一种基于分流注意力Transformer的红外光和可见光图像融合系统
本发明涉及图像融合,具体涉及一种基于分流注意力transformer的红外光和可见光图像融合系统。
背景技术:
1、由于传感器自身物理特征、成像机理和观察视角等各个方面的限制,单一的视觉传感器往往不能从场景中提取足够的信息。基于热辐射理论,红外传感器不受环境干扰的情况下突出热源区域。然而,由于红外传感器生成的图像分辨率较低,通常缺乏结构特征和细节信息。相比之下,可见传感器能够生成具有较高空间分辨率的友好视觉图像。为了继承两种传感器的优势,通过图像融合技术来保留红外光和可见光图像的热辐射和纹理信息是一种有效的方法。这种融合结果具有优越的视觉感知和场景表征能力,可广泛应用于图像增强、语义分割、目标检测等领域。
2、红外光与可见光图像融合的关键在于如何有效地整合热源特征和细节纹理信息。在过去的几十年里,已经提出了大量传统融合方法和基于深度学习的融合方法。
3、传统融合方法主要由空间域和多尺度变换域方法组成。空间域方法通常计算输入图像的像素级显著性的加权平均值,以获得融合图像。多尺度变换域方法包括小波变换和曲线变换等,通过数学变换将输入转换到变换域,并设计融合规则来融合图像。由于上述传统方法没有考虑源图像之间的特征差异,往往会给融合后的图像带来负面影响。此外,传统方法的融合规则和活动水平测量不能适应复杂的场景,也给其广泛应用带来了挑战。
4、近年来,深度学习由于杰出的深度特征提取能力而逐渐成为图像融合领域的主流。这些方法不仅可以自动从数据中提取深层特征,还克服了传统方法在适应复杂场景时面临的问题。然而,这些方法只能利用局部信息进行图像融合,无法利用长距离依赖进一步改善融合效果。一些基于transformer的融合方法受益于全局上下文特征的互补聚合,已经展示了出色的性能,但它们仍然具有一定的局限性。首先,与基于卷积神经网络的方法相比,基于transformer的方法在生成测试图像方面效率较低。此外,大多数基于transformer的方法通常在分割图像后直接处理一系列token,这将导致内存消耗很高。其次,由于现有的transformer融合网络忽略了层内混合粒度的特征,保留细粒度细节和粗粒度对象的能力有限。最后,特征融合过程只融合了单一域内的信息,缺乏上下文信息,这可能会影响融合结果的视觉表现。
技术实现思路
1、本发明的目的在于,提出一种基于分流注意力transformer的红外光和可见光图像融合系统,用于提取和融合全局粒度信息和局部特征,通过利用远程学习和减少输入token的数量,可以显著降低计算成本。
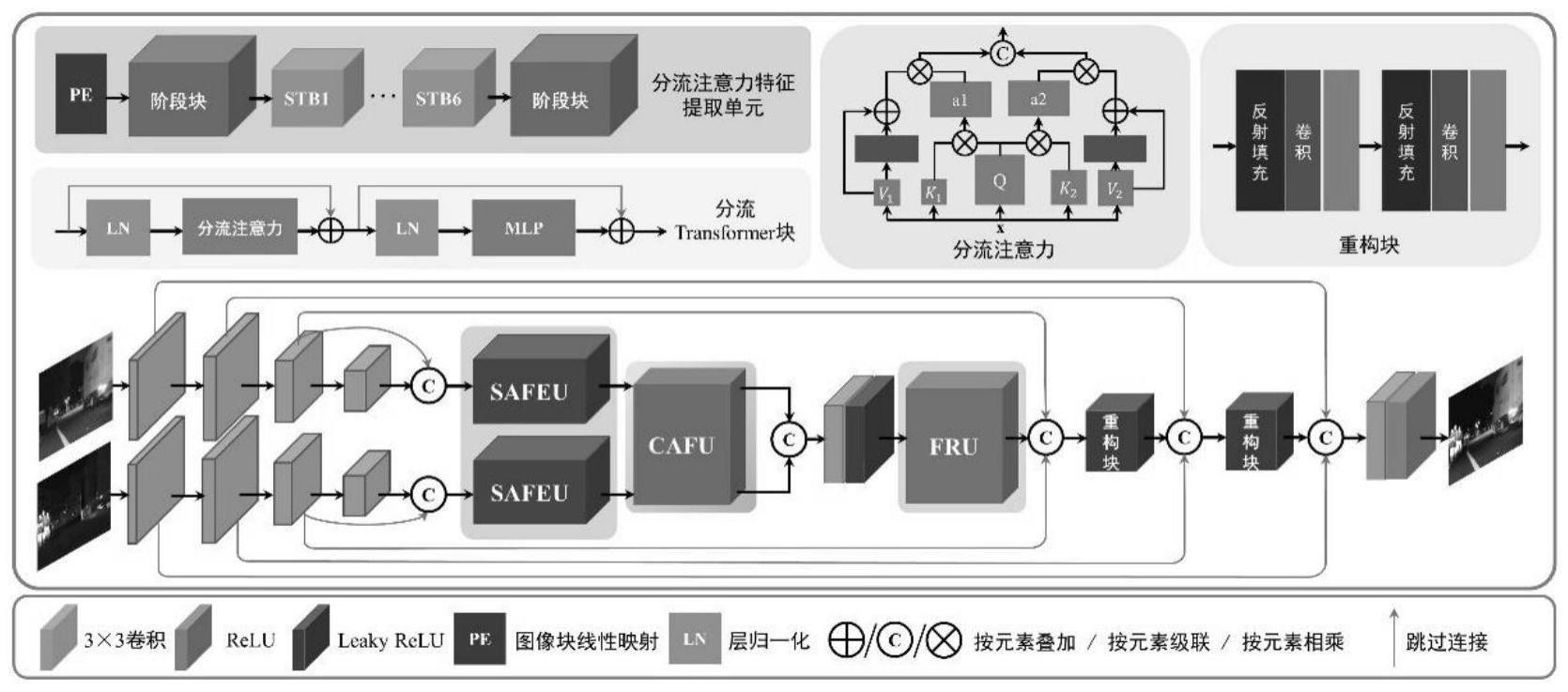
2、为实现上述目的,本技术提出的一种基于分流注意力transformer的红外光和可见光图像融合系统,包括:用于融合红外光和可见光图像的分流注意力transformer网络模型,输入的红外光和可见光图像首先进入由多个卷积层组成的浅卷积块,提取浅层局部特征,然后采用多尺度技术将浅层局部特征分解成不同尺度,在不同尺度上捕获浅层信息。
3、进一步的,所述分流注意力transformer网络模型包括分流注意力特征提取单元、交叉注意力融合单元、特征重构单元。
4、进一步的,所述分流注意力特征提取单元包括三个阶段块,每个阶段块包括六个分流transformer子块,各个子块由多粒度学习驱动,通过向异构感受野注入token,捕获多粒度信息的同时减少token的数量;所述分流transformer子块对全局特征进行建模,实现全局范围内多粒度特征的提取。
5、进一步的,所述交叉注意力融合单元包括两个交叉注意力残差块,每个残差块中设有基于自注意力的域内融合块来有效地整合同一域中的全局交互信息,以及基于交叉注意力的域间融合块来进一步整合不同域之间的全局交互信息。
6、进一步的,所述域间融合块利用交叉注意力机制来实现全局特征信息的交互,通过合并跨域信息,并使用跳过连接来保留不同域的信息,实现全局域间和跨域交互的交替集成。
7、更进一步的,所述特征重构单元包括深层重构块和浅层重构块,用于将聚合后的深层特征映射回图像空间;所述深层重构块包括四个自注意力块,所述浅层重构块包括两个内核为3×3且步长为1的卷积层,每层后面有relu激活函数。
8、更进一步的,所述深层重构块用于细化融合后的深层特征,并从全局的角度实现多尺度特征重构;通过浅层重构块和卷积层来进一步恢复图像尺寸,然后利用跳过连接来加强特征传递,最大限度地重用不同层的特征以构建融合图像。
9、更进一步的,所述分流注意力transformer网络模型细化过程量化为:
10、
11、
12、
13、
14、ifu=fru(ffus)
15、其中,s(·)表示浅卷积块,in和vi分别表示输入的红外光和可见光图像;safeu(·)是分流注意力特征提取单元,和分别表示红外光和可见光深层粒度特征;cafu(·)表示交叉注意力融合单元,和分别表示经过域内和域间交互后聚合的红外光和可见光输出特征;concat(·)表示通道维度中的级联;fru(·)表示特征重构单元;ffus表示融合后的深度特征;ifu为经过重构和上采样后生成的融合图像。
16、作为更进一步的,所述分流注意力transformer网络模型训练时使用粒度损失函数进行约束,该粒度损失函数包括结构相似性损失、细粒度损失、粗粒度损失;所述粒度损失lg表示为:
17、lg=αls+β(lfg+lcg)
18、其中,ls、lfg和lcg分别表示结构相似性损失、细粒度损失和粗粒度损失;α、β为损失函数超参数。
19、作为更进一步的,结构相似性损失ls为:
20、ls=1-ssim(in,vi,ifu)
21、其中,ifu为融合结果,符号ssim(·)表示结构相似度函数,其定义为:
22、
23、其中,i*代表源图像vi或in;μ和σ分别表示平均值和标准差;c1,c2和c3是维持稳定的常数;
24、细粒度损失lfg、粗粒度损失lcg分别为:
25、
26、
27、其中,||·||1表示l1-norm,max{·}表示按元素最大选择,表示sobel梯度算子,|·|代表绝对值操作;h、w是图像的高和宽,γ是超参数。
28、本发明采用的以上技术方案,与现有技术相比,具有的优点是:分流注意力transformer网络模型在图像之间建立远程依赖关系,提取和集成粒度特征,并通过有效减少token的数量来降低计算成本,生成测试图像的时间效率不仅高于基于transformer的融合方法,还比基于卷积神经网络的融合方法具有优势。本发明通过分流注意力特征提取单元,实现每个注意力层内粗粒度和细粒度特征的联合提取。交叉注意力融合单元充分实现了域内和域间深度特征交互以及跨域信息融合,特征重构单元将特征映射与重构图像结合起来,使得网络模型能够恢复不同分辨率的融合图像。此外,使用由结构相似性损失、细粒度损失和粗粒度损失组成的粒度损失函数来驱动网络,采用粒度信息控制和结构维护以实现特征提取和融合。本发明所提出的分流注意力transformer网络模型生成的融合图像具有更好的视觉感知,包括了足够多的显著特征和纹理细节信息,且时间效率更高。
- 还没有人留言评论。精彩留言会获得点赞!