一种文本获取方法及其相关设备与流程
本技术实施例涉及人工智能(artificial intelligence,ai)领域,尤其涉及一种文本获取方法及其相关设备。
背景技术:
1、随着ai技术的快速发展,越来越多的用户使用预训练的神经网络模型(也可以称为预训练模型),来完成针对呈现有多个文本的图像的分析处理,也就是说,预训练的神经网络模型可以对图像进行充分理解,以从图像所呈现的多个文本中,提取出目标文本。
2、相关技术中,预训练的神经网络模型可以包含编码器和解码器。当需要从图像所呈现的多个文本中提取目标文本时时,可将图像输入至神经网络模型中。那么,编码器可对图像进行编码,从而得到图像的特征,并将图像的特征提供给解码器。然后,解码器可基于图像的特征进行解码,从而得到目标文本。
3、上述过程中,神经网络模型是基于图像的特征,来对图像的内容进行理解,以从图像所呈现的多个文本中提取出目标文本。但是,神经网络模型在对图像进行理解时,所考虑的因素较为单一,导致模型最终得到的目标文本可能不是准确的文本。
技术实现思路
1、本技术实施例提供了一种文本获取方法及其相关设备,可从目标图像中获取准确的目标文本。
2、本技术实施例的第一方面提供了一种文本获取方法,该方法通过目标模型实现,该方法包括:
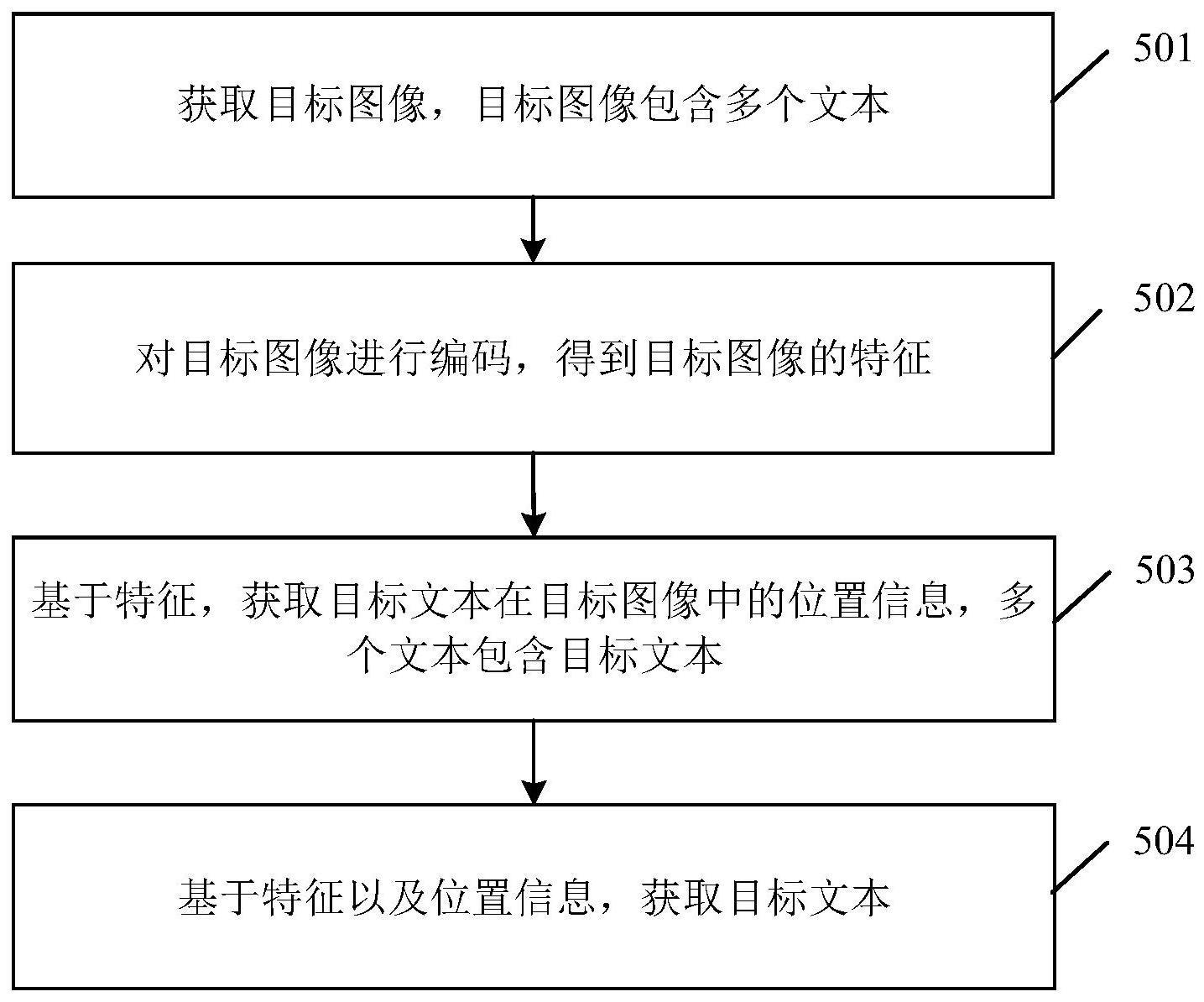
3、当需要从包含目标图像中获取目标文本时,可先获取目标图像。需要说明的是,目标图像所呈现的内容包含多个文本,多个文本包含所需获取的目标文本。
4、得到目标图像后,可将目标图像输入至目标模型,故目标模型可先对目标图像进行编码,从而得到目标图像的特征。得到目标图像的特征后,目标模型可对目标图像的特征进行处理,从而得到目标文本在目标图像中的位置信息。得到目标文本在目标图像中的位置信息后,解码器可对目标图像的特征以及目标文本在目标图像中的位置信息做进一步的处理,从而得到目标文本。
5、需要说明的是,目标模型的输入不仅包含外部输入的目标图像,还包含自身得到的目标文本在目标图像中的位置信息,目标模型对外的输出不仅包含目标文本,还包含目标文本在目标图像中的位置信息,也就是说,目标文本和目标文本在目标图像中的位置信息为目标模型的两个输出。至此,则成功从目标图像中获取到了目标文本。
6、从上述方法可以看出:当需要从目标图像中提取目标文本时,可先获取包含多个文本的目标图像,并将目标图像输入至目标模型。接着,目标模型可对目标图像进行编码,从而得到目标图像的特征。然后,目标模型可对目标图像的特征进行处理,从而得到多个文本中的目标文本在目标图像中的位置信息。最后,目标模型可对目标图像的特征以及目标文本在目标图像中的位置信息做进一步的处理,从而得到目标文本。至此,则成功从目标图像中提取出了目标文本。前述过程中,目标模型在对目标图像的内容进行理解时,不仅考虑了目标图像的特征,还考虑了目标文本在目标图像中的位置信息,这样考虑的因素较为全面,可以对目标图像的内容进行充分且准确的理解,由此可见,目标模型按照这种方式从目标图像所呈现的多个文本中提取出的目标文本,通常是正确的文本。
7、在一种可能实现的方式中,基于特征,获取目标文本在目标图像中的位置信息包括:基于特征,对目标文本在目标图像中的位置信息的第1个向量表示至位置信息的第i个向量表示进行解码,得到位置信息的第i+1个向量表示,i=1,...,x-1,x≥1,位置信息的第1个向量表示基于特征对预置的向量表示进行解码得到。前述实现方式中,若目标文本的数量为一个,在得到目标图像的特征后,目标模型可先基于目标图像的特征,对预置的向量表示进行解码,从而得到目标文本在目标图像中的位置信息的第1个向量表示。接着,目标模型可基于目标图像的特征,对目标文本在目标图像中的位置信息的第1个向量表示进行解码,从而得到目标文本在目标图像中的位置信息的第2个向量表示,...,最后,目标模型可基于目标图像的特征,对目标文本在目标图像中的位置信息的第1个向量表示至目标文本在目标图像中的位置信息的第x-1个向量表示进行解码,从而得到目标文本在目标图像中的位置信息的第x个向量表示。如此一来,目标模型可以准确得到以向量表示形式呈现的目标文本在目标图像中的位置信息。
8、在一种可能实现的方式中,基于特征以及位置信息,获取目标文本包括:基于特征,对位置信息,目标文本的第1个向量表示至目标文本的第j个向量表示进行解码,得到目标文本的第j+1个向量表示,j=1,...,y-1,y≥1,目标文本的第1个向量表示基于特征对位置信息进行解码得到。前述实现方式中,若目标文本的数量为一个,在得到目标文本在目标图像中的位置信息后,目标模型可先基于目标图像的特征,对目标文本在目标图像中的位置信息进行解码,从而得到目标文本的第1个向量表示。接着,目标模型可基于目标图像的特征,对目标文本在目标图像中的位置信息以及目标文本的第1个向量表示进行解码,从而得到目标文本的第2个向量表示,...,最后,目标模型可基于目标图像的特征,对目标文本在目标图像中的位置信息,目标文本的第1个向量表示至目标文本的第y-1个向量表示进行解码,从而得到目标文本的第y个向量表示。如此一来,目标模型可以准确得到以向量表示形式呈现的目标文本。
9、在一种可能实现的方式中,目标文本包含第一文本以及第二文本,位置信息包含第一文本在目标图像中的第一位置信息以及第二文本在目标图像中的第二位置信息,基于特征,获取目标文本在目标图像中的位置信息包括:基于特征,对第一位置信息的第1个向量表示至第一位置信息的第i个向量表示进行解码,得到第一位置信息的第i+1个向量表示,i=1,...,x-1,x≥1,第一位置信息的第1个向量表示基于特征对预置的向量表示进行解码得到;基于特征,对第一位置信息,第一文本,第二位置信息的第1个向量表示至第二位置信息的第k个向量表示进行解码,得到第一位置信息的第k+1个向量表示,k=1,...,z-1,z≥1,第二位置信息的第1个向量表示基于特征对第一位置信息以及第一文本进行解码得到。前述实现方式中,若目标文本的数量为两个,可将这两个目标文本分别称为第一文本以及第二文本。在得到目标图像的特征后,目标模型可先基于目标图像的特征,对预置的向量表示进行解码,从而得到第一文本在目标图像中的第一位置信息的第1个向量表示。接着,目标模型可基于目标图像的特征,对第一位置信息的第1个向量表示进行解码,从而得到第一位置信息的第2个向量表示,...,最后,目标模型可基于目标图像的特征,对第一位置信息的第1个向量表示至第一位置信息的第x-1个向量表示进行解码,从而得到第一位置信息的第x个向量表示。如此一来,目标模型可得到完整的以向量表示形式呈现的第一位置信息。得到第一位置信息后,目标模型可基于目标图像的特征,对第一位置信息进行处理,从而得到第一文本。得到第一文本后,目标模型可先基于目标图像的特征,对第一位置信息以及第一文本进行解码,从而得到第二文本在目标图像中的第二位置信息的第1个向量表示。接着,目标模型可基于目标图像的特征,对第一位置信息、第一文本以及第二位置信息的第1个向量表示进行解码,从而得到第二位置信息的第2个向量表示,...,最后,目标模型可基于目标图像的特征,对第一位置信息、第一文本、第二位置信息的第1个向量表示至第二位置信息的第z-1个向量表示进行解码,从而得到第二位置信息的第z个向量表示。如此一来,目标模型可以准确得到以向量表示形式呈现的第二位置信息。
10、在一种可能实现的方式中,基于特征以及位置信息,获取目标文本包括:基于特征,对第一位置信息,第一文本的第1个向量表示至第一文本的第j个向量表示进行解码,得到第一文本的第j+1个向量表示,j=1,...,y-1,y≥1,第一文本的第1个向量表示基于特征对位置信息进行解码得到;基于特征,对第一位置信息,第一文本,第二位置信息,第二文本的第1个向量表示至第二文本的第t个向量表示进行解码,得到第二文本的第t+1个向量表示,t=1,...,u-1,u≥1,第二文本的第1个向量表示基于特征对第一位置信息,第一文本以及第二位置信息进行解码得到。前述实现方式中,若目标文本的数量为两个,可将这两个目标文本分别称为第一文本以及第二文本。在得到第一文本在目标图像中的第一位置信息后,目标模型可先基于目标图像的特征,对第一位置信息进行解码,从而得到第一文本的第1个向量表示。接着,目标模型可基于目标图像的特征,对第一位置信息以及第一文本的第1个向量表示进行解码,从而得到第一文本的第2个向量表示,...,最后,目标模型可基于目标图像的特征,对第一位置信息,第一文本的第1个向量表示至第一文本的第y-1个向量表示进行解码,从而得到第一文本的第y个向量表示。如此一来,目标模型可以得到以向量表示形式呈现的第一文本。得到第一文本后,目标模型可基于目标图像的特征,对第一位置信息以及第一文本进行处理,从而得到第二文本在目标图像中的第二位置信息。得到第二文本在目标图像中的第二位置信息后,目标模型可先基于目标图像的特征,对第一位置信息、第一文本以及第二位置信息进行解码,从而得到第二文本的第1个向量表示。接着,目标模型可基于目标图像的特征,对第一位置信息、第一文本、第二位置信息以及第二文本的第1个向量表示进行解码,从而得到第二文本的第2个向量表示,...,最后,目标模型可基于目标图像的特征,对第一位置信息、第一文本、第二位置信息、第二文本的第1个向量表示至第二文本的第u-1个向量表示进行解码,从而得到第二文本的第u个向量表示。如此一来,目标模型可以准确得到以向量表示形式呈现的第二文本。
11、在一种可能实现的方式中,该方法还包括:对位置信息的所有向量表示进行转换,得到目标文本在目标图像中所占据的区域的坐标。前述实现方式中,目标模型可将以向量表示形式呈现的目标文本(在目标图像中)的位置信息转换为以坐标形式呈现的目标文本的位置信息,以为用户提供目标文本在目标图像中的可视化效果。
12、在一种可能实现的方式中,该方法还包括:对目标文本的所有向量表示进行转换,得到目标文本的所有字符。前述实现方式中,目标模型还可将以向量表示形式呈现的目标文本转换为以字符(文字)形式呈现的目标文本,进一步为用户提供目标文本在目标图像中的可视化效果。
13、在一种可能实现的方式中,目标模型对目标文本以及位置信息所执行的转换可以为以下至少一种:基于循环神经网络的特征提取、基于多层感知机的特征提取以及基于时间卷积网络的特征提取。
14、在一种可能实现的方式中,区域的坐标为以下至少一种:区域的左上角的顶点坐标以及区域的右下角的顶点坐标;或,区域的右上角的顶点坐标以及区域的左下角的顶点坐标;或,区域的四个角的顶点坐标;或,区域的左上角的顶点坐标、区域的左下角的顶点坐标以及区域的中心点坐标;或,区域的右上角的顶点坐标、区域的右下角的顶点坐标以及区域的中心点坐标;或,区域的右上角的顶点坐标、区域的左上角的顶点坐标以及区域的中心点坐标;或,区域的右下角的顶点坐标、区域的左下角的顶点坐标以及区域的中心点坐标;或,区域的右上角的顶点坐标、区域的右下角的顶点坐标、区域的左上角的顶点坐标、区域的左下角的顶点坐标以及区域的中心点坐标。
15、本技术实施例的第二方面提供了一种模型训练方法,该方法包括:获取目标图像,目标图像包含多个文本;通过待训练模型对目标图像进行处理,得到目标文本在目标图像中的位置信息以及目标文本,多个文本包含目标文本,待训练模型用于:对目标图像进行编码,得到目标图像的特征;基于特征,获取位置信息;基于特征以及位置信息,获取目标文本;基于目标文本,对待训练模型进行训练,得到目标模型。
16、上述方法训练得到的目标文本,具备文本获取功能。具体地,当需要从目标图像中提取目标文本时,可先获取包含多个文本的目标图像,并将目标图像输入至目标模型。接着,目标模型可对目标图像进行编码,从而得到目标图像的特征。然后,目标模型可对目标图像的特征进行处理,从而得到多个文本中的目标文本在目标图像中的位置信息。最后,目标模型可对目标图像的特征以及目标文本在目标图像中的位置信息做进一步的处理,从而得到目标文本。至此,则成功从目标图像中提取出了目标文本。前述过程中,目标模型在对目标图像的内容进行理解时,不仅考虑了目标图像的特征,还考虑了目标文本在目标图像中的位置信息,这样考虑的因素较为全面,可以对目标图像的内容进行充分且准确的理解,由此可见,目标模型按照这种方式从目标图像所呈现的多个文本中提取出的目标文本,通常是正确的文本。
17、在一种可能实现的方式中,待训练模型,用于基于特征,对目标文本在目标图像中的位置信息的第1个向量表示至位置信息的第i个向量表示进行解码,得到位置信息的第i+1个向量表示,i=1,...,x-1,x≥1,位置信息的第1个向量表示基于特征对预置的向量表示进行解码得到。
18、在一种可能实现的方式中,待训练模型,用于基于特征,对位置信息,目标文本的第1个向量表示至目标文本的第j个向量表示进行解码,得到目标文本的第j+1个向量表示,j=1,...,y-1,y≥1,目标文本的第1个向量表示基于特征对位置信息进行解码得到。
19、在一种可能实现的方式中,目标文本包含第一文本以及第二文本,位置信息包含第一文本在目标图像中的第一位置信息以及第二文本在目标图像中的第二位置信息,待训练模型,用于:基于特征,对第一位置信息的第1个向量表示至第一位置信息的第i个向量表示进行解码,得到第一位置信息的第i+1个向量表示,i=1,...,x-1,x≥1,第一位置信息的第1个向量表示基于特征对预置的向量表示进行解码得到;基于特征,对第一位置信息,第一文本,第二位置信息的第1个向量表示至第二位置信息的第k个向量表示进行解码,得到第一位置信息的第k+1个向量表示,k=1,...,z-1,z≥1,第二位置信息的第1个向量表示基于特征对第一位置信息以及第一文本进行解码得到。
20、在一种可能实现的方式中,待训练模型,用于:基于特征,对第一位置信息,第一文本的第1个向量表示至第一文本的第j个向量表示进行解码,得到第一文本的第j+1个向量表示,j=1,...,y-1,y≥1,第一文本的第1个向量表示基于特征对位置信息进行解码得到;基于特征,对第一位置信息,第一文本,第二位置信息,第二文本的第1个向量表示至第二文本的第t个向量表示进行解码,得到第二文本的第t+1个向量表示,t=1,...,u-1,u≥1,第二文本的第1个向量表示基于特征对第一位置信息,第一文本以及第二位置信息进行解码得到。
21、在一种可能实现的方式中,待训练模型,还用于对位置信息的所有向量表示进行转换,得到目标文本在目标图像中所占据的区域的坐标。
22、在一种可能实现的方式中,待训练模型,还用于对目标文本的所有向量表示进行转换,得到目标文本的所有字符。基于目标文本,对待训练模型进行训练,得到目标模型包括:基于字符以及坐标,对待训练模型进行训练,得到目标模型。
23、在一种可能实现的方式中,待训练模型对目标文本以及位置信息所执行的转换可以为以下至少一种:基于循环神经网络的特征提取、基于多层感知机的特征提取以及基于时间卷积网络的特征提取。
24、在一种可能实现的方式中,区域的坐标为以下至少一种:区域的左上角的顶点坐标以及区域的右下角的顶点坐标;或,区域的右上角的顶点坐标以及区域的左下角的顶点坐标;或,区域的四个角的顶点坐标;或,区域的左上角的顶点坐标、区域的左下角的顶点坐标以及区域的中心点坐标;或,区域的右上角的顶点坐标、区域的右下角的顶点坐标以及区域的中心点坐标;或,区域的右上角的顶点坐标、区域的左上角的顶点坐标以及区域的中心点坐标;或,区域的右下角的顶点坐标、区域的左下角的顶点坐标以及区域的中心点坐标;或,区域的右上角的顶点坐标、区域的右下角的顶点坐标、区域的左上角的顶点坐标、区域的左下角的顶点坐标以及区域的中心点坐标。
25、本技术实施例的第三方面提供了一种文本获取装置,该装置包含目标模型,该装置包括:第一获取模块,用于获取目标图像,目标图像包含多个文本;编码模块,用于对目标图像进行编码,得到目标图像的特征;第二获取模块,用于基于特征,获取目标文本在目标图像中的位置信息,多个文本包含目标文本;第三获取模块,用于基于特征以及位置信息,获取目标文本。
26、从上述装置可以看出:当需要从目标图像中提取目标文本时,可先获取包含多个文本的目标图像,并将目标图像输入至目标模型。接着,目标模型可对目标图像进行编码,从而得到目标图像的特征。然后,目标模型可对目标图像的特征进行处理,从而得到多个文本中的目标文本在目标图像中的位置信息。最后,目标模型可对目标图像的特征以及目标文本在目标图像中的位置信息做进一步的处理,从而得到目标文本。至此,则成功从目标图像中提取出了目标文本。前述过程中,目标模型在对目标图像的内容进行理解时,不仅考虑了目标图像的特征,还考虑了目标文本在目标图像中的位置信息,这样考虑的因素较为全面,可以对目标图像的内容进行充分且准确的理解,由此可见,目标模型按照这种方式从目标图像所呈现的多个文本中提取出的目标文本,通常是正确的文本。
27、在一种可能实现的方式中,第二获取模块,用于基于特征,对目标文本在目标图像中的位置信息的第1个向量表示至位置信息的第i个向量表示进行解码,得到位置信息的第i+1个向量表示,i=1,...,x-1,x≥1,位置信息的第1个向量表示基于特征对预置的向量表示进行解码得到。
28、在一种可能实现的方式中,第三获取模块,用于基于特征,对位置信息,目标文本的第1个向量表示至目标文本的第j个向量表示进行解码,得到目标文本的第j+1个向量表示,j=1,...,y-1,y≥1,目标文本的第1个向量表示基于特征对位置信息进行解码得到。
29、在一种可能实现的方式中,目标文本包含第一文本以及第二文本,位置信息包含第一文本在目标图像中的第一位置信息以及第二文本在目标图像中的第二位置信息,第二获取模块,用于基于特征,对第一位置信息的第1个向量表示至第一位置信息的第i个向量表示进行解码,得到第一位置信息的第i+1个向量表示,i=1,...,x-1,x≥1,第一位置信息的第1个向量表示基于特征对预置的向量表示进行解码得到;基于特征,对第一位置信息,第一文本,第二位置信息的第1个向量表示至第二位置信息的第k个向量表示进行解码,得到第一位置信息的第k+1个向量表示,k=1,...,z-1,z≥1,第二位置信息的第1个向量表示基于特征对第一位置信息以及第一文本进行解码得到。
30、在一种可能实现的方式中,第三获取模块,用于基于特征,对第一位置信息,第一文本的第1个向量表示至第一文本的第j个向量表示进行解码,得到第一文本的第j+1个向量表示,j=1,...,y-1,y≥1,第一文本的第1个向量表示基于特征对位置信息进行解码得到;基于特征,对第一位置信息,第一文本,第二位置信息,第二文本的第1个向量表示至第二文本的第t个向量表示进行解码,得到第二文本的第t+1个向量表示,t=1,...,u-1,u≥1,第二文本的第1个向量表示基于特征对第一位置信息,第一文本以及第二位置信息进行解码得到。
31、在一种可能实现的方式中,该装置还包括:第一转换模块,用于对位置信息的所有向量表示进行转换,得到目标文本在目标图像中所占据的区域的坐标。
32、在一种可能实现的方式中,该装置还包括:第二转换模块,用于对目标文本的所有向量表示进行转换,得到目标文本的所有字符。
33、在一种可能实现的方式中,目标模型对目标文本以及位置信息所执行的转换可以为以下至少一种:基于循环神经网络的特征提取、基于多层感知机的特征提取以及基于时间卷积网络的特征提取。
34、在一种可能实现的方式中,区域的坐标为以下至少一种:区域的左上角的顶点坐标以及区域的右下角的顶点坐标;或,区域的右上角的顶点坐标以及区域的左下角的顶点坐标;或,区域的四个角的顶点坐标;或,区域的左上角的顶点坐标、区域的左下角的顶点坐标以及区域的中心点坐标;或,区域的右上角的顶点坐标、区域的右下角的顶点坐标以及区域的中心点坐标;或,区域的右上角的顶点坐标、区域的左上角的顶点坐标以及区域的中心点坐标;或,区域的右下角的顶点坐标、区域的左下角的顶点坐标以及区域的中心点坐标;或,区域的右上角的顶点坐标、区域的右下角的顶点坐标、区域的左上角的顶点坐标、区域的左下角的顶点坐标以及区域的中心点坐标。
35、本技术实施例的第四方面提供了一种模型训练装置,该装置包括:获取模块,用于获取目标图像,目标图像包含多个文本;处理模块,用于通过待训练模型对目标图像进行处理,得到目标文本在目标图像中的位置信息以及目标文本,多个文本包含目标文本,待训练模型用于:对目标图像进行编码,得到目标图像的特征;基于特征,获取位置信息;基于特征以及位置信息,获取目标文本;训练模块,用于基于目标文本,对待训练模型进行训练,得到目标模型。
36、上述装置训练得到的目标文本,具备文本获取功能。具体地,当需要从目标图像中提取目标文本时,可先获取包含多个文本的目标图像,并将目标图像输入至目标模型。接着,目标模型可对目标图像进行编码,从而得到目标图像的特征。然后,目标模型可对目标图像的特征进行处理,从而得到多个文本中的目标文本在目标图像中的位置信息。最后,目标模型可对目标图像的特征以及目标文本在目标图像中的位置信息做进一步的处理,从而得到目标文本。至此,则成功从目标图像中提取出了目标文本。前述过程中,目标模型在对目标图像的内容进行理解时,不仅考虑了目标图像的特征,还考虑了目标文本在目标图像中的位置信息,这样考虑的因素较为全面,可以对目标图像的内容进行充分且准确的理解,由此可见,目标模型按照这种方式从目标图像所呈现的多个文本中提取出的目标文本,通常是正确的文本。
37、在一种可能实现的方式中,待训练模型,用于基于特征,对目标文本在目标图像中的位置信息的第1个向量表示至位置信息的第i个向量表示进行解码,得到位置信息的第i+1个向量表示,i=1,...,x-1,x≥1,位置信息的第1个向量表示基于特征对预置的向量表示进行解码得到。
38、在一种可能实现的方式中,待训练模型,用于基于特征,对位置信息,目标文本的第1个向量表示至目标文本的第j个向量表示进行解码,得到目标文本的第j+1个向量表示,j=1,...,y-1,y≥1,目标文本的第1个向量表示基于特征对位置信息进行解码得到。
39、在一种可能实现的方式中,目标文本包含第一文本以及第二文本,位置信息包含第一文本在目标图像中的第一位置信息以及第二文本在目标图像中的第二位置信息,待训练模型,用于:基于特征,对第一位置信息的第1个向量表示至第一位置信息的第i个向量表示进行解码,得到第一位置信息的第i+1个向量表示,i=1,...,x-1,x≥1,第一位置信息的第1个向量表示基于特征对预置的向量表示进行解码得到;基于特征,对第一位置信息,第一文本,第二位置信息的第1个向量表示至第二位置信息的第k个向量表示进行解码,得到第一位置信息的第k+1个向量表示,k=1,...,z-1,z≥1,第二位置信息的第1个向量表示基于特征对第一位置信息以及第一文本进行解码得到。
40、在一种可能实现的方式中,待训练模型,用于:基于特征,对第一位置信息,第一文本的第1个向量表示至第一文本的第j个向量表示进行解码,得到第一文本的第j+1个向量表示,j=1,...,y-1,y≥1,第一文本的第1个向量表示基于特征对位置信息进行解码得到;基于特征,对第一位置信息,第一文本,第二位置信息,第二文本的第1个向量表示至第二文本的第t个向量表示进行解码,得到第二文本的第t+1个向量表示,t=1,...,u-1,u≥1,第二文本的第1个向量表示基于特征对第一位置信息,第一文本以及第二位置信息进行解码得到。
41、在一种可能实现的方式中,待训练模型,还用于对位置信息的所有向量表示进行转换,得到目标文本在目标图像中所占据的区域的坐标。
42、在一种可能实现的方式中,待训练模型,还用于对目标文本的所有向量表示进行转换,得到目标文本的所有字符。训练模块,用于基于字符以及坐标,对待训练模型进行训练,得到目标模型。
43、在一种可能实现的方式中,待训练模型对目标文本以及位置信息所执行的转换可以为以下至少一种:基于循环神经网络的特征提取、基于多层感知机的特征提取以及基于时间卷积网络的特征提取。
44、在一种可能实现的方式中,区域的坐标为以下至少一种:区域的左上角的顶点坐标以及区域的右下角的顶点坐标;或,区域的右上角的顶点坐标以及区域的左下角的顶点坐标;或,区域的四个角的顶点坐标;或,区域的左上角的顶点坐标、区域的左下角的顶点坐标以及区域的中心点坐标;或,区域的右上角的顶点坐标、区域的右下角的顶点坐标以及区域的中心点坐标;或,区域的右上角的顶点坐标、区域的左上角的顶点坐标以及区域的中心点坐标;或,区域的右下角的顶点坐标、区域的左下角的顶点坐标以及区域的中心点坐标;或,区域的右上角的顶点坐标、区域的右下角的顶点坐标、区域的左上角的顶点坐标、区域的左下角的顶点坐标以及区域的中心点坐标。
45、本技术实施例的第五方面提供了一种故障预测装置,该装置包括存储器和处理器;存储器存储有代码,处理器被配置为执行代码,当代码被执行时,故障预测装置执行如第一方面或第一方面中任意一种可能的实现方式所述的方法。
46、本技术实施例的第六方面提供了一种模型训练装置,该装置包括存储器和处理器;存储器存储有代码,处理器被配置为执行代码,当代码被执行时,模型训练装置执行如第二方面或第二方面中任意一种可能的实现方式所述的方法。
47、本技术实施例的第七方面提供了一种电路系统,该电路系统包括处理电路,该处理电路配置为执行如第一方面、第一方面中任意一种可能的实现方式、第二方面或第二方面中任意一种可能的实现方式所述的方法。
48、本技术实施例的第八方面提供了一种芯片系统,该芯片系统包括处理器,用于调用存储器中存储的计算机程序或计算机指令,以使得该处理器执行如第一方面、第一方面中任意一种可能的实现方式、第二方面或第二方面中任意一种可能的实现方式所述的方法。
49、在一种可能的实现方式中,该处理器通过接口与存储器耦合。
50、在一种可能的实现方式中,该芯片系统还包括存储器,该存储器中存储有计算机程序或计算机指令。
51、本技术实施例的第九方面提供了一种计算机存储介质,该计算机存储介质存储有计算机程序,该程序在由计算机执行时,使得计算机实施如第一方面、第一方面中任意一种可能的实现方式、第二方面或第二方面中任意一种可能的实现方式所述的方法。
52、本技术实施例的第十方面提供了一种计算机程序产品,该计算机程序产品存储有指令,该指令在由计算机执行时,使得计算机实施如第一方面、第一方面中任意一种可能的实现方式、第二方面或第二方面中任意一种可能的实现方式所述的方法。
53、本技术实施例中,当需要从目标图像中提取目标文本时,可先获取包含多个文本的目标图像,并将目标图像输入至目标模型。接着,目标模型可对目标图像进行编码,从而得到目标图像的特征。然后,目标模型可对目标图像的特征进行处理,从而得到多个文本中的目标文本在目标图像中的位置信息。最后,目标模型可对目标图像的特征以及目标文本在目标图像中的位置信息做进一步的处理,从而得到目标文本。至此,则成功从目标图像中提取出了目标文本。前述过程中,目标模型在对目标图像的内容进行理解时,不仅考虑了目标图像的特征,还考虑了目标文本在目标图像中的位置信息,这样考虑的因素较为全面,可以对目标图像的内容进行充分且准确的理解,由此可见,目标模型按照这种方式从目标图像所呈现的多个文本中提取出的目标文本,通常是正确的文本。
- 还没有人留言评论。精彩留言会获得点赞!