基于深度强化学习的移动能源网络实时能量管理方法及系统
本发明涉及电气工程与计算机科学领域,具体地,涉及基于深度强化学习的移动能源网络实时能量管理方法。
背景技术:
1、随着减排政策的日趋严格,以电动汽车、电气化船舶、移动储能车为代表的移动能源网络成为交通电气化不可逆转的趋势。得益于电力推进技术与综合电力系统的不断发展,电气化船舶、电动汽车的渗透率正在逐步提升。传统交通工具运行模式中,人为操控起着至关重要的作用,而随着移动能源网络复杂性不断提高,智能化成为移动能源网络发展的必然趋势。
2、目前,移动能源网络的能量管理大多基于对能源和负荷的准确预测,侧重于建立全航程的数学优化模型,未能将航行过程中的实时动态变化因素考虑在内。但实时航行时,由于环境的复杂性和不确定性,移动能源网络自身能源系统和所处环境均处于动态变化的过程中,准确预测在实际场景中很难实现。移动能源网络的实时能量管理系统需增强对负荷变化的适应性和能量调控的灵活性。
3、专利文献cn114498753a(申请号:202210160754.8)公开了一种数据驱动的低碳船舶微电网实时能量管理方法,首先,通过预测误差拟合、等概率逆变换场景集生成、同步回代法场景集削减建立考虑预测误差时序相关性的船舶净负荷场景集;其次,结合场景集信息及滚动优化、反馈校正机制,建立各场景下控制动作运行成本与荷电状态偏离惩罚成本之和期望最小的随机模型预测控制能量管理模型;随后,基于随机模型预测控制生成大量训练数据样本,训练随机森林算法对数据样本进行多变量回归;分别得到低、中、高三种不同功率等级负荷下的数据驱动随机模型预测控制实时能量管理策略。该专利针对船舶微电网提出了一种基于数据驱动的实时能量管理方法。该方法着眼于船舶负荷的准确预测,并通过数学优化模型求解得到控制变量,然而准确预测往往难以实现,此外该专利也未考虑船速动态变化对船舶实时能量调控的影响。而本发明所提方案无需事先进行负荷的准确预测,训练好的船舶智能体能够基于船速和负荷的动态变化实时地优化出柴油发电机组和储能的功率分配。
4、y.hu,w.li,k.xu,t.zahid,f.qin,and c.li,“energy management strategy fora hybrid electric vehicle based on deep reinforcement learning,”appliedsciences,vol.8,no.2,p.187,jan.2018.该文献利用深度强化学习研究了混合动力汽车的实时能量管理策略。该方法能够根据数据输入自主学习最优策略,然而该文献中状态空间、动作空间以及奖励函数的设计并不适用于全电力船舶。本发明根据全电力船舶能源系统的特点设计了相应的状态空间、动作空间以及奖励函数,能够有效解决全电力船舶的实时能量管理问题。
5、kumar s.deep reinforcement learning based energy management in marinehybrid vehicle[d].ntnu,2021.该文献基于深度强化学习研究了混合动力船舶的实时能量管理策略。然而该文献对于船舶航行过程中的动态变化因素考虑不够全面,仅考虑了负荷的不确定性,并未考虑船速变化对实时能量管理智能决策系统的影响。本发明将船舶航速以及加速度等状态变量考虑在内,能够更好地识别船舶航行的动态变化规律,进一步提升了船舶航行的智能决策水平。
6、为了实现移动能源网络实时的能量优化调控,提高移动能源网络航行过程中的智能决策水平并减少燃油消耗,本发明基于深度强化学习思想,提出移动能源网络实时能量管理方法,可以大幅度提升移动能源网络运行效率。
技术实现思路
1、针对现有技术中的缺陷,本发明的目的是提供一种基于深度强化学习的移动能源网络实时能量管理方法及系统。
2、根据本发明提供的一种基于深度强化学习的移动能源网络实时能量管理方法,包括:
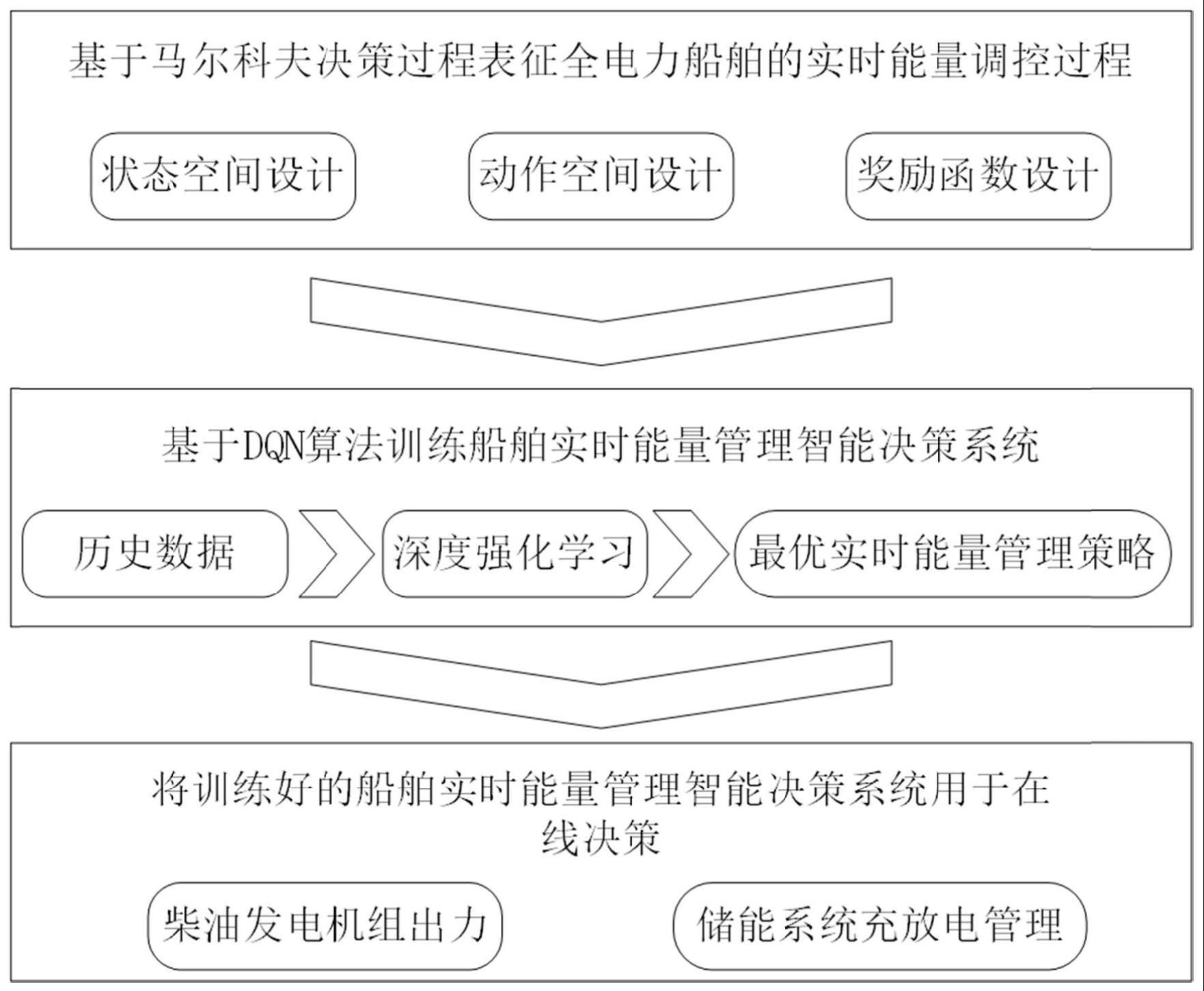
3、步骤s1:基于马尔科夫决策过程表征全电力船舶的实时能量调控过程,包括:状态空间、动作空间以及奖励函数;
4、步骤s2:构建表示动作价值函数的q网络模型,并利用状态空间、动作空间以及奖励函数采用dqn算法训练q网络模型;
5、步骤s3:基于当前状态空间通过训练后的q网络模型选择决策动作,实现船舶的实时能量管理智能决策;
6、所述q网络模型是通过神经网络的输入输出拟合船舶期望做出最优能量管理智能决策的这一行为过程,实现了从状态空间到动作空间的映射,达到了依据船舶运行的实时状态进行最优能量管理的目的。
7、优选地,所述状态空间采用:
8、
9、其中,表示t时段的船速;表示t时段的船速加速度;表示t时段的生活服务负荷的功率需求;soct表示t时段储能系统的荷电状态;
10、所述动作空间采用:
11、at={ratiot}
12、其中,表示t时段柴油发电机组的输出功率;pgn表示柴油发电机组的额定功率;ratiot在0到1的范围内离散化取值;当ratiot等于1时,表示柴油发电机组按最大功率运行;ratiot等于0时表示此时柴油发电机组空载运行,由储能系统提供全部负荷支撑;
13、所述奖励函数采用:
14、智能决策系统做出决策动作at,储能系统荷电状态由soct变为soct+1,若soct+1超出规定的荷电状态上下限,则获得soct+1和soct的变化趋势,若变化趋势和期望相反,则通过奖励函数施加惩罚;
15、当soct+1<0或soct+1>1时:
16、rt=-c
17、其中,rt表示智能决策系统做出决策动作at后获得的奖励值;c表示正数;
18、当0≤soct+1<socregion_l时:
19、
20、其中,socregion_l表示储能系统荷电状态安全区间的下限;|δsocmax|表示一个时间段储能系统荷电状态最大变化量的绝对值;
21、当socregion_h≤soct+1<1时:
22、
23、其中,socregion_h表示储能系统荷电状态安全区间的上限;
24、当socregion_l≤soct+1<socregion_h时,表示荷电状态在安全区间时,奖励函数根据柴油发电机组燃油效率最佳运行点设计奖励函数:
25、
26、其中,和β为拟合参数,使得此时rt的取值大致在[-1,1]的区间内变化,ratioopt为柴油发电机组燃油效率最佳运行点。
27、优选地,所述q网络模型采用:
28、
29、其中,t表示时间,gt表示t时段的回报,st表示t时段的状态,at表示t时段智能决策系统做出的决策动作,rt+k表示t+k时段的奖励;eπ表示在策略π下求期望,γ表示折扣因子。
30、优选地,所述步骤s2采用:
31、步骤s2.1:初始化当前q网络模型qω(s,a),并采用相同参数初始化目标网络
32、步骤s2.2:初始化经验回放池r;
33、步骤s2.3:基于马尔科夫决策序列获取初始状态s1;
34、步骤s2.4:根据当前网络qω(s,a)以ε-贪婪策略选择当前状态st下的动作at,执行动作at,获得奖励rt,环境状态变化为st+1;将(st,at,rt,st+1)存储到经验回放池中;重复触发步骤s2.4,当经验回放池中数据满足预设要求时,则采样n个数据{(si,ai,ri,s′i)}i=1,…,n;对于每个数据利用目标网络计算损失函数,并通过随机梯度下降算法最小化损失,更新当前网络qω(s,a)的参数;每隔一定的时间将当前网络的参数同步至目标网络;重复触发步骤s2.4,直至当前马尔科夫决策序列为终止状态;获取新的马尔科夫决策序列,重复触发步骤s2.3至步骤s2.4,直至训练完毕。
35、优选地,所述步骤s2.4采用:
36、利用目标网络计算
37、其中,γ表示折扣因子;
38、计算损失函数:
39、
40、根据本发明提供的一种基于深度强化学习的移动能源网络实时能量管理系统,包括:
41、模块m1:基于马尔科夫决策过程表征全电力船舶的实时能量调控过程,包括:状态空间、动作空间以及奖励函数;
42、模块m2:构建表示动作价值函数的q网络模型,并利用状态空间、动作空间以及奖励函数采用dqn算法训练q网络模型;
43、模块m3:基于当前状态空间通过训练后的q网络模型选择决策动作,实现船舶的实时能量管理智能决策;
44、所述q网络模型是通过神经网络的输入输出拟合船舶期望做出最优能量管理智能决策的这一行为过程,实现了从状态空间到动作空间的映射,达到了依据船舶运行的实时状态进行最优能量管理的目的。
45、优选地,所述状态空间采用:
46、
47、其中,表示t时段的船速;表示t时段的船速加速度;表示t时段的生活服务负荷的功率需求;soct表示t时段储能系统的荷电状态;
48、所述动作空间采用:
49、at={ratiot}
50、其中,表示t时段柴油发电机组的输出功率;pgn表示柴油发电机组的额定功率;ratiot在0到1的范围内离散化取值;当ratiot等于1时,表示柴油发电机组按最大功率运行;ratiot等于0时表示此时柴油发电机组空载运行,由储能系统提供全部负荷支撑;
51、所述奖励函数采用:
52、智能决策系统做出决策动作at,储能系统荷电状态由soct变为soct+1,若soct+1超出规定的荷电状态上下限,则获得soct+1和soct的变化趋势,若变化趋势和期望相反,则通过奖励函数施加惩罚;
53、当soct+1<0或soct+1>1时:
54、rt=-c
55、其中,rt表示智能决策系统做出决策动作at后获得的奖励值;c表示正数;
56、当0≤soct+1<socregion_l时:
57、
58、其中,socregion_l表示储能系统荷电状态安全区间的下限;|δsocmax|表示一个时间段储能系统荷电状态最大变化量的绝对值;
59、当socregion_h≤soct+1<1时:
60、
61、其中,socregion_h表示储能系统荷电状态安全区间的上限;
62、当socregion_l≤soct+1<socregion_h时,表示荷电状态在安全区间时,奖励函数根据柴油发电机组燃油效率最佳运行点设计奖励函数:
63、
64、其中,和β为拟合参数,使得此时rt的取值大致在[-1,1]的区间内变化,ratioopt为柴油发电机组燃油效率最佳运行点。
65、优选地,所述q网络模型采用:
66、
67、其中,t表示时间,gt表示t时段的回报,st表示t时段的状态,at表示t时段智能决策系统做出的决策动作,rt+k表示t+k时段的奖励;eπ表示在策略π下求期望,γ表示折扣因子。
68、优选地,所述模块m2采用:
69、模块m2.1:初始化当前q网络模型qω(s,a),并采用相同参数初始化目标网络
70、模块m2.2:初始化经验回放池r;
71、模块m2.3:基于马尔科夫决策序列获取初始状态s1;
72、模块m2.4:根据当前网络qω(s,a)以ε-贪婪策略选择当前状态st下的动作at,执行动作at,获得奖励rt,环境状态变化为st+1;将(st,at,rt,st+1)存储到经验回放池中;重复触发模块m2.4,当经验回放池中数据满足预设要求时,则采样n个数据{(si,ai,ri,s′i)}i=1,...,n;对于每个数据利用目标网络计算损失函数,并通过随机梯度下降算法最小化损失,更新当前网络qω(s,a)的参数;每隔一定的时间将当前网络的参数同步至目标网络;重复触发模块m2.4,直至当前马尔科夫决策序列为终止状态;获取新的马尔科夫决策序列,重复触发模块m2.3至模块m2.4,直至训练完毕。
73、优选地,所述模块m2.4采用:
74、利用目标网络计算
75、其中,γ表示折扣因子;
76、计算损失函数:
77、
78、与现有技术相比,本发明具有如下的有益效果:
79、1、本发明提出的实时能量管理方法可提升移动能源网络对航行过程中动态变化因素的适应性,可以使全电力船舶实现航行时的在线决策;
80、2、本发明将船速和生活服务负荷作为状态变量,可以计及船速的动态变化以及生活服务负荷的不确定性实现全电力船舶的实时能量管理,从而达到更优的能量管理水平;
81、3、本发明提出采用深度强化学习方法部署移动能源网络实时能量管理智能决策系统,无需对船舶能源系统进行精确的数学建模,具有广泛的适用性和良好的延展性,可有效提高全电力船舶的智能决策水平;
82、4、本发明并不局限于全电力船舶的实时能量管理,对于移动能源网络的实时能量管理具有一定的普适性;
83、5、本发明在船舶实时能量调控过程中无需实现对船舶自身能源系统和海洋环境的准确预测,能够基于实时的状态做出最优的动作决策,相比于传统的数学优化方法具有显著优势。
- 还没有人留言评论。精彩留言会获得点赞!