用于神经网络加速器的数据处理方法、芯片及电子设备与流程
本发明涉及芯片领域,尤其涉及一种用于神经网络加速器的数据处理方法、芯片及电子设备。
背景技术:
1、人工神经网络(artificial neural networks,简写为anns)也简称为神经网络(nns)或称作连接模型(connection model),它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。卷积神经网络(convolutional neuralnetworks, cnn)是一类包含卷积计算且具有深度结构的前馈神经网络(feedforwardneural networks),是深度学习(deep learning)的代表算法之一。
2、随着人工智能技术的发展,诸如人工神经网络和卷积神经网络处理的数据量成倍增长,对包含神经网络加速器(npu,也称神经网络处理器)的芯片的性能需求越来越高。
3、现有技术在相关芯片中,为了实现对至少两种特征图(feature map)的拼接,通常设置有拼接层专用电路模块。然而,拼接层专用电路模块一方面会占用芯片的有限空间,另一方面则增加了拼接层专用电路模块与其他模块之间的数据搬运,产生较高的功耗。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种用于神经网络加速器的数据处理方法、芯片及电子设备,以减少数据搬运,降低神经网络加速器的功耗且减少芯片的面积。
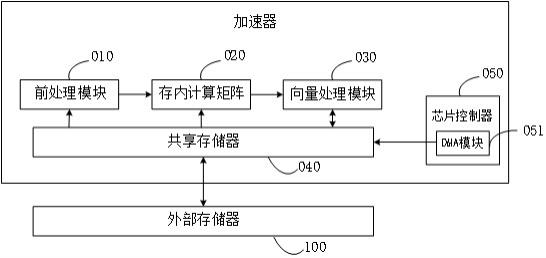
2、一种用于神经网络加速器芯片的数据处理方法,所述神经网络加速器包括:依次电连接的前处理模块、存内计算矩阵和向量处理模块;以及分别与所述前处理模块、所述存内计算矩阵和所述向量处理模块电连接的共享存储器;与所述共享存储器电连接的芯片控制器;
3、所述数据处理方法包括:
4、通过所述前处理模块从所述共享存储器获取输入特征图数据及将所述输入特征图数据处理为存内计算矩阵格式的矩阵数据,将所述矩阵数据输入所述存内计算矩阵;其中,若所述输入特征图数据包括至少两个输入特征图,且所述至少两个输入特征图以跳地址方式存储在所述共享存储器上,则所述前处理模块以按地址顺序读取的方式从所述共享存储器获取所述至少两个输入特征图;或,若所述输入特征图数据包括至少两个输入特征图,且所述至少两个输入特征图以连续存储方式存储在所述共享存储器上,则所述前处理模块以跳地址读取的方式从所述共享存储器获取所述至少两个输入特征图;
5、通过所述存内计算矩阵获取权重数据,通过所述存内计算矩阵根据所述矩阵数据和所述权重数据进行卷积计算得到计算结果,将所述计算结果输入所述向量处理模块;
6、通过所述向量处理模块处理所述计算结果,得到输出特征图数据,将得到的所述输出特征图数据写入所述共享存储器和/或所述外部存储器;其中,若所述输出特征图数据为中间计算结果,则所述输出特征图数据用作下一层级计算结果的输入数据;
7、在所述前处理模块获取所述输入特征图数据之前,和/或,在所述向量处理模块处理所述计算结果,得到输出特征图数据之后,通过所述芯片控制器控制所述共享存储器与所述外部存储器之间的数据交互,其中,进行交互的数据包括所述输入特征图数据和/或所述输出特征图数据。
8、一种芯片,包括:
9、依次电连接的前处理模块、存内计算矩阵和向量处理模块;以及,
10、分别与所述前处理模块、所述存内计算矩阵和所述向量处理模块电连接的共享存储器;
11、与所述共享存储器电连接的芯片控制器;
12、其中,所述前处理模块,用于从所述共享存储器获取输入特征图数据,将所述输入特征图数据处理为存内计算矩阵格式的矩阵数据,将所述矩阵数据输入所述存内计算矩阵;其中,若所述输入特征图数据包括至少两个输入特征图,且所述至少两个输入特征图以跳地址方式存储在所述共享存储器上,则所述前处理模块以按地址顺序读取的方式从所述共享存储器获取所述至少两个输入特征图;或,若所述输入特征图数据包括至少两个输入特征图,且所述至少两个输入特征图以连续存储方式存储在所述共享存储器上,则所述前处理模块以跳地址读取的方式从所述共享存储器获取所述至少两个输入特征图;
13、所述存内计算矩阵,用于获取权重数据,根据所述矩阵数据和所述权重数据进行卷积计算得到计算结果,将所述计算结果输入所述向量处理模块;
14、所述向量处理模块,用于对所述计算结果进行处理,得到输出特征图数据,将得到的所述输出特征图数据写入所述共享存储器和/或外部存储器,其中,若所述输出特征图数据为中间计算结果,则所述输出特征图数据用作下一层级计算结果的输入数据;
15、所述芯片控制器,用于在所述前处理模块获取所述输入特征图数据之前,和/或,在所述向量处理模块处理所述计算结果,得到输出特征图数据之后,控制所述共享存储器与所述外部存储器之间的数据交互,其中,进行交互的数据包括所述输入特征图数据和/或所述输出特征图数据。
16、一种电子设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机可读指令,所述处理器执行所述计算机可读指令时实现如上述用于神经网络加速器的数据处理方法。
17、上述用于神经网络加速器的数据处理方法、芯片及电子设备,通过所述前处理模块从所述共享存储器获取输入特征图数据,将所述输入特征图数据处理为存内计算矩阵格式的矩阵数据,将所述矩阵数据输入所述存内计算矩阵;其中,若所述输入特征图数据包括至少两个输入特征图,且所述至少两个输入特征图以跳地址方式存储在所述共享存储器上,则所述前处理模块以按地址顺序读取的方式从所述共享存储器获取所述至少两个输入特征图;或,若所述输入特征图数据包括至少两个输入特征图,且所述至少两个输入特征图以连续存储方式存储在所述共享存储器上,则所述前处理模块以跳地址读取的方式从所述共享存储器获取所述至少两个输入特征图,以提高前处理模块的读取效率和读取灵活度,减少数据的搬运次数。通过所述存内计算矩阵获取权重数据,通过所述存内计算矩阵根据所述矩阵数据和所述权重数据进行卷积计算得到计算结果,将所述计算结果输入所述向量处理模块,以减少数据的搬运次数,提高数据处理效率。通过所述向量处理模块处理所述计算结果,得到输出特征图数据,将得到的所述输出特征图数据写入所述共享存储器和/或所述外部存储器;其中,若所述输出特征图数据为中间计算结果,则所述输出特征图数据用作下一层级计算结果的输入数据,以实现输出特征图数据的输出。在所述前处理模块获取所述输入特征图数据之前,和/或,在所述通过所述向量处理模块处理所述计算结果,得到输出特征图数据之后,通过所述芯片控制器控制所述共享存储器与所述外部存储器之间的数据交互,其中,进行交互的数据包括所述输入特征图数据和/或所述输出特征图数据,以确保共享存储器中输入特征图数据和/或输出特征图数据的可用性。本发明实现拼接功能时不用设置拼接层专用电路模块,减少了拼接层专用电路模块的面积占用和功耗占用,可以减少数据搬运,降低神经网络加速器的功耗,进而提高神经网络加速器对应的芯片的能效比和面效比。
- 还没有人留言评论。精彩留言会获得点赞!