一种基于文本挖掘和PMC指数模型的政策文本量化分析方法
本发明属于自然语言处理,具体的是,涉及了一种基于文本挖掘和pmc指数模型的政策文本量化分析方法。
背景技术:
1、当前对政策文本的研究更多地倾向于单一文本的情感倾向和多文本的主题词提取等,缺少大量政策文本的量化方法,缺少在同一领域中所有政策文本的共性分析和不同发文部门针对性政策的个性分析相结合的方法。然而把握政策文本的共性特征和单一文本的个性特点,有利于帮助政策制定者更好地制定新一轮的政策文本,有利于政策研究者更科学地分析和梳理政策发展脉络,有利于政策实施者更好地把握政策实施。由于政策文本的共性层面和个性层面的量化方法当前并没有研究,因此亟需提供一种能够客观、科学地政策量化分析方法。
技术实现思路
1、发明目的:本发明的目的是提供了一种基于文本挖掘和pmc指数模型的政策文本量化分析方法;本发明针对政策文本数量多、结构杂、量化难的现状,运用文本挖掘和pmc指数模型相结合的研究方法,通过收集大量同一领域的政策文本,结合文本挖掘技术进行共性研究,结合pmc指数模型对政策进行个性研究,从而达到客观、科学地对政策文本进行量化。
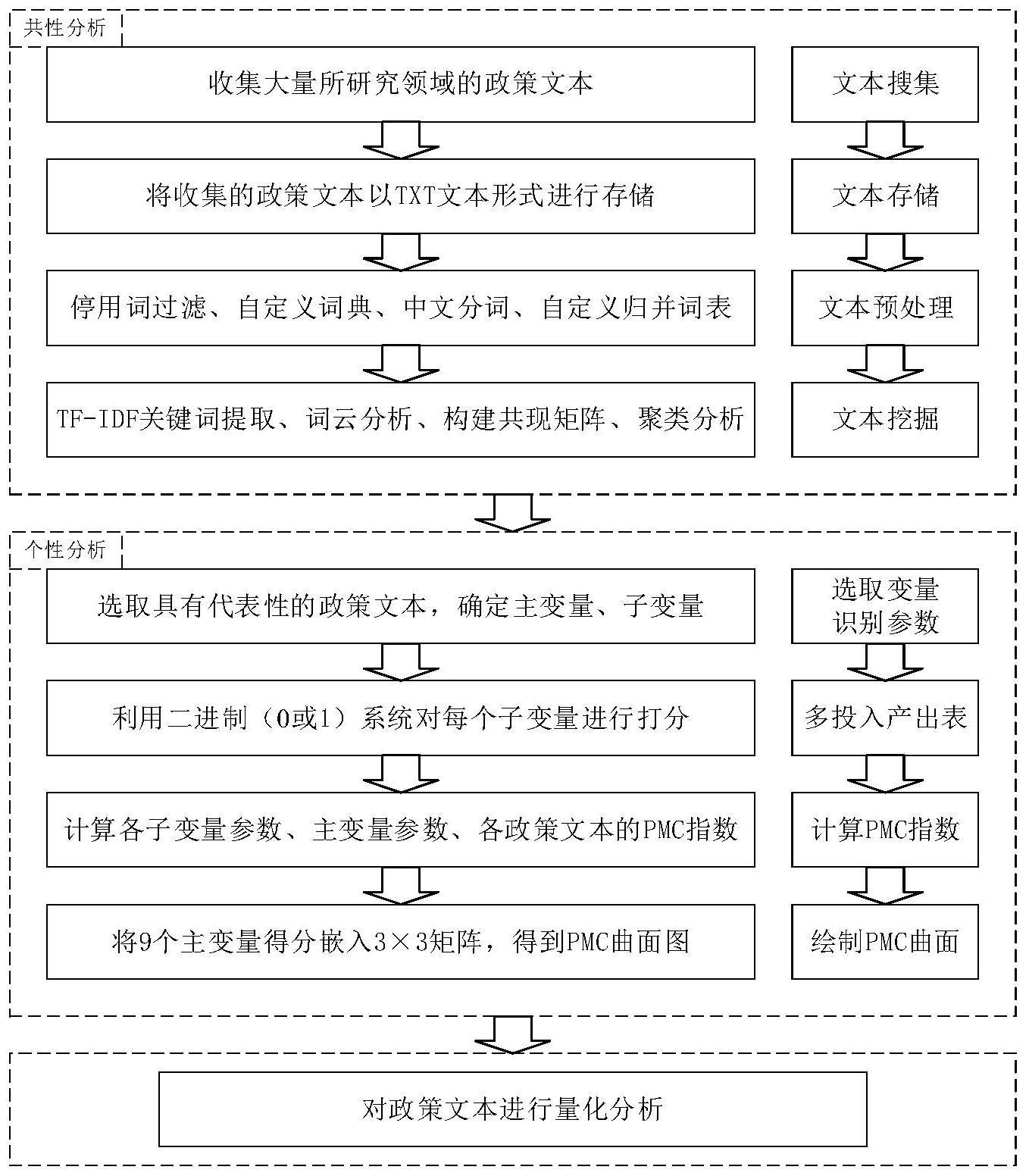
2、技术方案:本发明所述的一种基于文本挖掘和pmc指数模型的政策文本量化分析方法,其具体操作步骤如下:
3、(1)、文本收集:收集大量所研究领域的政策文本;
4、(2)、文本存储:对步骤(1)中获取的政策文本以txt文本形式进行存储;
5、(3)、文本预处理:由于政策文本属于非结构化数据,叙述无统一标准,因此中文分词难度大,需要在分词前进行预处理,以提高文本挖掘准确性;
6、(4)、文本挖掘:通过tf-idf手段进行关键词提取,并统计关键词的频次,对关键词进行词云可视化处理,构建共现矩阵,对关键词进行聚类分析,完成政策文本共性研究;
7、(5)、pmc指数模型构建,选取不同部门发布的不同类型的政策文本,进行单一政策文本打分评价,完成政策文本的个性研究;
8、(6)、基于步骤(4)和步骤(5)对政策展开量化分析。
9、进一步的,在步骤(1)中,所述的收集大量所研究领域的政策文本指的是确定某一个起始时间节点到某一个结束时间节点的涉及该领域的所有完整的政策文本。
10、进一步的,在步骤(3)中,所述的文本预处理包括停用词过滤、自定义词典、中文分词、自定义归并词表;
11、其在,停用词过滤:原始的政策文本中存在大量的标点符号,如“,”“。”“;”“、”等和对于研究目的来说毫无意义的字词,如“啊”“的”“一个”等,将这些标点符号和无用字词去除,需要定义停用词库以达到停用词过滤的目的;
12、自定义词典:为防止分词过于精细化,防止将有意义的词组进一步划分为无意义字词,如政策文本中出现的“推进科技成果产业化”研究中所需要的是“推进/科技成果产业化”而分词结果为“推进/科技/成果/产业化”这样的结果对研究毫无意义,因此需借助搜狗词库、百度词库以及人工添加进行完善自定义词典;
13、中文分词:在非结构化的政策文本中,需要提取和挖掘隐藏在语句中的关键词,通过中文分词手段进行处理,如“在传统制造业、战略性新兴产业、现代服务业等重点领域开展创新设计示范。”中的“传统制造业、战略性新兴产业、现代服务业、创新设计示范”都对研究有一定的作用,因此需要对政策文本进行分词处理;
14、自定义归并词表:因为中文表述无统一标准,在政策文本中存在大量意思相近或相同的关键词,如“节能环保技术”、“绿色技术”、“低碳技术”等可合并为“绿色技术”。为减少关键词数量,提高文本挖掘有效性,需要建立自定义归并词表对意思相近或相同的词语进行合并。
15、进一步的,在步骤(4)中,所述的文本挖掘,包括tf-idf关键词提取、词云分析、共现矩阵构建以及聚类分析;
16、其在,tf-idf关键词提取:tf-idf算法(term frequency-inverse documentfrequency)又称为词频-逆文档频率算法,是一种用于文本关键词提取的技术手段,当某一字词在单个文档中出现的频次越高,说明该词的重要程度越高,如“绿色技术”一词只在某个政策文件中高频出现,较少出现在其他政策文本中,则称该词为关键词;反之,当该词在所属语料库中文档数越多,则该词重要程度越低,如“提高”一词,在每个政策文本中都高频出现,则该词的重要程度很低;
17、词云分析:基于文本挖掘和可视化技术,通过tf-idf提取关键词后,对关键词进行词频统计,绘制出关键词的词云图,设置词频和字体大小的关联值,使关键词词频越大其词云字体越大,由此可直观反映该领域政策的侧重点和发展方向;
18、共现矩阵构建:两个关键词在同一个政策文本中同时出现称为关键词共现,关键词共现计算方式由共现矩阵形式体现的,以共现频次表示共现强度,如关键词a_13和a_10同时出现在第一个政策文本中,则记为1,如果同时出现在第二个政策文本中,则再次累加1,依此计算,最终得到共现矩阵;
19、聚类分析:聚类分析是对政策关键词进行分类的一种多元统计方法,可以对关键词关系的远近程度做出分类;考虑到共现矩阵的共现次数之间数值差异较大,将得到的共现矩阵,采用学界最常用的ochiia系数法,进行归一化处理,建立关键词相关矩阵,导入spss软件,选择“ward法(即离差平方和法)”并绘制树状图,进行层次聚类分析。
20、进一步的,在步骤(5)中,所述的pmc指数模型构建,包括选取变量与识别参数、构建多投入产出表、计算pmc指数、绘制pmc曲面、分析和评价政策;
21、选取变量与识别参数:为保证研究的全面性,从不同部门(不同地区)发布的不同类型的政策文本中各选取一篇具有代表性的政策进行评价,根据政策制定、实施和反馈的情况设置量化评价变量,可从性质、效力、内容、客体等方面进行选取,最终确定9个主变量和若干个子变量;
22、构建多投入产出表:为更好地量化各个子变量的数值,需要在子变量确定之后,保证子变量在评价时具有相同的权重,利用二进制(0或1)系统对每个子变量进行打分,即政策内容涉及相关子变量记为1,否则为0,如主变量政策效力可设置长期、中期、短期、临时四个子变量,若该政策是长期政策设定长期为1,其他为0;
23、计算pmc指数:根据pmc指数的大小判定政策实际效果。其计算步骤有:主变量和子变量放入多投入产出表中,计算各子变量参数,计算主变量参数,计算各政策文本的pmc指数;
24、绘制pmc曲面:pmc曲面图可直观展示待分析政策在各个主变量上的得分情况,为政策制定者、实施者以及研究者提供可视化窗口,计算pmc矩阵是绘制pmc曲面图的前提,将9个主变量得分嵌入3×3矩阵,得到pmc矩阵,最终得到pmc曲面图。
25、有益效果:本发明与现有技术相比,本发明的特点:本发明巧妙地将文本挖掘和pmc指数模型进行结合对政策进行全面量化分析,通过文本挖掘方法,完成共性研究,通过pmc指数模型,完成个性研究;相比于现有单一文本研究或多文本共性研究,有效提高政策研究说服力,有利于帮助政策制定者更好地把握政策制定方向,有利于政策实施者更好地实施政策。
- 还没有人留言评论。精彩留言会获得点赞!