一。多年来,图像去噪被运用于多种领域中。例如,在医疗领域,对含有噪声的医疗图像进行去噪处理,来提高图像的清晰度,从而帮助医护人员能更好的判断病人情况;在航空航天等领域,图像在成像过程中常常会受到电子设备的干扰,导致图像含有高斯白噪声、椒盐噪声等等,需要通过图像去噪进行改善。手持移动设备或者车载记录仪在夜间拍摄时因为光线、环境等因素常常会产生噪声,影响图像质量从而给后续的图像分析和处理带来诸多不便,同时去噪便于后续处理图像的分类、分割及识别等任务。
2、图像去噪是图像处理领域中的经典问题,同时也是计算机视觉的重要预处理步骤。传统图像去噪算法依赖于较强的先验模型假设以及人工调参,涉及到复杂的优化问题,需要花费大量的时间和成本。随着近年来,深度学习理论的不断完善,相关专家学者成功将其应用于图像去噪领域,并获得了优异的成果。深度神经网络通过卷积、激活等操作有效的从图像中提取的特征信息,对图像去噪研究贡献颇多。当前,注意力机制常被用于卷积神经网络的搭建,广泛应用于自然语言理解、图像去噪和识别等领域。虽然注意力机制能提高卷积神经网络的去噪效果,但是需要人工设置注意力模块在卷积神经网络中的位置,并且不同位置上作用强度也不同,这导致想要通过注意力机制有效提高网络性能需要对不同网络结构进行多次试验,大大增加了人力成本。
技术实现思路
1、为解决上述技术问题,本发明提供了一种基于动态注意力的密集型lstm残差网络去噪方法,通过考虑空间注意力权重和通道间注意力权重,从而更好的指导网络进行去噪,并保证了图像的去噪质量。通过设计lstm结构,兼顾了全局信息与局部信息的依赖性,此方法对降噪性能和成像质量有显著的提升。
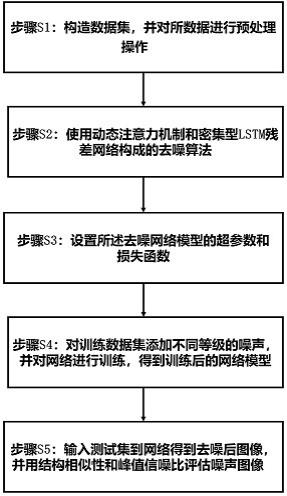
2、一种基于动态注意力的密集型lstm残差网络去噪方法,其特征在于:包括如下步骤:
3、步骤s1,构造训练数据集,并对所述数据集进行预处理操作;
4、步骤s2,建立动态注意力机制和密集型lstm残差网络构成的去噪网络模型;
5、步骤s3,设置去噪网络模型的超参数和损失函数;
6、步骤s4,对训练数据集添加不同等级的噪声,并对网络进行训练,得到训练后的去噪网络模型;
7、步骤s5,输入测试集到训练后的去噪网络模型,得到去噪后图像,并用结构相似性和峰值信噪比评估噪声图像(把待评估图像即网络模型输出的去噪后图像和原始图像代入计算公式进行评估即可);将通过评估的去噪网络模型投入使用,输入待处理图像,输出去噪后的图像。
8、进一步地,步骤s1中,对训练数据集进行预处理操作包括如下步骤:
9、s1.1),从所述训练数据集中选取训练样本作为原始训练集,其中,所述训练样本中的图像均为尺寸相同的无噪声图像;
10、s1.2),将训练数据集中的图像分别按照1倍、0.9倍、0.8倍、0.7倍的缩放,并使用滑动固定大小的分割窗口将缩放后的每个图像进行分割;
11、s1.3),将分割后的图像进行增广操作,所述的增广操作的方法包括:对图像进行上下翻转、90°旋转、180°旋转、270°旋转、上下翻转后90°旋转、上下翻转后180°旋转、上下翻转后270°旋转;
12、进一步地,步骤s2中,去噪网络模型由卷积、lrelu以及8个动态注意力模块构成,其中动态注意力模块包括前端和后端的残差单元、非注意力分支、注意力分支和权重分配分支,并在动态注意力模块内部采用lstm结构,网络模型内部所用卷积核大小为3×3和5×5。
13、进一步地,所述前端和后端的残差单元为残差模块,该模块由2个卷积核大小为3×3的卷积层和lrelu激活函数构成,设y为输入,数学表达式如下:
14、x0=ψ(w2*ψ(w1*y+b1)+b2)
15、上式中w1和w2表示输出通道为64的3×3卷积层,b1和b2为偏置,ψ表示lrelu激活函数,x0表示提取的浅层特征;
16、定义xi-1表示动态注意力模块的输入;前端特征提取部分由1个残差模块和lrelu激活函数组成,对应的数学表达式为:
17、
18、式中表示e残差模块;接着,将分别输入注意力分支、非注意分支。
19、进一步地,所述非注意力分支由2个残差单元、1个lstm模块组成主干网络,其中残差单元包含1个3×3卷积层和1个5×5卷积层,lstm模块由残差模块、lstm单元、卷积层和注意力掩模层组成的循环网络结构;lstm单元数学表达式如下
20、it=σ(wxi*xt+whi*ht-1+wci⊙ct-1+bi)
21、ft=σ(wxf*xt+whf*ht-1+wcf⊙ct-1+bf)
22、ct=ft⊙ct-1+it⊙tanh(wxc*xt+whc*ht-1+bc)
23、ot=σ(wxo*xt+who*ht-1+wco⊙ct+bo)
24、ht=ot⊙tanh(ct)
25、其中lstm由输入门it、遗忘门ft、输出门ot、长时记忆状态ct和短时记忆状态ht组成;σ和tanh分别表示sigmoid激活函数和tanh激活函数,wjk表示从j到k卷积操作,⊙表示矩阵点乘,bj表示第j单元的激活值;xt表示由残差模块获得的特征图,ct对送到下一个lstm的特征进行编码,ht作为当前的lstm单元输出,并输入一下lstm单元。
26、进一步地,所述注意力分支由主干网络bi和掩模部分mi组成,表示为:
27、
28、上式中fatt表示注意力分支,i表示第i个动态注意力模块,主干网络bi包含2个残差模块,掩模部分mi包含空洞卷积、通道注意力模块、下采样操作、上采样操作以及sigmoid函数。
29、进一步地,所述权重分配分支由空间注意力模块、通道注意力模块构成,其中空间注意力模块包括了一对最大池化操作和平均池化操作,特征图分别经过两种池化操作后拼接成一个大特征图,之后由sigmoid激活函数得到空间上的权重,并输入到通道注意力模块;通道注意力模块由平均池化层、两层线性层和softmax激活函数构成,最终将产出动态注意力权重分布用于非注意分支和注意力分支。
30、进一步地,步骤s3中,去噪网络模型的超参数包括批大小、初始学习率、迭代次数、学习率衰减策略;损失函数为均方差误差,其数学表达式为:
31、
32、式中,θ为动态注意力机制的密集型lstm残差网络参数,r(yi;θ)为网络学习到的残差图像,yi为噪声图像,xi代表干净图像,n为训练样本数;采用train400数据集作为训练数据集,每个轮次随机提取40个尺寸为128×128的图像块作为样本,并采用adam优化器进行训练,初始学习率设为1×10-4,每10轮学习率下降0.2倍,网络共计训练100轮。
33、进一步地,在步骤s4中,去噪网络模型的训练方法为:
34、s4.1),将原始数据训练集中的图像分别添加噪声等级为15、25、50的高斯白噪声;
35、s4.2),将加入噪声的训练图像输入到所述网络模型中进行训练,从而得到训练好的去噪网络模型,并对其进行保存。具体训练步骤就是通过运行pycharm实现。
36、进一步地,步骤s5中,结构相似性的计算公式为:
37、
38、其中x和y为两幅图像,为均值;为方差;σxy是x和y的协方差;d1=(k1l)2,d2=(k2l)2,l是像素的动态范围;k1=0.01,k2=0.03;
39、峰值信噪比的计算公式为:
40、
41、式中:x(i,j)和y(i,j)分别代表了初始图像x(i,j)和去噪后的图像y(i,j)中相对应位置的像素值,q表示图像中最大灰度值。
42、本发明达到的有益效果为:
43、(1)通过考虑空间注意力权重和通道间注意力权重,从而更好的指导网络进行去噪,并保证了图像的去噪质量。
44、(2)通过设计lstm结构,兼顾了全局信息与局部信息的依赖性,此方法对降噪性能和成像质量有显著的提升。
45、(3)有利于为后续的图像分类、分割、识别与跟踪等高层图像理解与分析任务。
- 还没有人留言评论。精彩留言会获得点赞!