数据处理方法、装置及设备与流程
本文件涉及数据处理,尤其涉及一种数据处理方法、装置及设备。
背景技术:
1、命名实体识别在自然语言处理领域中占据十分重要的位置,如在问答系统、知识库构建等应用场景中,可以通过构建实体识别模型,对自然语言文本中包含的实体进行识别,以通过识别出的实体确定对应的问答策略或构建对应的知识库等。
2、可以通过人工达标的方式确定用于训练实体识别模型的样本数据对应的标签,但是,由于人工标注的标签的准确性差,通过该样本数据训练得到的实体识别模型的实体识别的准确性差,因此,需要一种能够提高命名实体识别准确性的方案。
技术实现思路
1、本说明书实施例的目的是提供一种能够提高命名实体识别准确性的方案。
2、为了实现上述技术方案,本说明书实施例是这样实现的:
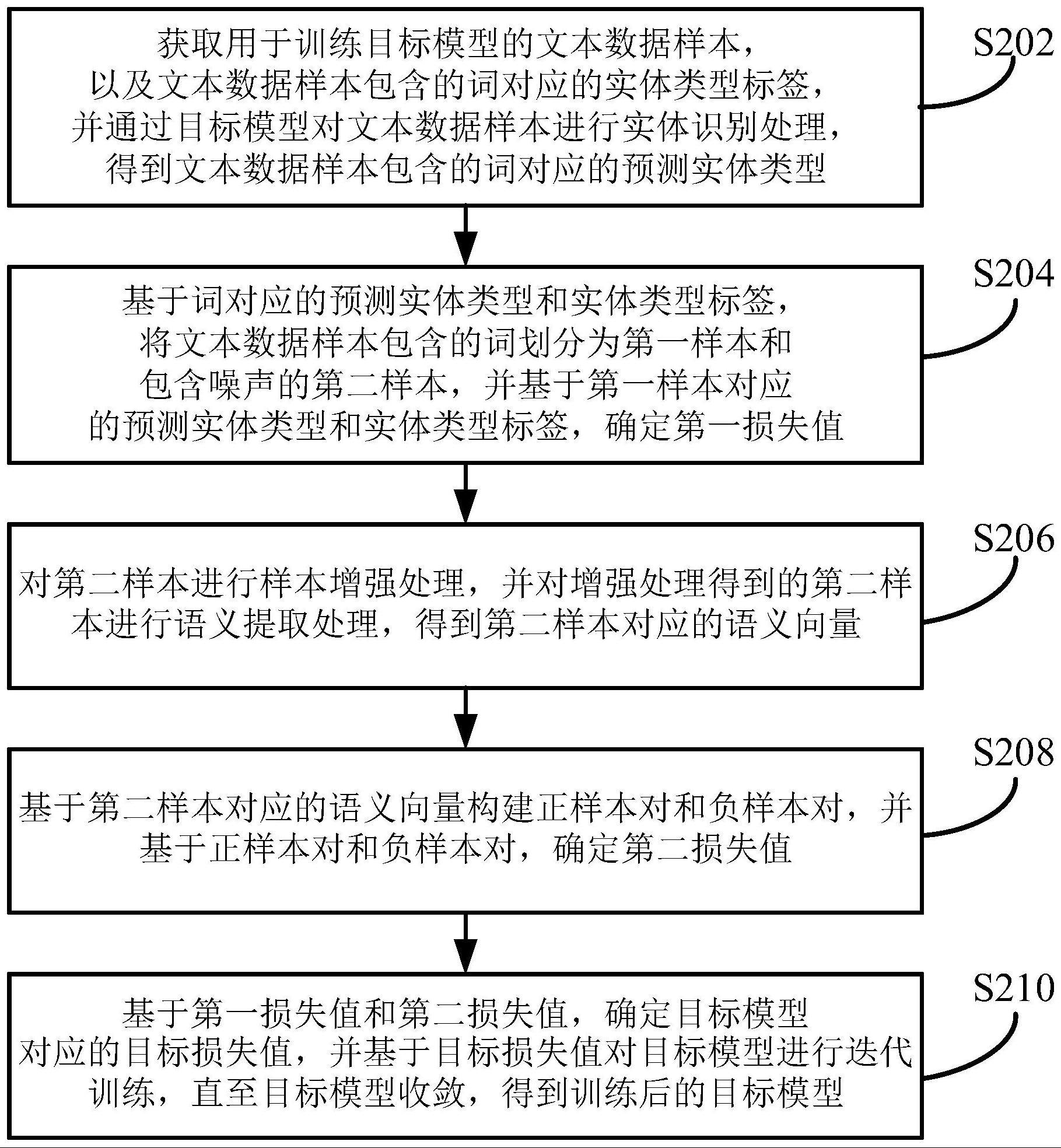
3、第一方面,本说明书实施例提供的一种数据处理方法,包括:获取用于训练目标模型的文本数据样本,以及所述文本数据样本包含的词对应的实体类型标签,并通过所述目标模型对所述文本数据样本进行实体识别处理,得到所述文本数据样本包含的词对应的预测实体类型;基于所述词对应的预测实体类型和实体类型标签,将所述文本数据样本包含的词划分为第一样本和包含噪声的第二样本,并基于所述第一样本对应的预测实体类型和实体类型标签,确定第一损失值;对所述第二样本进行样本增强处理,并对增强处理得到的第二样本进行语义提取处理,得到所述第二样本对应的语义向量;基于所述第二样本对应的语义向量构建正样本对和负样本对,并基于所述正样本对和负样本对,确定第二损失值;基于所述第一损失值和所述第二损失值,确定所述目标模型对应的目标损失值,并基于所述目标损失值对所述目标模型进行迭代训练,直至所述目标模型收敛,得到训练后的目标模型。
4、第二方面,本说明书实施例提供的一种数据处理方法,包括:在检测到目标用户触发执行目标业务的情况下,基于获取的目标信息确定待识别的目标文本数据,所述目标信息包括所述目标用户触发执行所述目标业务所需的信息,和/或所述目标用户针对触发执行所述目标业务的交互信息;将所述目标文本数据输入所述训练后的目标模型,得到所述目标文本数据对应的预测实体类型;基于所述目标文本数据对应的预测实体类型,确定候选话术中与所述目标用户触发执行所述目标业务匹配的目标话术,并输出所述目标话术;其中,所述目标模型的训练过程包括:获取用于训练目标模型的文本数据样本,以及所述文本数据样本包含的词对应的实体类型标签,并通过所述目标模型对所述文本数据样本进行实体识别处理,得到所述文本数据样本包含的词对应的预测实体类型;基于所述词对应的预测实体类型和实体类型标签,将所述文本数据样本包含的词划分为第一样本和包含噪声的第二样本,并基于所述第一样本对应的预测实体类型和实体类型标签,确定第一损失值;对所述第二样本进行样本增强处理,并对增强处理得到的第二样本进行语义提取处理,得到所述第二样本对应的语义向量;基于所述第二样本对应的语义向量构建正样本对和负样本对,并基于所述正样本对和负样本对,确定第二损失值;基于所述第一损失值和所述第二损失值,确定所述目标模型对应的目标损失值,并基于所述目标损失值对所述目标模型进行迭代训练,直至所述目标模型收敛,得到训练后的目标模型。
5、第三方面,本说明书实施例提供了一种数据处理装置,所述装置包括:第一获取模块,用于获取用于训练目标模型的文本数据样本,以及所述文本数据样本包含的词对应的实体类型标签,并通过所述目标模型对所述文本数据样本进行实体识别处理,得到所述文本数据样本包含的词对应的预测实体类型;样本划分模块,用于基于所述词对应的预测实体类型和实体类型标签,将所述文本数据样本包含的词划分为第一样本和包含噪声的第二样本,并基于所述第一样本对应的预测实体类型和实体类型标签,确定第一损失值;第一处理模块,用于对所述第二样本进行样本增强处理,并对增强处理得到的第二样本进行语义提取处理,得到所述第二样本对应的语义向量;第一确定模块,用于基于所述第二样本对应的语义向量构建正样本对和负样本对,并基于所述正样本对和负样本对,确定第二损失值;第二确定模块,用于基于所述第一损失值和所述第二损失值,确定所述目标模型对应的目标损失值,并基于所述目标损失值对所述目标模型进行迭代训练,直至所述目标模型收敛,得到训练后的目标模型。
6、第四方面,本说明书实施例提供了一种数据处理装置,所述装置包括:数据获取模块,用于在检测到目标用户触发执行目标业务的情况下,基于获取的目标信息确定待识别的目标文本数据,所述目标信息包括所述目标用户触发执行所述目标业务所需的信息,和/或所述目标用户针对触发执行所述目标业务的交互信息;类型确定模块,用于将所述目标文本数据输入所述训练后的目标模型,得到所述目标文本数据对应的预测实体类型;话术确定模块,用于基于所述目标文本数据对应的预测实体类型,确定候选话术中与所述目标用户触发执行所述目标业务匹配的目标话术,并输出所述目标话术;其中,所述目标模型的训练过程包括:获取用于训练目标模型的文本数据样本,以及所述文本数据样本包含的词对应的实体类型标签,并通过所述目标模型对所述文本数据样本进行实体识别处理,得到所述文本数据样本包含的词对应的预测实体类型;基于所述词对应的预测实体类型和实体类型标签,将所述文本数据样本包含的词划分为第一样本和包含噪声的第二样本,并基于所述第一样本对应的预测实体类型和实体类型标签,确定第一损失值;对所述第二样本进行样本增强处理,并对增强处理得到的第二样本进行语义提取处理,得到所述第二样本对应的语义向量;基于所述第二样本对应的语义向量构建正样本对和负样本对,并基于所述正样本对和负样本对,确定第二损失值;基于所述第一损失值和所述第二损失值,确定所述目标模型对应的目标损失值,并基于所述目标损失值对所述目标模型进行迭代训练,直至所述目标模型收敛,得到训练后的目标模型。
7、第五方面,本说明书实施例提供了一种数据处理设备,所述数据处理设备包括:处理器;以及被安排成存储计算机可执行指令的存储器,所述可执行指令在被执行时使所述处理器:获取用于训练目标模型的文本数据样本,以及所述文本数据样本包含的词对应的实体类型标签,并通过所述目标模型对所述文本数据样本进行实体识别处理,得到所述文本数据样本包含的词对应的预测实体类型;基于所述词对应的预测实体类型和实体类型标签,将所述文本数据样本包含的词划分为第一样本和包含噪声的第二样本,并基于所述第一样本对应的预测实体类型和实体类型标签,确定第一损失值;对所述第二样本进行样本增强处理,并对增强处理得到的第二样本进行语义提取处理,得到所述第二样本对应的语义向量;基于所述第二样本对应的语义向量构建正样本对和负样本对,并基于所述正样本对和负样本对,确定第二损失值;基于所述第一损失值和所述第二损失值,确定所述目标模型对应的目标损失值,并基于所述目标损失值对所述目标模型进行迭代训练,直至所述目标模型收敛,得到训练后的目标模型。
8、第六方面,本说明书实施例提供了一种数据处理设备,所述数据处理设备包括:处理器;以及被安排成存储计算机可执行指令的存储器,所述可执行指令在被执行时使所述处理器:在检测到目标用户触发执行目标业务的情况下,基于获取的目标信息确定待识别的目标文本数据,所述目标信息包括所述目标用户触发执行所述目标业务所需的信息,和/或所述目标用户针对触发执行所述目标业务的交互信息;将所述目标文本数据输入所述训练后的目标模型,得到所述目标文本数据对应的预测实体类型;基于所述目标文本数据对应的预测实体类型,确定候选话术中与所述目标用户触发执行所述目标业务匹配的目标话术,并输出所述目标话术;其中,所述目标模型的训练过程包括:获取用于训练目标模型的文本数据样本,以及所述文本数据样本包含的词对应的实体类型标签,并通过所述目标模型对所述文本数据样本进行实体识别处理,得到所述文本数据样本包含的词对应的预测实体类型;基于所述词对应的预测实体类型和实体类型标签,将所述文本数据样本包含的词划分为第一样本和包含噪声的第二样本,并基于所述第一样本对应的预测实体类型和实体类型标签,确定第一损失值;对所述第二样本进行样本增强处理,并对增强处理得到的第二样本进行语义提取处理,得到所述第二样本对应的语义向量;基于所述第二样本对应的语义向量构建正样本对和负样本对,并基于所述正样本对和负样本对,确定第二损失值;基于所述第一损失值和所述第二损失值,确定所述目标模型对应的目标损失值,并基于所述目标损失值对所述目标模型进行迭代训练,直至所述目标模型收敛,得到训练后的目标模型。
9、第七方面,本说明书实施例提供一种存储介质,所述存储介质用于存储计算机可执行指令,所述可执行指令在被执行时实现以下流程:获取用于训练目标模型的文本数据样本,以及所述文本数据样本包含的词对应的实体类型标签,并通过所述目标模型对所述文本数据样本进行实体识别处理,得到所述文本数据样本包含的词对应的预测实体类型;基于所述词对应的预测实体类型和实体类型标签,将所述文本数据样本包含的词划分为第一样本和包含噪声的第二样本,并基于所述第一样本对应的预测实体类型和实体类型标签,确定第一损失值;对所述第二样本进行样本增强处理,并对增强处理得到的第二样本进行语义提取处理,得到所述第二样本对应的语义向量;基于所述第二样本对应的语义向量构建正样本对和负样本对,并基于所述正样本对和负样本对,确定第二损失值;基于所述第一损失值和所述第二损失值,确定所述目标模型对应的目标损失值,并基于所述目标损失值对所述目标模型进行迭代训练,直至所述目标模型收敛,得到训练后的目标模型。
10、第八方面,本说明书实施例提供一种存储介质,所述存储介质用于存储计算机可执行指令,所述可执行指令在被执行时实现以下流程:在检测到目标用户触发执行目标业务的情况下,基于获取的目标信息确定待识别的目标文本数据,所述目标信息包括所述目标用户触发执行所述目标业务所需的信息,和/或所述目标用户针对触发执行所述目标业务的交互信息;将所述目标文本数据输入所述训练后的目标模型,得到所述目标文本数据对应的预测实体类型;基于所述目标文本数据对应的预测实体类型,确定候选话术中与所述目标用户触发执行所述目标业务匹配的目标话术,并输出所述目标话术;其中,所述目标模型的训练过程包括:获取用于训练目标模型的文本数据样本,以及所述文本数据样本包含的词对应的实体类型标签,并通过所述目标模型对所述文本数据样本进行实体识别处理,得到所述文本数据样本包含的词对应的预测实体类型;基于所述词对应的预测实体类型和实体类型标签,将所述文本数据样本包含的词划分为第一样本和包含噪声的第二样本,并基于所述第一样本对应的预测实体类型和实体类型标签,确定第一损失值;对所述第二样本进行样本增强处理,并对增强处理得到的第二样本进行语义提取处理,得到所述第二样本对应的语义向量;基于所述第二样本对应的语义向量构建正样本对和负样本对,并基于所述正样本对和负样本对,确定第二损失值;基于所述第一损失值和所述第二损失值,确定所述目标模型对应的目标损失值,并基于所述目标损失值对所述目标模型进行迭代训练,直至所述目标模型收敛,得到训练后的目标模型。
- 还没有人留言评论。精彩留言会获得点赞!