一种基于改进RFM模型的医保参保人员分类方法
本发明属于数据分析,具体涉及一种基于改进rfm模型的医保参保人员分类方法。
背景技术:
1、近年来,随着医疗保险制度的稳步发展和完善,医保覆盖率不断扩大。伴随医保的普及和保障水平的提升,医保违规形势也变得越来越严峻。面对庞大的参保人用户群体和其产生的海量医保刷卡记录,科学分析参保人的医保记录,将参保人进行分类,能够发现具有违规使用医保行为的高风险参保人群,实现对异常参保人的精准定位。对具有违规风险或倾向的参保人群进行精准监管,能够及时阻止医保违规案件的产生或扩大,是保证医保基金安全的有效手段。
2、rfm模型是目前在衡量用户价值和用户细分领域常用的方法,其中最近消费时间(recency)表示用户上一次消费时间到统计节点的时间间隔;消费频率(frequency)表示在统计时间段内用户的总购买次数;消费金额(monetary)表示用户在统计时间段内用户的总购买金额。rfm模型本质上就是通过三个维度对一段时间里的用户消费行为进行组合计算,将用户分为多个类型或等级,然后对不同类型的用户群体采取不同措施。
3、然而,现有rfm模型在对医保参保人进行分类时面临许多问题。第一,传统rfm模型在建模时考虑的数据特征较少,鉴于如今形式多样的医保违规行为,例如医保卡转借他人使用、本人多地多次购药等,仅在最近消费时间、消费频率和消费金额上对医保参保人进行分类不足以精确划分违规人员集合。第二,传统rfm模型中用最近消费时间(recency)来反应用户粘性,而参保人在购药的时间维度上具有随机性,最近消费时间这个指标不能够确切地揭示参保人使用医保的时间长短,购药间隔短的风险参保人无法被有效识别;消费金额(monetary)对参保人购药刷卡行为的风险识别不敏感,因为在购药环节上药品的价格往往不会是购买该药品与否的考虑因素。第三,经典的k-means算法作为一种最常用的聚类算法,常与rfm模型结合使用来对用户进行分类。然而传统k-means算法存在一定局限性,首先k值的选取是由人为设定的,而依靠人工经验选取合适的k值十分困难。其次k-means的初始聚类中心是随机选取的,这样容易导致算法收敛很慢,对运行时间和最后的结果都有很大影响。另外当数据的特征增加、出现噪音维度或者各特征的重要性并不一致时,算法在计算样本间距离时一并统一考虑,最终导致聚类精度下降。
技术实现思路
1、本发明的目的在于针对上述问题,提出一种基于改进rfm模型的医保参保人员分类方法,能够精准监管具有医保违规风险的参保人群,更加智能化。
2、为实现上述目的,本发明所采取的技术方案为:
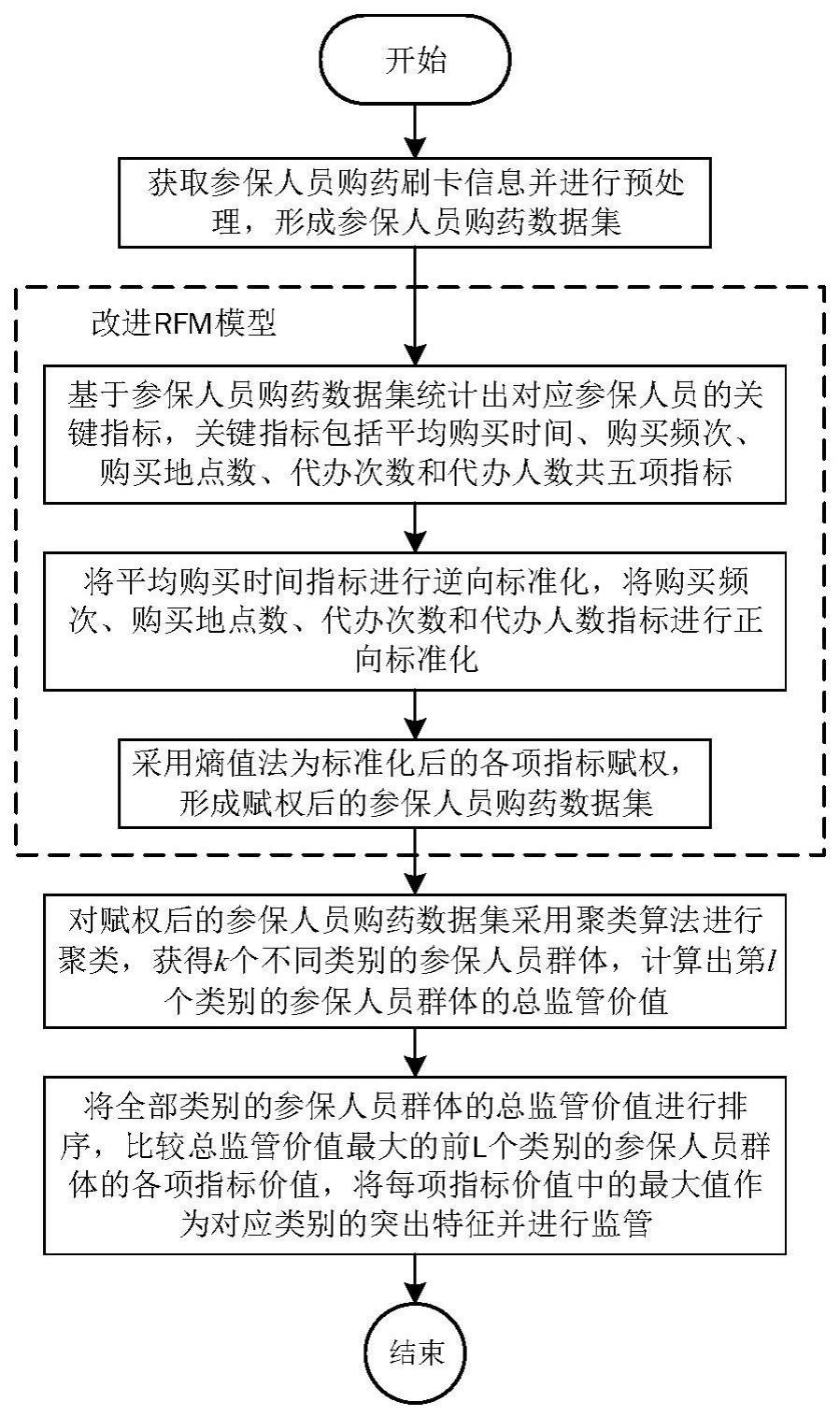
3、本发明提出的一种基于改进rfm模型的医保参保人员分类方法,包括如下步骤:
4、s1、获取参保人员购药刷卡信息并进行预处理,形成参保人员购药数据集;
5、s2、建立改进rfm模型,改进rfm模型执行如下操作:
6、s21、基于参保人员购药数据集统计出对应参保人员的关键指标,关键指标包括平均购买时间r1、购买频次f、购买地点数p、代办次数s和代办人数s1共五项指标,购买地点数p为对刷卡药店编号集合去重后的元素个数,代办人数s1为对代办人身份证号集合去重后的元素个数,平均购买时间r1计算如下:
7、
8、式中,tlast_time表示在预设参考时间段内参保人员最后一次购药的时间,tfirst_time表示在预设参考时间段内参保人员第一次购药的时间;
9、s22、将平均购买时间r1指标进行逆向标准化,将购买频次f、购买地点数p、代办次数s和代办人数s1指标进行正向标准化;
10、s23、采用熵值法为标准化后的各项指标赋权,形成赋权后的参保人员购药数据集,各项指标的赋权公式如下:
11、vi′j=wjvij,j=1,...,5
12、式中,wj为第j项指标的权重,vij为第i个参保人员的第j项指标的标准化值,vi′j为第i个参保人员的第j项指标赋权后的值;
13、s3、对赋权后的参保人员购药数据集采用聚类算法进行聚类,获得k个不同类别的参保人员群体,计算出第l个类别的参保人员群体的总监管价值vl,公式如下:
14、
15、式中,表示第l个类别的平均购买时间的指标价值,fl表示第l个类别的购买频次的指标价值,pl表示第l个类别的购买地点数的指标价值,sl表示第l个类别的代办次数的指标价值,表示第l个类别的代办人数的指标价值,指标价值即为对应指标的平均值;
16、s4、将全部类别的参保人员群体的总监管价值进行排序,比较总监管价值最大的前l个类别的参保人员群体的各项指标价值,l≤k,将每项指标价值中的最大值作为对应类别的突出特征并进行监管。
17、优选地,预处理,具体如下:
18、s11、筛选出预设参考时间段的参保人员购药刷卡信息;
19、s12、在筛选出的参保人员购药刷卡信息中过滤掉具有缺失值、异常数据和冗余数据的参保人员购药刷卡信息;
20、s13、在余留的参保人员购药刷卡信息中筛选字段,字段包括医保卡主身份证号、刷卡时间、刷卡药店编号、是否代办购药和代办人身份证号。
21、优选地,缺失值为预设参考时间段内只有单次购药记录的参保人员购药刷卡信息,异常数据为身份校验失败、药店编号校验失败的参保人员购药刷卡信息,冗余数据为单次购药时由于人脸比对不成功而进行多次比对时产生的冗余失败购药记录。
22、优选地,逆向标准化,公式如下:
23、
24、正向标准化,公式如下:
25、
26、式中,vij为第i个参保人员的第j项指标的标准化值,xij为第i个参保人员的第j项指标值,i=1,2,...,n,n为参保人员购药数据集中的参保人员总数,依次将平均购买时间r1、购买频次f、购买地点数p、代办次数s和代办人数s1编号为第1~5项指标。
27、优选地,第j项指标的权重wj计算如下:
28、
29、其中,
30、
31、
32、式中,ej为第j项指标的信息熵值,pij为第i个参保人员的第j项指标所占比重。
33、优选地,聚类算法,执行如下操作:
34、s31、遍历预设分类簇数t的取值,对每一个t值进行初始聚类并计算对应的总轮廓系数,t=2~m,m为预设数值;
35、s32、将轮廓系数最大时对应的t值作为最佳分类簇数k;
36、s33、根据最佳分类簇数k基于k-means++算法对赋权后的参保人员购药数据集进行聚类。
37、优选地,总轮廓系数,计算如下:
38、获取第i个参保人员的轮廓系数s(i):
39、
40、式中,a(i)表示第i个参保人员与所在聚类簇中所有其他参保人员的平均距离;b(i)表示第i个参保人员与最近聚类簇中所有参保人员的平均距离;
41、将所有参保人员的轮廓系数的平均值作为当前初始聚类的总轮廓系数。
42、与现有技术相比,本发明的有益效果为:
43、本发明充分考虑了违规购药的特点,将购药地点数、代办次数和代办人数作为数据特征,并将传统rfm模型中的最近购买时间替换为平均购买时间,并去除消费金额这个噪音维度,通过结合更多关键指标使得对违规参保人的分类结果更加准确;通过熵值法对各指标赋权,并对赋权后的参保人员购药数据集采用聚类算法进行聚类,使聚类更合理、效果更显著;将最终的分类结果按照总监管价值和在改进rfm模型指标上的表现,确定参保人员的风险来源,从而为医保参保人员的监管提供决策支持,该方法不仅能够从多个指标对参保人员购药刷卡行为进行分析,将参保人员按照对应的违规风险进行准确分类,以方便精准监管具医保违规风险的参保人群,还能够直观地反映每一个类别的参保人员的购药特征,能够针对性的对不同参保人员群体采取不同监管手段,让医保监管工作更加智能化。
- 还没有人留言评论。精彩留言会获得点赞!