一种基于多模态数据的网络学习资源质量评估方法及系统
本发明属于计算机科学与技术应用领域,具体地说是一种面向开放知识社区中的协同编辑型文档类资源内容的质量智能评估方法,可用于开放知识社区资源质量的评估、预警和优化。
背景技术:
1、网络学习资源是“互联网”+教育体系的核心要素。近年来,开放知识社区以“共建、共享、开放、联通”的特性吸引了各知识领域的专家、研究者和爱好者参与到知识协同构建社区。典型的开放知识社区有维基百科(wikipedia)、google knol、github、百度百科、学习元平台、语雀平台等。该类社区在大量用户的协同编辑中生成了知识共享文档,促进了知识的传承、流通、创作和进化。然而,开放知识社区也因用户群体的知识水平不平衡性和复杂性,致使协同编辑生成的网络学习资源存在一定的质量问题。爆炸性增长的网络学习资源质量良莠不齐,不利于知识的创作和传播。
2、针对开放知识社区中的网络学习资源质量的可靠性问题,各平台主要采用人工审核及参与用户协同共管的方式实现对资源内容质量的保障。例如,维基百科采用“人在回路、参与者审核、管理权限等级划分”的资源质量管控模式,同时利用约束规则实现内容编辑的规范性,达到保障网络学习资源高质量的目的。网络学习资源质量保障相关技术包括:面向学习元平台的审核技术、基于语义基因和信任评估的内容协同编辑的可信度计算、内容进化智能控制模型技术、资源内容协同编辑技术和版本控制技术。但是,现有的技术忽视了用户群体协同编辑的行为数据,未能有效利用网络学习资源共享传播过程中产生的交互行为数据,而且忽略了网络学习资源不同版本之间内容本身的变化,同时市面也比较缺乏该类资源质量的分析报告自动生成技术。
3、指数级增长的网络学习资源和用户群体,使得资源内容的审核工作变得繁重。传统依靠人工审核和机器学习技术的方法不可持续,给知识的创作者、建设者和管理者带来了较大的工作负担。因此,可以结合目前较为前沿的人工智能技术,探索一种可以有效减轻开放知识社区中网络学习资源质量评估任务的智能化方法。
技术实现思路
1、发明目的:本发明要解决的技术问题是:开放知识社区中网络学习资源质量智能化评估的问题。本方法提供了一种可以从资源的编辑行为数据、用户交互行为数据、内容数据和评论数据等多个方面的信息综合生成资源质量评估分析报告的方法,以实现帮助资源内容建设者和管理者减轻网络学习资源内容编辑和审核的负担。
2、技术方案:为实现上述目的,本发明采用的技术方案为:
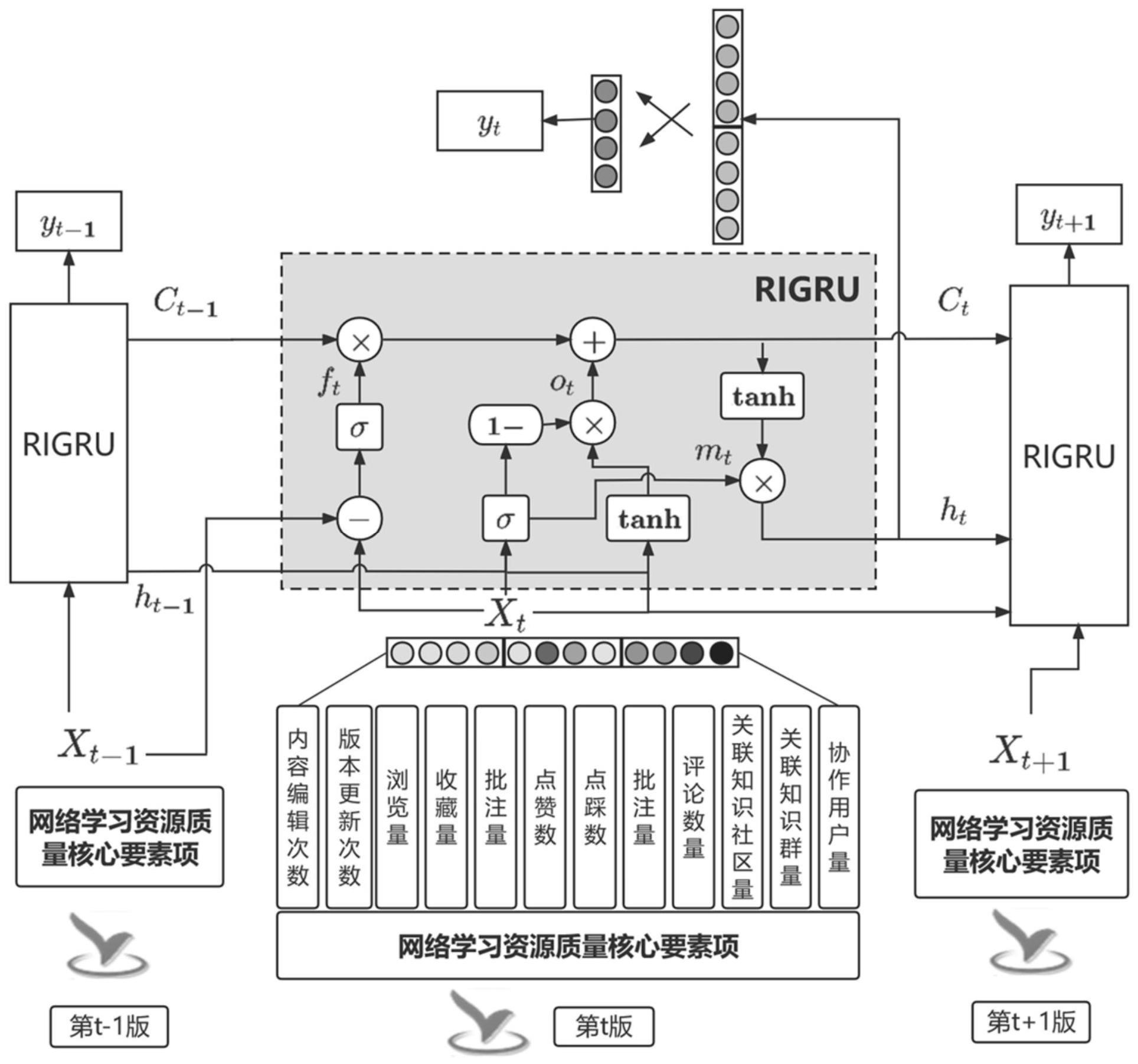
3、一种基于多模态数据的网络学习资源质量评估方法,基于网络学习资源的编辑、更新、访问等离散型外显行为数据,提取网络学习资源质量核心要素项的特征向量。以网络学习资源不同版本内容的文本型数据为关键信息抽取节点,对网络学习资源的标题、摘要、关键词等语义信息进行特征抽取。再将上述两种特征作为学习资源评分预测的特征输入,通过本发明设计的评分预测算法进行评分预测;以网络学习资源的相关评论信息为资源质量评价的参考依据,对评论数据进行情感倾向分析和评价归类。以网络学习资源的不同版本为时间节点,提取该时间段内的评论关键信息,结合上述计算结果,生成网络学习资源质量的分析报告。本发明的网络学习资源质量评估方法,可以实现网络学习资源质量的智能评价,帮助资源建设者多维度掌握资源内容质量,促进网络学习资源内容及时更新优化,具体包括以下步骤:
4、步骤1,采用学习资源信息门控循环单元对网络学习资源质量核心要素项特征进行提取,得到网络学习资源质量核心要素项特征。
5、步骤2,采用三级transformer动态注意力网络对网络学习资源进行评估得到网络学习资源语义特征表示。
6、步骤3:采用循环信息差神经网络ridnn对步骤1得到的网络学习资源质量核心要素项特征和步骤2得到的网络学习资源语义特征表示进行网络学习资源质量评分预测,得到学习资源质量预测评分。
7、步骤4,通过bert预训练模型和textcnn模型对评论数据进行处理,得到网络学习资源评价维度分类。
8、步骤5:根据步骤1得到的网络学习资源质量核心要素项特征、步骤2得到的网络学习资源语义特征表示、步骤3得到的学习资源质量预测评分以及步骤4得到的网络学习资源评价维度分类通过lstm transformer网络生成网络学习资源质量分析报告。
9、优选的:步骤1中采用学习资源信息门控循环单元对网络学习资源质量核心要素项特征进行提取的方法,包括以下步骤:
10、步骤11,将网络学习资源质量核心要素项编码作为循环网络的输入xt,xt表示第t版本的网络学习资源质量核心要素项输入。
11、步骤12,计算ft,ft用于保留第t-1版和第t版学习资源核心要素项的增益信息。
12、ft=sigmoid(xt-xt-1)
13、其中,ft表示不同版本学习资源要素项增益信息特征,sigmoid表示神经网络非线性激活函数,xt表示第t版学习资源要素项特征。
14、步骤13,计算ot,ot用于第t版学习资源核心要素项信息过滤。
15、ot=(1-sigmoid(whoht-1+wxoxt))⊙tanh(whoht-1+wxoxt)
16、其中,ot表示当前核心要素项经过信息过滤后保留重要信息的特征,who表示隐藏层参数,ht-1表示隐藏向量,wxo表示输入层参数,⊙表示矩阵点积。
17、步骤14,计算mt,mt用于保留当前学习资源特征xt和历史特征ht-1提取中的有效信息。
18、mt=sigmoid(whoht-1+wxoxt)
19、其中,mt表示从当前学习资源特征xt和历史特征ht-1提取的特征向量。
20、步骤15,计算ct,ct用于将历史数据信息作为下一个网络单元输入,以实现历史多个版本重要信息的留存。
21、ct=ct-1⊙ft+ot
22、其中,ct表示从历史数据信息中保留的第t版本时的重要信息特征。
23、步骤16,计算ht,ht为当前版本学习资源信息和历史版本学习资源信息提取所得的隐藏层特征。
24、ht=tanh(ct)⊙mt
25、其中,ht表示当前版本学习资源信息和历史版本学习资源信息提取的隐藏层特征,ct表示第t版本时的重要信息特征,tanh表示双曲正切函数。
26、步骤17,计算yt,yt为第t版学习资源核心要素项的特征表示,该特征提取是由隐藏向量ht经过前馈神经网络计算所得,将得到的yt作为资源质量评分预测算法的输入。
27、yt=whyht+bty
28、其中,yt表示第t版本学习资源的评分预测,why表示前馈神经网络的隐藏层参数,ht表示前馈神经网络的隐藏层向量,bty表示前馈神经网络的偏置项。
29、优选的:步骤2中采用三级transformer动态注意力网络对网络学习资源进行评估得到网络学习资源语义特征表示的方法,包括以下步骤:
30、步骤21:将网络学习资源的标题、关键词和摘要通过已经预训练好的词向量将相关内容表示为输入特征矩阵xt1。
31、步骤22:将t-1时刻的输出向量表示y′t-1作为t-1版本的有效信息与t版本的特征进行有效融合,其计算公式为:
32、步骤23:将x′t1作为输入向量,输入到transformer encoder架构中进行第一级的特征计算,其计算公式表示为:ht1=transformencoder(x′t1)。
33、步骤24:将第一级计算所得隐藏层向量ht1输入第二级transformer encoder结构中,以实现关联章节目录信息,其计算公式表示为:其中x′t2表示章节目录内容经过预训练词向量嵌入后的输入。
34、步骤25:将第二级计算所得隐藏层向量ht2输入第三级transformer encoder结构中,以实现关联资源内容信息,其计算公式表示为:其中x′t3表示资源内容经过预训练词向量嵌入后的输入,y′t表示最终经过训练之后所得t版本网络学习资源语义特征表示。
35、使用的注意力机制采用mask函数对其进行优化,
36、
37、其中r,z为超参数,x为输入值。
38、优选的:步骤3中采用循环信息差神经网络ridnn得到学习资源质量预测评分的方法,包括以下步骤:
39、步骤31:将步骤1得到的网络学习资源质量核心要素项特征yt和步骤2得到的网络学习资源语义特征表示y′t作为循环信息差神经网络ridnn的输入。yt和y′t特征首先是进行了向量拼接,其计算公式为其中yt表示两者特征融合之后的特征。
40、步骤32:计算ft。将第t版本的融合特征向量yt与第t-1版本的融合特征向量yt-1做信息差,其计算公式为ft=sigmoid(yt-yt-1)。
41、步骤33:计算mt。结合信息差特征和当前版本的特征,计算mt,以实现当前版本中信息变化量的蒸馏。其计算公式为mt=ft⊙tanh(mt)。
42、步骤34:计算ht。计算隐藏层向量ht,即可作为下一阶段历史信息的输入,也可作为输出向量。其计算公式为
43、步骤35:计算表示为学习资源质量预测评分,该数值主要是基于ht的前馈神经网络计算所得。其计算公式为
44、采用均方根误差函数作为损失函数,其计算公式为:
45、
46、其中n为网络学习资源数量。
47、优选的:步骤4中通过bert预训练模型和textcnn模型对评论数据进行处理,得到网络学习资源评价维度分类的方法,包括以下步骤:
48、步骤41:对评论数据进行处理,通过bert预训练模型,将评论数据编码为对应的词向量e1。
49、步骤42:将评论数据词向量e1输入门控循环神经网络gru,以捕捉评论数据中的上下级信息,其计算公式为e2=gru(e1)。
50、步骤43:将gru模型输出向量e2输入全连接神经网络进行特征表示,以使得输出特征维度与textcnn模块输出特征维度匹配。其计算公式(4-2)为y1=weye2+bey。
51、步骤44:对评论数据进行处理,通过jieba分词和预训练bert模型对评论数据进行编码,编码后特征矩阵为e3。
52、步骤45:将特征矩阵e3输入到textcnn网络结构中,以获得较好的文本分类效果。其计算公式为e4=textcnn(e3)。
53、步骤46:将textcnn输出的特征e4进行全连接神经网络计算,以使得输出特征维度与gru模块输出特征维度匹配,其计算公式为y2=w′eye4+b′ey。
54、步骤47:进行多标签文本预测,预测向量
55、步骤48:将预测标签与真实标签yi进行损失函数计算,通过反向传播算法对参数进行求解优化。损失函数公式为
56、优选的:步骤5中通过lstm transformer网络生成网络学习资源质量分析报告的方法,包括以下步骤:
57、步骤51:首先以设置评论数据选取的时间节点,并使用预训练模型对评论数据进行词向量嵌入,该向量表示为er。
58、步骤52:将er输入多层lstm结构中,以捕捉不同评论中的时间信息,并提高单纯使用transformer模型的信息表示能力,输出新的特征表示el。
59、步骤53:将er输入transformer编码层,以捕捉不同词语之间的位置信息,输出新的特征表示et。
60、步骤54:将el和er特征进行融合,通过transformer编码层输出新的特征表示e′t,通过transformer编码层再次深度提取评论中所蕴含的信息。
61、步骤55:将e′t输入transformer解码层,并将评价维度指标词作为最终输出的引导。经过transformer解码层提取大量评论数据中的关键信息,最终从每个评价维度生成一句在该评价维度的整体性评语。
62、一种基于多模态数据的网络学习资源质量评估系统,采用上述基于多模态数据的网络学习资源质量评估方法,包括网络学习资源质量核心要素项特征提取模块、网络学习资源语义特征表示模块、学习资源质量预测评分模块、网络学习资源评价维度分类模块、网络学习资源质量分析报告生成模块,其中:
63、所述网络学习资源质量核心要素项特征提取模块用于采用学习资源信息门控循环单元对网络学习资源质量核心要素项特征进行提取,得到网络学习资源质量核心要素项特征。
64、所述网络学习资源语义特征表示模块用于采用三级transformer动态注意力网络对网络学习资源进行评估得到网络学习资源语义特征表示。
65、所述学习资源质量预测评分模块用于采用循环信息差神经网络ridnn对得到的网络学习资源质量核心要素项特征和网络学习资源语义特征表示进行网络学习资源质量评分预测,得到学习资源质量预测评分。
66、所述网络学习资源评价维度分类模块用于通过bert预训练模型和textcnn模型对评论数据进行处理,得到网络学习资源评价维度分类。
67、所述网络学习资源质量分析报告生成模块用于根据得到的网络学习资源质量核心要素项特征、网络学习资源语义特征表示、学习资源质量预测评分以及网络学习资源评价维度分类通过lstm transformer网络生成网络学习资源质量分析报告。
68、本发明相比现有技术,具有以下有益效果:
69、(1)本发明综合了用户协同创作时产生的编辑行为数据和网络学习资源分享时产生的用户交互行为数据特征,可以实现有效地捕获不同版本之间网络学习资源外显数据信息,具有较高的资源质量评分预测的准确性。
70、(2)本发明从网络学习资源相关的评论数据出发,以网络学习资源质量评价指标体系为分类参考,设计了bert预训练模型+textcnn的算法模型对评论数据信息进行有效的提取,较之常规的文本语义提取技术有较好的效果。
71、(3)本发明提出lstm+transformer的算法模型,该算法综合考虑了评论数据的时间信息和评价维度信息,可生成网络学习资源质量评估文本,实现有效地帮助学习资源建设者过滤无用信息,达到动态调整优化学习资源的目的。
- 还没有人留言评论。精彩留言会获得点赞!