基于Schatten-p范数的低秩判别迁移子空间学习方法
本发明涉及数据处理,更具体地说,特别涉及一种基于schatten-p范数的低秩判别迁移子空间学习方法。
背景技术:
1、随着互联网的发展,海量数据使得训练高性能的分类模型成为可能。然而,大多数数据集是无标注的,并且分布不一致。为解决这一问题,无监督领域自适应提供了一种很自然的思路,即将知识从有标签的源域中迁移到无标注的目标域,从而提高对目标域的学习。如今,无监督领域自适应已被广泛应用到计算机视觉、自然语言处理、医疗健康等各个领域。
2、许多专家系统地总结了无监督领域自适应的方法,大致可以分为如下两类。第一类方法是基于分布自适应,它通过变换直接最小化源域和目标域分布差异。而衡量两个域之间的差异又可以通过不同距离来刻画,如最大均值差异散度(mmd)、bregman散度以及kl散度等。基于这些距离,寻求使得源域和目标域分布差异最小的映射函数。经典方法有许多,如迁移成分分析(tca),它将两域数据一起映射到一个高维的再生核希尔伯特空间。在此空间中,通过mmd最小化源域和目标域的数据距离,同时最大程度地保留它们各自的内部属性。此外,基于分布自适应的代表性方法还有联合分布适配(jda)、平衡分布适配(bda)、联合概率分布适配(jpda)等。而第二类方法是基于子空间学习,它假设不同域可以处于同一个公共迁移子空间中。与第一类方法相比,基于子空间学习的方法可以很好保留来自源域的知识,促进目标域挖掘更多的几何结构特征。此外,基于分布自适应的方法不能很好地解决复杂背景下的目标识别问题,并且严重依赖于对分布距离的刻画。
3、迁移子空间学习方法通过分析数据结构来挖掘跨域的共同潜在特征,从而隐式地减少领域之间的差异。这些方法可以也分为两类。第一类方法试图通过流形学习来保持数据的全局和局部结构,如测地线流采样(sgf)和测地线流式核方法(gfk)。sgf假设源域和目标域都是格拉斯曼流形中的一个点,通过两者测地线距离上的d个中间点连接起来形成一条路径,之后通过找到每一步合适的变换来实现源域到目标域的迁移。gfk在sgf基础上进行改进,回答了选取多少个中间点合适。它构造了一个测地线流核模型,通过对无限个子空间进行积分来解决域迁移问题。相比之下,第二类迁移子空间学习方法是通过对齐两域数据的统计特征来实现知识的迁移,例如:子空间对齐(sa)和子空间分布对齐(sda)对齐了源域和目标域的一阶统计量,方差关联对齐(coral)对齐了两域的二阶统计量。然而,由于噪声和异常值的负面影响,仅对齐统计数据生成的模型可能不够鲁棒。为此,shao等人提出了低秩迁移子空间学习(ltsl),它将源域和目标域中数据迁移到统一的广义子空间中,之后通过源域样本实现对目标域样本的线性重构。它指出重构矩阵应该具有块状结构,数学上可以通过施加低秩约束实现这一目的,从而很好的对齐源域和目标域。此外,ltsl引入噪声矩阵,并对其施加l1范数来促进噪声稀疏性,从而提升方法的鲁棒性。xu等人提出的判别迁移子空间学习(dtsl),则指出对重构矩阵施加联合的低秩和稀疏约束可以有效保留域中数据的全局和局部结构。联合特征选择和结构保留方法(fssp)和联合低秩表示和特征选择(jlrfs)两种方法侧重于结合特征选择和子空间对齐,通过对投影矩阵施加l2,1范数来提高其行稀疏特性,从而去除冗余特征。此外,引入图正则化项来更好的保持数据的几何结构。lin等人指出之前算法均采用凸松弛方式来求解原始非凸问题,这可能导致性能偏差,因此使用非凸算子来刻画约束。
4、然而,传统的迁移子空间学习方法在挖掘数据结构和数据鉴别性方面仍然有待提升。具体来说,秩最小化问题是np难的,由于核范数是秩函数在单位球上最紧的凸算子,因此传统方法广泛采用核范数作为秩函数的替代模型。这一策略的主要局限性是核范数会过度惩罚较大的奇异值,导致其解严重偏离最优解。其次,传统方法直接使用源域的严格标签矩阵,这使得模型很容易受到标签噪声的干扰。针对这两大问题,确有必要提出基于schatten-p范数的低秩判别迁移子空间学习方法。
技术实现思路
1、本发明的目的在于提供一种基于schatten-p范数的低秩判别迁移子空间学习方法,以克服现有技术所存在的缺陷。
2、为了达到上述目的,本发明采用的技术方案如下:
3、基于schatten-p范数的低秩判别迁移子空间学习方法,包括以下步骤:
4、s1、基于schatten-p范数构建相似度学习的目标函数;
5、s2、通过非精确增广拉格朗日乘子算法对目标函数进行迭代求解得到投影矩阵p;
6、s3、将源域和目标域数据通过投影矩阵p投影到一公共特征子空间中。
7、进一步地,所述步骤s1的具体方法为:
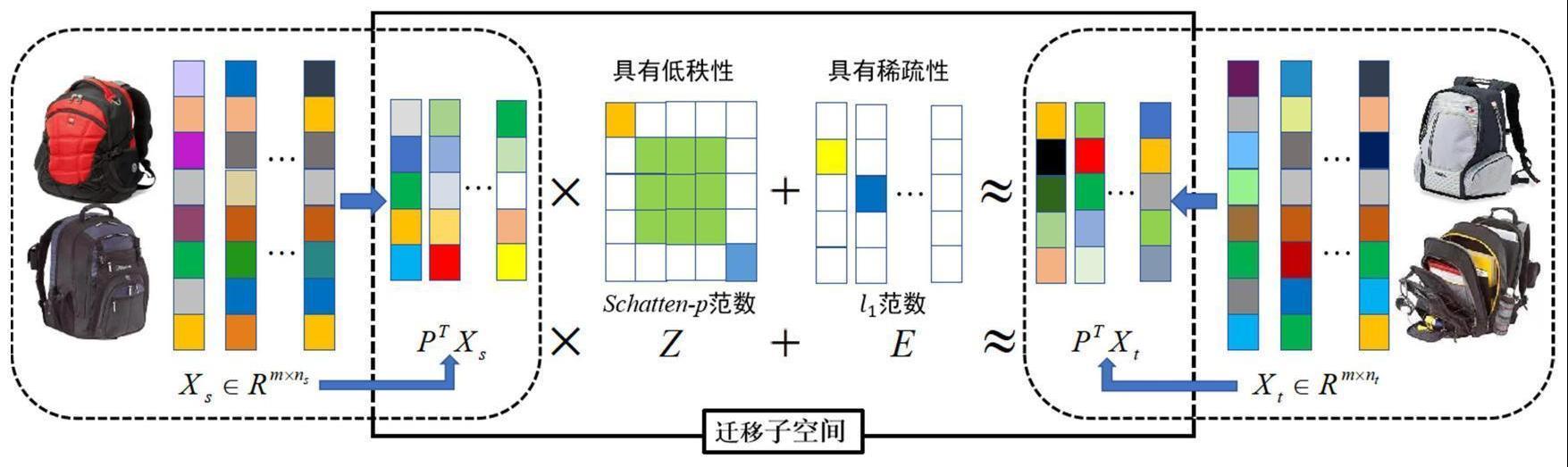
8、s10、将目标域数据由源域数据表示为:
9、ptxt=ptxsz+e
10、式中,pt为投影矩阵p的转置矩阵,p将源域、目标域投影到一公共特征子空间中,z度量子空间中源域和目标域之间数据的相似性,e为噪声矩阵,xt为目标域数据特征,xs为源域数据特征;
11、s11、构建相似度学习的目标函数为:
12、
13、式中,α,β为正则化参数,为矩阵z的第i个最大奇异值σi的0次方,||e||1为噪声矩阵e的l1范数,表示通过调整矩阵p,z,e从而最小化目标函数,s.t.表示目标函数受限于约束条件。
14、s12、将schatten-p范数代入步骤s11中目标函数的表达式中得到:
15、
16、式中,为矩阵z的第i个最大奇异值σi的p次方,ns和nt分别为矩阵z的行数和列数。
17、s13、引入损失将目标函数表示为:
18、
19、s14、引入非负松弛标签矩阵m来松弛源域标签y,得到转换后的松弛标签矩阵为:
20、y°=y+b⊙m;
21、式中,⊙为hadamard算子,矩阵b为:
22、
23、s15、将步骤s14的松弛标签矩阵引入步骤s13中的目标函数得到:
24、
25、进一步地,所述步骤s2具体包括:
26、s20、引入矩阵j,将目标函数转化为:
27、
28、得到模型的拉格朗日函数为:
29、
30、式中,y1,y2为拉格朗日乘数,μ为惩罚因子;
31、s21、固定矩阵z、j、e和m时,更新投影矩阵p;
32、s22、固定矩阵p、j、e和m时,更新重构矩阵z;
33、s23、固定矩阵p、z、e和m时,更新矩阵j;
34、s24、固定矩阵p、z、j和m时,更新矩阵e;
35、s25、固定矩阵p、z、j和e时,更新矩阵m;
36、s26、更新拉格朗日乘数y1,y2以及惩罚因子μ;
37、s27、重复上述步骤s21-s22直至步骤s20中的目标函数满足收敛条件,得到最终的投影矩阵p。
38、进一步地,所述步骤s21具体为:
39、固定矩阵z、j、e和m时,拉格朗日函数为:
40、
41、令上述公式的偏导数为0,得到投影矩阵p的封闭解为:
42、
43、式中,g1=y+b⊙m,g2=xt-xsz,
44、进一步地,所述步骤s22具体为:
45、固定矩阵p、j、e和m时,拉格朗日函数为:
46、
47、令上述公式的偏导数为0,得到重构矩阵z的封闭解为:
48、
49、进一步地,所述步骤s23具体为:
50、固定矩阵p、z、e和m时,拉格朗日函数为:
51、
52、式中,求解得到j的解析解。
53、进一步地,所述步骤s24具体为:
54、固定矩阵p、z、j和m时,拉格朗日函数为:
55、
56、得到矩阵e的迭代解为:
57、
58、进一步地,所述步骤s25具体为:
59、固定矩阵p、z、j和e时,拉格朗日函数为:
60、
61、令r=ptxs-y,上式分解成d×ns个优化问题其中,d,ns分别为非负松弛标签矩阵的行数和列数,优化问题的解为mij=max(rijbij,0),得到矩阵m的闭式解为:
62、m*=max(r⊙b,0)。
63、进一步地,所述步骤s26通过以下公式更新拉格朗日乘数y1,y2以及惩罚因子μ:
64、
65、进一步地,还包括对步骤s20中目标函数增加ptp=i的约束条件,得到更新后的目标函数为:
66、
67、所述步骤s21固定矩阵z、j、e和m,更新投影矩阵p时,上述目标函数转变为以下公式:
68、
69、将上述公式等价改写为:
70、
71、式中,
72、再通过广义幂迭代法进行优化求解得到最优解。
73、与现有技术相比,本发明的优点在于:本发明采用相比于核范数,对秩函数近似更为紧致的schatten-p范数作为代理模型,在设计判别子空间学习函数时,采用松弛标签矩阵,使得投影后数据更好拟合标签,同时扩大不同类别数据之间间隔,提升分类性能。
- 还没有人留言评论。精彩留言会获得点赞!