一种基于深度学习的视频监控中行人目标检测方法及装置与流程
本发明涉及目标检测,尤其涉及一种基于深度学习的视频监控中行人目标检测方法及装置。
背景技术:
1、由于客滚船的特殊工作环境和复杂的海上天气条件,客滚船通常承载大量乘客和货物,需要在船舱、甲板和货仓等多个区域进行人员检测和搜索。同时,海上天气条件可能会对检测和搜索工作带来不利影响,例如大浪、风暴、能见度差等,深度学习中自我学习的特征可以更好地描述检测目标的特性,避免了复杂的特征提取和数据建模过程,行人检测是使用计算机视觉等方法判断图像中是否存在行人并给出在图像中的精准位置。
2、目前,可以通过深度学习的图像处理技术对客滚船上的视频监控画面进行处理和分析,提取出人体特征,并识别人体姿态和行为,例如,可以通过背景建模、运动检测、轮廓检测等技术来检测客滚船上的人员。
3、例如公开号为:cn114967731a公开的一种基于无人机的野外人员自动搜寻方法,包括:无人机接收手持终端设备发送来的航线飞行指令,在搜寻区域进行航线飞行;无人机在航线飞行过程中通过摄像头获取搜寻区域的红外图像,对红外图像进行图像处理,通过热成像阈值分析和被困人员运动分析,识别所述图像中是否存在人员的结果;根据图像识别结果控制无人机飞行姿态对人员进行跟踪抓拍,并获取人员的位置信息、环境信息并发送到手持终端设和云服务器。
4、例如公开号为:cn111126102a公开的人员搜索方法、装置及图像处理设备,包括:对参考图像进行人物检测,确定待查找人员,获取所述待查找人员的属性信息;对至少一个视频监控图像进行人物检测,确定所有候选人员,获取所有候选人员的属性信息;根据所述待查找人员的属性信息和每个候选人员的属性信息计算每个候选人员的匹配分数,按照所述匹配分数从大到小的顺序选择预定数量的候选人员;计算所述待查找人员与每个选择的候选人员的相似度,将所述选择的候选人员中与所述待查找人员的相似度最高的候选人员作为所述待查找人员。
5、但本技术发明人在实现本技术实施例中发明技术方案的过程中,发现上述技术至少存在如下技术问题:
6、现有技术中,当客滚船遇见恶劣天气或危险时,行人都处在客滚船各处,难以查找或聚集,且船上部分装置可能会发生摇晃,存在识别行人目标时出现误判的问题。
技术实现思路
1、本技术实施例通过提供一种基于深度学习的视频监控中行人目标检测方法及装置,解决了现有技术中,存在识别行人目标时出现误判的问题,实现了更精准识别行人目标。
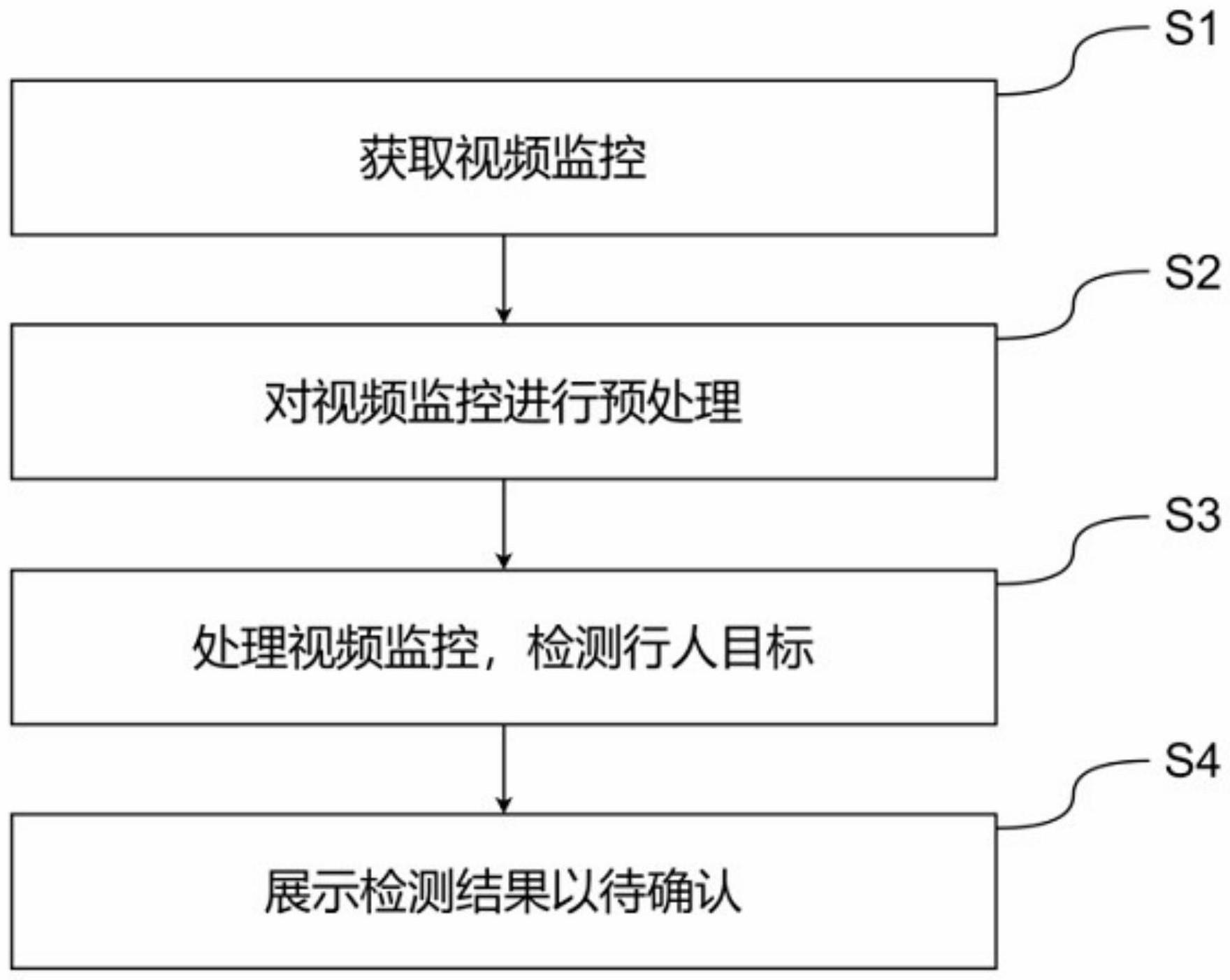
2、本技术实施例提供了一种基于深度学习的视频监控中行人目标检测方法,包括以下步骤:s1,获取视频监控:通过在红外监控器获取客滚船上各个区域的实时热成像视频,并将实时热成像视频上传到检测平台;s2,对视频监控进行预处理:通过检测平台对实时热成像视频进行预处理并从中抽取视频帧;s3,处理视频监控,检测行人目标:在检测平台对比前后抽取的两个视频帧,若前后两帧完全相同,则将前一帧丢弃,并将后一帧存储继续与下一个抽取的视频帧进行对比,若前后两帧中出现差异,则将两帧存储,通过深度学习在热成像视频帧中找出类人姿态的区域;s4,展示检测结果以待确认:将类人姿态的热成像区域在检测平台展示,供工作人员确认热成像视频中检测到行人目标,从而完成行人目标检测。
3、进一步的,所述s1中的将实时热成像视频上传到检测平台指将实时热成像视频及热成像视频对应的红外监控器位置、视频帧时间戳和热辐值一起打包发送至云平台。
4、进一步的,所述s2中的对实时热成像视频进行预处理指将视频格式统一、视频采样、视频裁剪和视频去噪,便于后续对视频进行处理。
5、进一步的,所述s2中抽取视频帧具体指每间隔一段时间间隔抽取一个视频帧,其中一段时间间隔包括一个数值和多个数值,避免抽取视频帧的频率与移动物体的移动频率相同导致前后帧内容相同而被丢弃。
6、进一步的,所述s2中的检测平台包括预处理模块、对比模块、识别模块和展示模块;所述预处理模块用于将热成像视频进行预处理,并每隔一段时间间隔从热成像视频中抽取视频帧;所述对比模块用于将抽取的后一个视频帧与前一个视频帧对比,若完全无变化则删除前一个视频帧保留后一个视频帧,在将保留的视频帧与之后再次抽取的视频帧进行对比,若有变化则保存对比的前后两个视频帧,并将两个视频帧组合输入到识别模块;所述识别模块用于将对比模块输入的两个视频帧通过深度学习识别算法进行识别检测,得出其中包括类人姿态的区域;所述展示模块用于将包含类人姿态区域的视频帧展示给工作人员,由工作人员确认包含类人姿态区域的视频帧中检测到的行人目标。
7、进一步的,所述对比模块中保留的视频帧最后需要重新按照时间戳顺序进行合并,保存为不包含丢弃帧且画面不连续的视频。
8、进一步的,所述s3中通过深度学习在热成像视频帧中找出类人姿态的区域的具体指:步骤1,将热成像视频帧输入识别模型中进行目标检测得到类人姿态区域的坐标和置信度,即:{(x1,p1),(x2,p2),...,(xm,pm)}=f(x),其中x表示新的热成像视频帧,m表示检测出的类人姿态区域的数量,(xi,pi)表示第i个检测框的位置和置信度,f(x)表示模型对输入视频帧x进行目标检测的输出;步骤2,对目标检测结果进行后处理,以提高检测精度和效率;步骤3,将检测出的类人姿态区域进行展示,并在图像上进行增强处理,便于工作人员进一步检查和确认。
9、进一步的,所述识别模型的获得方法具体为:步骤1,数据收集和标注:首先收集一定数量的热成像视频帧,并手动标注出其中的类人姿态区域,以作为训练数据集;步骤2,模型选择:选择合适的深度学习目标检测模型进行训练和推断;步骤3,数据预处理:对收集的热成像视频帧进行预处理,以符合目标检测模型的输入要求;步骤4,模型训练:使用标注的热成像视频帧进行模型训练,以使其学会自动识别类人姿态区域。
10、进一步的,所述步骤4中使其学会自动识别类人姿态区域指最小化目标函数,过程中使用的公式为:
11、
12、其中,θ表示模型参数,l表示目标检测的损失函数,λ表示正则化系数,l(f(xi;θ),yi)表示模型预测的类人姿态区域和真实标注之间的差异,λ‖θ‖2表示对模型参数进行正则化。
13、本技术实施例提供了一种基于深度学习的视频监控中行人目标检测装置,包括:获取模块、预处理模块、处理识别模块和输出模块;所述获取模块用于获取视频监控:通过在红外监控器获取客滚船上各个区域的实时热成像视频,并将实时热成像视频上传到检测平台;所述预处理模块用于对视频监控进行预处理:通过检测平台对实时热成像视频进行预处理并从中抽取视频帧;所述处理识别模块用于处理视频监控,检测行人目标:在检测平台对比前后抽取的两个视频帧,若前后两帧完全相同,则将前一帧丢弃,并将后一帧存储继续与下一个抽取的视频帧进行对比,若前后两帧中出现差异,则将两帧存储,通过深度学习在热成像视频帧中找出类人姿态的区域;所述输出模块用于展示检测结果以待确认:将类人姿态的热成像区域在检测平台展示,供工作人员确认热成像视频中检测到行人目标,从而完成行人目标检测。
14、本技术实施例中提供的一个或多个技术方案,至少具有如下技术效果或优点:
15、1、由于通过抽取热成像视频帧并对连续的两个视频帧对比,再通过深度学习的目标检测模型进行识别,从而避免船内部分装置晃动导致的误识别,进而实现了在恶劣环境下能够更加精准识别出行人目标,有效解决了现有技术中,存在识别行人目标时出现误判的问题。
16、2、由于通过每间隔一段时间从实时热成像视频中抽取一个视频帧,从而前后连续两个视频帧时间的时间间隔未必相同,进而实现了避免抽取视频帧的频率与物体移动的频率相同导致被当作重复视频帧被误丢弃。
17、3、由于通过深度学习在热成像视频帧中找出类人姿态的区域,从而得到类人姿态区域的坐标和置信度,并对得出的目标检测结果进行后处理和图像增强,进而提高了检测类人姿态热成像区域的精度和效率,且更便于工作人员进一步确认。
- 还没有人留言评论。精彩留言会获得点赞!