一种结合自编码器的谱聚类算法、装置、设备及存储介质
本发明涉及算机技术的无监督学习,尤其涉及一种结合自编码器的谱聚类算法、装置、设备及存储介质。
背景技术:
1、谱聚类是现有比较常见的一种基于谱图理论的聚类算法。谱聚类算法的流程是首先通过计算数据之间的相似度得到相似矩阵和拉普拉斯矩阵,再对拉普拉斯矩阵进行特征分解得出原始数据所对应的特征,最后对得出的特征进行聚类,得到最后的聚类结果。谱聚类算法相对于传统的k-means算法具有对样本形状敏感度低、收敛于全局最优解以及对高维数据的支持较好等优点。然而,由于要对拉普拉斯矩阵进行特征分解,此操作的时间复杂度为o(n3),在面对海量数据的时候,该操作耗费的时间成本将大大增加。
2、自编码器是一种在无监督学习中使用的神经网络,其将以输入数据作为标签,对输入数据进行表征学习。自编码器常被应用于进行数据的降维以及异常值的检测。
技术实现思路
1、本发明提供了一种结合自编码器的谱聚类算法、装置、设备及存储介质,结合自编码器对现有的谱聚类算法进行改进,解决了现有谱聚类算法对拉普拉斯矩阵进行特征分解的操作时间复杂度高的技术问题。
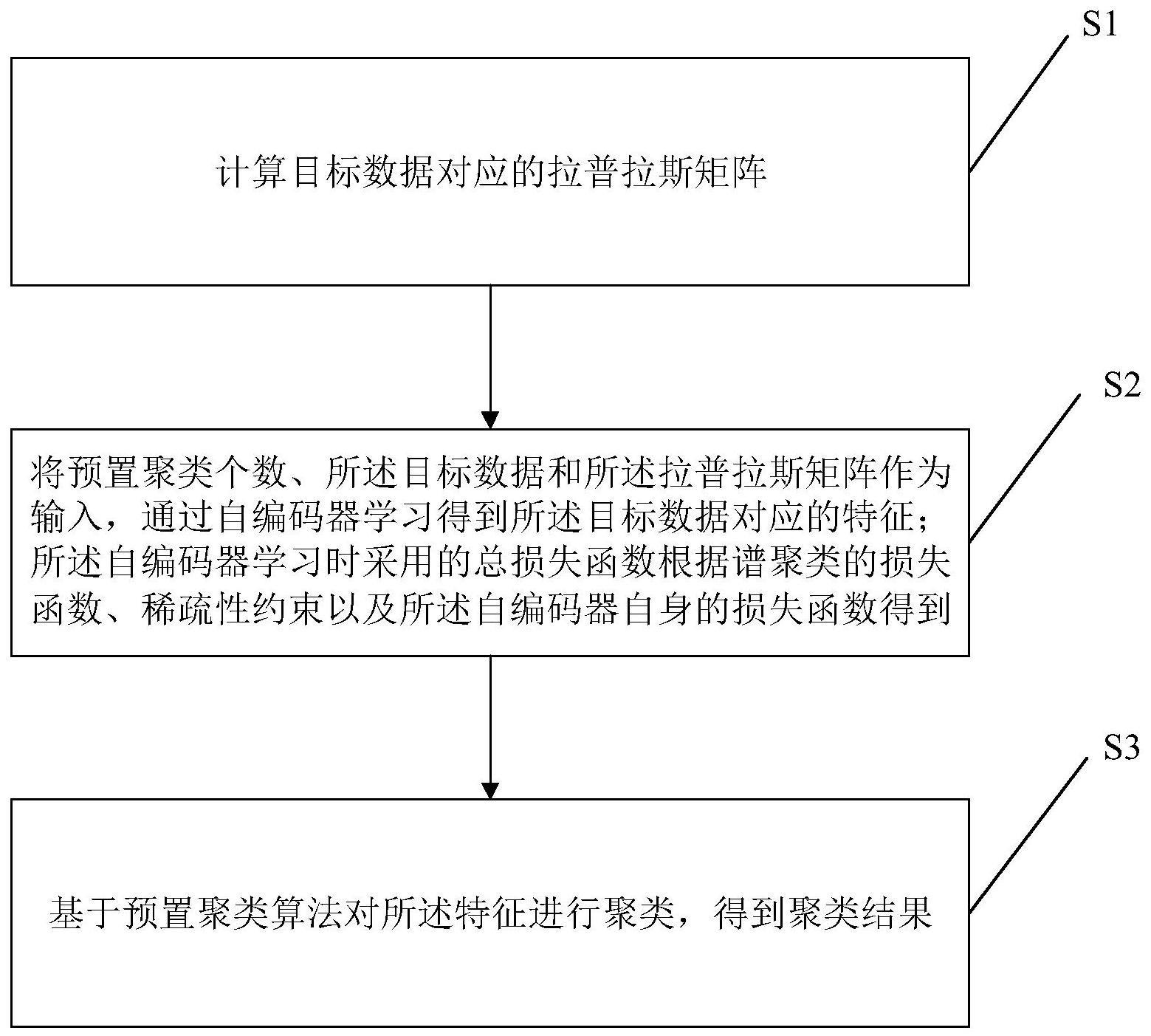
2、本发明第一方面提供一种结合自编码器的谱聚类算法,包括:
3、计算目标数据对应的拉普拉斯矩阵;
4、将预置聚类个数、所述目标数据和所述拉普拉斯矩阵作为输入,通过自编码器学习得到所述目标数据对应的特征;所述自编码器学习时采用的总损失函数根据谱聚类的损失函数、稀疏性约束以及所述自编码器自身的损失函数得到;
5、基于预置聚类算法对所述特征进行聚类,得到聚类结果。
6、根据本发明第一方面的一种能够实现的方式,所述总损失函数为:
7、loss=lr+αls+βle
8、式中,loss表示所述自编码器学习时采用的总损失函数,lr表示谱聚类损失,l表示稀疏性约束,α和β均为预置的调优参数,ls表示自编码器损失。
9、根据本发明第一方面的一种能够实现的方式,所述谱聚类的损失函数为:
10、ls=tr(ftlf)
11、式中,tr表示,f表示所述目标数据对应的特征,l表示所述拉普拉斯矩阵,ft为f的转置,tr(ftlf)表示矩阵ftlf的迹。
12、根据本发明第一方面的一种能够实现的方式,所述稀疏性约束为:
13、
14、式中,n为所述目标数据的数量,k为所述预置聚类个数,δ(·)为softmax函数,fij为所述目标数据中第i个数据点与第j个聚类的相似度。
15、根据本发明第一方面的一种能够实现的方式,所述自编码器自身的损失函数为:
16、
17、式中,n为所述目标数据的数量,gij表示以第i个数据点作为输入时编码器第j层的输出,xij表示以第i个数据点作为输入时解码器第j层的输出,n为编码器和解码器的层数。
18、根据本发明第一方面的一种能够实现的方式,所述基于预置聚类算法对所述特征进行聚类,得到聚类结果,包括:
19、基于k-means聚类算法对所述特征进行聚类,得到聚类结果。
20、根据本发明第一方面的一种能够实现的方式,所述算法还包括:
21、在计算目标数据对应的拉普拉斯矩阵之前,对输入的原始数据进行预处理以得到所述目标数据;所述预处理包括异常值清理和数据归一化处理。
22、本发明第二方面提供一种结合自编码器的谱聚类装置,包括:
23、计算模块,用于计算目标数据对应的拉普拉斯矩阵;
24、特征学习模块,用于将预置聚类个数、所述目标数据和所述拉普拉斯矩阵作为输入,通过自编码器学习得到所述目标数据对应的特征;所述自编码器学习时采用的总损失函数根据谱聚类的损失函数、稀疏性约束以及所述自编码器自身的损失函数得到;
25、聚类模块,用于基于预置聚类算法对所述特征进行聚类,得到聚类结果。根据本发明第二方面的一种能够实现的方式,所述总损失函数为:
26、loss=lr+αls+βle
27、式中,loss表示所述自编码器学习时采用的总损失函数,lr表示谱聚类损失,l表示稀疏性约束,α和β均为预置的调优参数,ls表示自编码器损失。
28、根据本发明第二方面的一种能够实现的方式,所述谱聚类的损失函数为:
29、ls=tr(ftlf)
30、式中,tr表示,f表示所述目标数据对应的特征,l表示所述拉普拉斯矩阵,ft为f的转置,tr(ftlf)表示矩阵ftlf的迹。
31、根据本发明第二方面的一种能够实现的方式,所述稀疏性约束为:
32、
33、式中,n为所述目标数据的数量,k为所述预置聚类个数,δ(·)为softmax函数,fij为所述目标数据中第i个数据点与第j个聚类的相似度。
34、根据本发明第二方面的一种能够实现的方式,所述自编码器自身的损失函数为:
35、
36、式中,n为所述目标数据的数量,gij表示以第i个数据点作为输入时编码器第j层的输出,xij表示以第i个数据点作为输入时解码器第j层的输出,n为编码器和解码器的层数。
37、根据本发明第二方面的一种能够实现的方式,所述聚类模块包括:
38、聚类单元,用于基于k-means聚类装置对所述特征进行聚类,得到聚类结果。
39、根据本发明第二方面的一种能够实现的方式,所述装置还包括:
40、预处理模块,用于在计算目标数据对应的拉普拉斯矩阵之前,对输入的原始数据进行预处理以得到所述目标数据;所述预处理包括异常值清理和数据归一化处理。
41、本发明第三方面提供了一种结合自编码器的谱聚类设备,包括:
42、存储器,用于存储指令;其中,所述指令用于实现如上任意一项能够实现的方式所述的结合自编码器的谱聚类算法;
43、处理器,用于执行所述存储器中的指令。
44、本发明第四方面一种计算机可读存储介质,所述计算机可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现如上任意一项能够实现的方式所述的结合自编码器的谱聚类算法。
45、从以上技术方案可以看出,本发明具有以下优点:
46、本发明的算法包括:计算目标数据对应的拉普拉斯矩阵;将预置聚类个数、所述目标数据和所述拉普拉斯矩阵作为输入,通过自编码器学习得到所述目标数据对应的特征;所述自编码器学习时采用的总损失函数根据谱聚类的损失函数、稀疏性约束以及所述自编码器自身的损失函数得到;基于预置聚类算法对所述特征进行聚类,得到聚类结果;本发明使用自编码器对现有谱聚类算法中的特征分解步骤进行替代,损失函数除了自编码器自身的损失函数外,再额外添加谱聚类的损失函数和稀疏性约束,使得自编码器能够在进行特征学习的同时兼顾到原有谱聚类算法的目标优化,能够降低传统谱聚类算法在面对海量数据时所需的时间成本,解决现有谱聚类算法对拉普拉斯矩阵进行特征分解的操作时间复杂度高的技术问题。
- 还没有人留言评论。精彩留言会获得点赞!