基于特征存储库与对比学习的半监督目标检测方法
本发明涉及图像处理和计算机视觉领域,特别是涉及半监督学习下的目标检测方法。
背景技术:
1、目标检测(object detection)是计算机视觉和数字图像处理的一个热门方向,能够实现目标物体类别和位置的自动检测,减少人力、资本的消耗,具有重要的现实意义。与更为基础的图片分类任务相比,目标检测多出一个回归任务,即不仅要用算法判断图片中是否存在对象,还要在图片中标记出它的位置,对图像上标注的标定框进行回归预测。
2、近年来,由于深度学习的广泛运用,目标检测算法得到了较为快速的发展。然而通常的全监督目标检测模型是基于大量人工精确标注的数据集训练的,这些方法要求每一张训练的图像都有精确充分的高质量标注。而往往一张图像中有多个物体,各自可能属于不同类别,这些都需要人工一一进行标注;有的物体更是由于本身物体较小、环境影响或图像失真导致肉眼难以辨认,更进一步地增加了标注数据集所需的时间与精力。因此,为了降低标注带来的大量人力消耗,如何充分使用小样本的标注数据集成为研究的一大热点。
3、基于此出发,半监督学习试图在小样本的标注数据上利用更多易于获得的无标注数据来增强模型性能。目前多数半监督目标检测方法受限于伪标签精度较低等问题,最终效果与全监督目标检测方法仍有较大差距。因此开展半监督目标检测方法的进一步研究具有重要的意义。
技术实现思路
1、目前国内外现有半监督目标检测方法未能充分挖掘监督信息。现有的半监督目标检测方法,通常采用一致性损失的方法,如公开号为cn112926673a的中国专利公开了基于一致性约束的半监督目标检测方法,该方法对图像不同增强的预测结果求取一致性损失以优化模型,但该装置未能进一步建模已有标签数据和无标签数据之间的联系。又如公开号为cn114399683a的中国专利公开了一种基于改进yolov5的端到端半监督目标检测方法,该方法迭代地生成伪标签用于新的模型训练过程,但该方法受伪标签噪声的影响较大,需要进一步引入额外信息为伪标签的生成提供监督和引导。
2、为此本文设计了基于特征存储库与对比学习的半监督目标检测方法,使用特征存储库用于存储高质量特征向量,并用对比学习对无标签数据的特征向量进行约束,能够建立有标签数据对无标签数据的额外监督信息,规范模型的训练,优化训练的方向,提升了模型的性能,具有现实意义和良好应用前景。
3、本发明的具体内容如下:
4、一种基于的包括以下步骤:
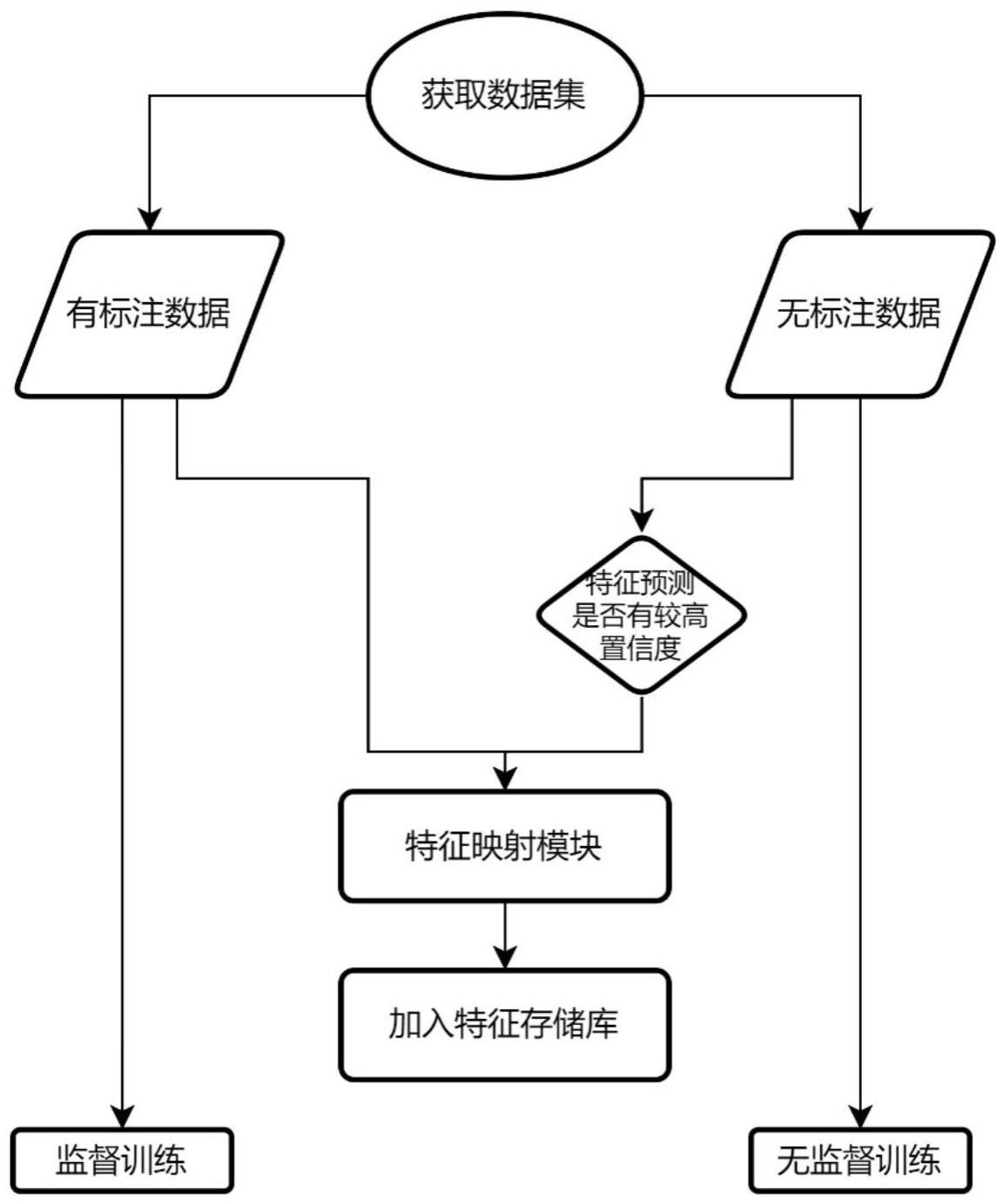
5、第一步,获取半监督目标检测数据集{dl,du},其中有标签部分数据集为无标签数据集为nl,nu分别为有标签图像和无标签图像的个数,为图像的标签信息。ci为第i张图像的各标定框真值类别标签,bi为第i张图像的各标定框真值标定框坐标标签。
6、第二步,构建目标检测模型,模型包括特征提取模块区域生成模块输出预测模块其中f为输入预测模块的特征向量,b为选取的标定框位置信息;各模块由数层卷积神经网络层或全连接层堆叠而成。对于输入xi,区域生成模块输出的区域生成结果为输出预测模块输出的预测结果为其中为预测的类别向量,为预测出的各标定框值。
7、第三步,建立特征存储库用于存储各类别的特征向量。其大小为c×t×d,c为数据集类别数,t为存储库某一类别向量存储个数,d为存储特征向量的维数。存储库采用先入先出(fifo,first in first out)的队列存储模式,若当前存储向量总数将超过大小t,则将最先加入库中的向量出库,最新特征向量入库。
8、第四步,建立特征映射模块将选取的区域b对应的特征f映射为更低维度的特征向量fproj;
9、第五步,对于有标签数据dl中的图像数据获取真值标定框标注区域对应映射特征向量各区域对应类别为根据类别将各区域的映射特征向量存入特征存储库中
10、第六步,对于无标签数据du中的图像数据首先,使用区域生成模块获取兴趣区域标定框筛选出可靠特征向量,然后获取符合条件的各标定框区域对应映射特征向量各区域对应类别为根据类别将各区域的映射特征向量存入特征存储库中。
11、第七步,构建对比学习损失函数。对于无标签数据中的全部预测结果若预测类别为的标定框特征被采样,则其对应的对比损失函数形式为为当前图像采样标定框数目。其中pv和nv分别为正负样本特征向量集合,集合中的特征向量来自特征存储库,pv正样本集合由与vu同属类别c的向量组成,nv则由全部其他类别的向量组成;sim(·,·)为向量相似度度量方式。
12、第八步,在有标签数据dl上使用通常的分类损失和回归损失作为损失函数进行训练,有标签数据的总损失函数为在无标签数据du上则采用自训练损失或一致性损失优化模型,记为其中,自训练方法使用教师学生模型,使用教师模型生成伪标签供学生模型训练;一致性方法使用一张图像的不同变换作为输入,计算不同变换下预测的差异。无标签数据的总损失函数为
13、第九步,使用随机梯度下降方法优化损失函数,训练模型,重复五~八步的过程,迭代多次直到模型预测结果稳定且最优。
14、所述第二步中的各模块具体作用与步骤包括:
15、一、特征提取模块提取图像特征。该模块首先对所述训练图像进行预处理,其次运用常见特征提取网络对所述训练图像进行特征提取。典型的特征提取网络包括vgg(https://arxiv.org/pdf/1409.1556,very deep convolutional networks,2014),resnet(https://arxiv.org/pdf/1512.03385.pdf,deep residual learning for imagerecognition,2015),mobilenet(https://arxiv.org/pdf/1704.04861,mobilenets:efficient convolutional neural networks for mobile vision applications,2017),retinanet(https://arxiv.org/pdf/1708.02002,focal loss for dense objectdetection,2018)或efficientnet(https://arxiv.org/pdf/1905.11946,efficientnet:rethinking model scaling for convolutional neural networks,2019);进一步地,特征提取网络与特征加工网络结合,对图像特征做进一步提取与优化,典型的特征加工网络包括bam(https://arxiv.org/pdf/1807.06514,bam:bottleneck attention module,2018),cbam,spp(https://arxiv.org/pdf/1406.4729,spatial pyramid pooling indeep convolutional networks for visual recognition,2014),fpn(https://arxiv.org/pdf/1612.03144,feature pyramid networks for object detection,2016)和/或nas-fpn(https://arxiv.org/pdf/1904.07392,nas-fpn:learning scalablefeature pyramid architecture for object detection,2019);
16、二、区域生成模块生成候选区域,其输入为图像xi,生成的候选区域(标定框)与图像特征(f)共同作为输出预测模块的输入。该模块即为一阶段目标检测方法的密集检测框生成器或二阶段目标检测方法的区域提出网络(rpn,region proposal network)来生成候选区域;
17、三、输出预测模块预测目标的种类c与位置b。该模块首先对候选区域内的特征进行roi pooling/align即为一阶段密集预测的yolo网络(https://arxiv.org/pdf/1506.02640,you only look once:unified,real-time object detection,2015),二阶段精炼预测的faster rcnn(https://arxiv.org/pdf/1506.01497,faster r-cnn:towardsreal-time object detection with region proposal networks,2015)网络或者无锚框的centernet网络;
18、所述第三步中,为避免gpu显存的过多占用,特征维度d通常取值为128或256。
19、所述第四步中,特征映射模块采用mlp多层感知机,其结构为全连接层->relu激活层->批归一化->全连接层。
20、所述第五及第六步中,特征向量存入特征存储库时,若库中相应类别存储个数已满,则遵循先入先出原则将最早加入的特征向量剔除,并将现有的新特征向量存入。
21、所述第六步中的可靠特征向量筛选由各兴趣区域候选框的类别预测分数决定。若该兴趣区域候选框的最高类别预测分类得分大于阈值θ,则该候选框对应的特征向量被视为可靠特征向量。
22、所述第七步中,相似度度量方式sim(·,·)有多种实现方式,对于任意两个不同的特征向量xi和xj,使用向量点乘mlp层映射计算向量余弦距离高斯方法来衡量两者间相似度。对比学习损失函数的作用在于将相同类别的特征样本在高维特征空间中拉近,而不同类别的样本则拉远,与特征存储库结合可以有效建立起标签信息对无标签数据的指引。
23、所述第九步中,迭代终止的标准须以模型的最终损失在最后数个迭代中趋于平稳而无明显下降为准,而非在单轮迭代中损失平稳。
24、与现有技术相比,本发明具有如下创新点:
25、1.其他使用伪标签的技术方法仅通过人为设置阈值来筛选可靠的伪标签,这样生成的伪标签质量较差,有大量分类或定位错误的噪声,这些噪声会妨害模型的训练。本方法从标签数据中提取额外的信息,为无标签数据提供可靠的训练方向,能够指导模型生成高质量的伪标签信息,并用对比学习保证了这一思想的实现,最终获得了更好的模型预测效果。
26、2.其他使用一致性损失的技术未能建立无标签数据和有标签数据之间的信息关联,缺少跨子数据集的信息沟通渠道。特征存储库能够建立这一关联,并用对比学习进行规范与引导,获得更好的模型预测效果。
27、3.经实验,在控制其他因素不变的情况下,不采用特征存储库与对比学习的模型预测的平均准确度map为21%,而采用后方法的map达到了25%,证明了方法的有效性(该模型仅用于方法有效性测试,其数值结果不代表模型实际使用效果)。
28、根据本技术实施例提供的方法执行流程,运行在例如个人计算机、服务器、嵌入式计算设备、云计算平台等设备中。
- 还没有人留言评论。精彩留言会获得点赞!