一种在虚拟空间中实现AI交互的方法与流程
本发明涉及虚拟现实,具体的涉及一种在虚拟空间中实现ai交互的方法。
背景技术:
1、虚拟现实技术(英文名称:virtual reality,缩写为vr)囊括计算机、电子信息、仿真技术,其基本实现方式是以计算机技术为主,利用并综合三维图形技术、多媒体技术、仿真技术、显示技术、伺服技术等多种高科技的最新发展成果,借助计算机等设备产生一个逼真的三维视觉、触觉、嗅觉等多种感官体验的虚拟世界,从而使处于虚拟世界中的人产生一种身临其境的感觉。
2、近年来,随着计算机图形处理能力与计算能力的不断提高,虚拟现实技术应用逐渐扩大。虚拟现实技术以其通过模拟真实空间的特点,在游戏、设计、教育等领域得到广泛应用。同时,人工智能技术也得到长足的发展,各行各业都在努力将人工智能技术应用到实际生产中。现有技术中,在虚拟空间中实现ai交互的方式较少。传统的键盘、鼠标输入方式,限制了用户与智能服务之间的交互。本发明通过将虚拟现实技术与人工智能技术相结合,解决了传统虚拟空间互动单一、信息获取效率低下等问题,提供了更加智能化、自然化的虚拟空间交互方式。
技术实现思路
1、本专利提供了一种在虚拟空间中实现ai交互的方法,提供了更加便捷、快速和高效的人工智能服务。
2、本专利提供了一种在虚拟空间中实现ai交互的方法,包括以下组件:
3、用于构建和显示虚拟场景的计算机图形组件;
4、用于跟踪用户动作和姿态信息的传感器设备;
5、用于调用api接口向远端ai服务器提交用户请求并获取反馈信息的ai小助手;
6、存储用户数据的云端数据库。
7、本专利的虚拟场景、虚拟角色人物模型、ai小助手由计算机图形引擎实时生成的计算机图像组件。该组件具有位置数据特征与动画数据特征,并具有变形模块能够自动或者手动切换展示形态。所述ai小助手与虚拟角色之间采用“绑定”机制建立紧密的关联关系,并通过云端数据绑定成为虚拟角色的一部分。
8、在本专利中,所述的ai小助手是一种呈漂浮形态的计算机图形数据组件,外观为精灵或者机器人的轮廓形状。该组件包括语音识别组件、ai人工智能引擎接口api、语音合成组件、音频设备和文本控件等子组件。通过云端的服务器,以调用api接口的方式连接于远程ai人工智能服务器,提供人工智能服务。
9、在使用本专利中的方法时,用户首先被带入到虚拟现实场景中。用户可以通过传感器设备进行姿态和动作的跟踪,并与ai小助手进行交互,例如询问问题等。ai小助手将用户的输入发送至远端ai服务器,获取反馈信息,并根据反馈信息组件
10、具体而言,本发明提出了一个完整的虚拟现实(vr)系统,其中包括三个主要的计算机图形组件:虚拟场景组件、虚拟角色人物模型组件和ai小助手组件。这些组件由计算机图形引擎调用计算机图形硬件显示在用户的计算机显示设备中。
11、虚拟场景组件提供虚拟环境的显示,由计算机图形组件调用渲染方法显示在计算机显示设备中的虚拟场景,用于指示当前虚拟空间的环境特征。此外,该组件也提供了场景中的物体、图片等元素,丰富了用户的交互体验。
12、虚拟角色人物模型组件则是根据用户的需求,在云端数据库中自定义的虚拟角色数据驱动的实体。该组件包括存储在云端数据库中的资料,通过计算机视觉技术实现控制角色的运动轨迹。同时,该组件也可用于代替用户,在虚拟空间中与ai小助手进行交互,例如通过语音、手势等方式向ai小助手提交请求,并获取反馈信息。
13、最后,ai小助手组件是一个连接用户、远端ai服务器和虚拟环境的中介。该组件根据用户的需求调用api接口向远端ai服务器提交请求并获取反馈信息,然后将反馈信息与虚拟空间进行图形交互,使用户可以在虚拟环境中直观地体验ai的反馈。
14、该方法具体包括:
15、a) 提供虚拟场景,计算机图形组件调用渲染方法显示在显示设备中。
16、b) 提供存储在云端数据库中的虚拟角色人物模型,表示用户在虚拟场景中的身份。
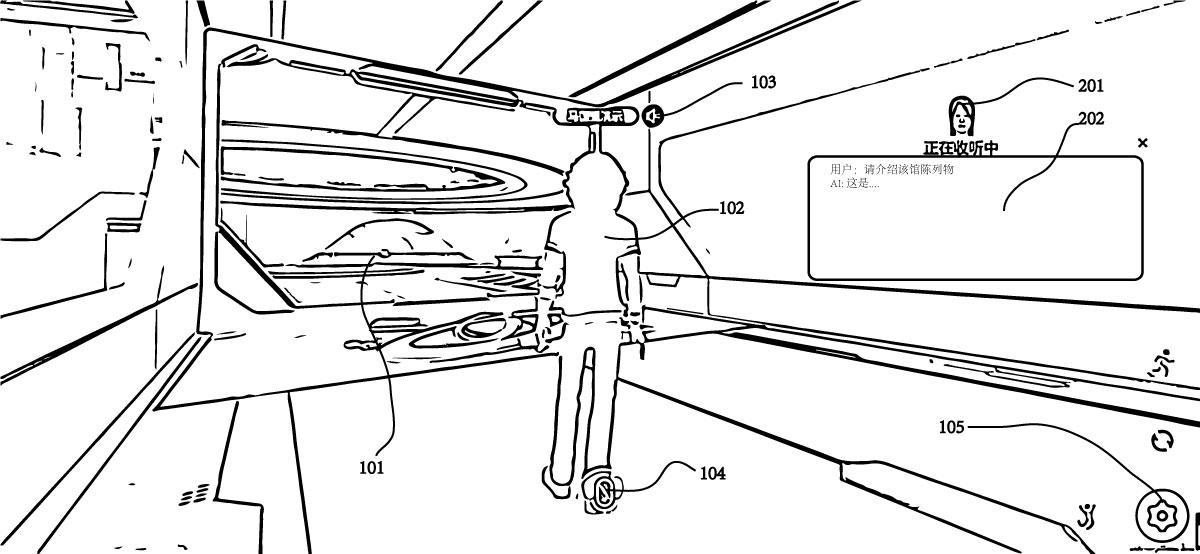
17、c) 提供跟随虚拟角色移动的ai小助手,计算机图形组件和动画方法实现,显示在虚拟场景中。
18、三个组件由计算机图形引擎调用硬件显示在用户设备中。
19、ai小助手通过调用api接口连接ai服务器。它具有变形模块,可根据场景和输入自动或手动切换形态,图形组件渲染相应互动效果,与场景模型互动。
20、ai小助手通过云端数据绑定成为虚拟角色的一部分,通过数据模型关联关系,图形引擎控制其跟随虚拟角色移动。
21、虚拟场景、虚拟角色人物模型和ai小助手由计算机图形引擎实时生成。虚拟角色人物模型和ai小助手在虚拟场景中具有位置和动画数据特征。
22、ai小助手在用户设备视窗中。当用户转动视窗,ai小助手执行动画模型,其眼睛图形数据望向虚拟人物。
23、ai小助手连接用户设备录音设备,接收声音环境信息。连接唤醒词检测模块。当检测到匹配语音特征,ai小助手执行动画模型的图形变换方法。
24、ai小助手通过以下步骤实现交互:
25、a) 语音识别api组件解析用户语音,转换为文本。
26、b) api组件将文本发送ai服务器,得到应答。
27、c) 如果选择语音交互,语音合成程序将应答转换为语音,音频设备输出给用户。
28、d) 如果选择文本交互,直接在虚拟场景文本控件显示答案。
29、语音识别组件、ai服务器、语音合成组件、音频设备和文本呈现组件通过接口通信,实现处理输入和呈现答案。
30、ai小助手具有形态方法组件,交互后触发形态变换方法,形态为不同3d模型,由图形引擎调用实现。例如,在图书馆变为讲解员形象,与场景模型互动;导游形象,向多人讲述景点模型历史。
31、ai小助手和虚拟角色采用“绑定”机制建立关联,实现ai小助手跟随虚拟角色移动。该机制利用虚拟场景位置信息,在虚拟空间向量计算和匹配,实现ai小助手和虚拟角色实时绑定,确保ai小助手由图形组件渲染显示在显示设备中,跟随虚拟角色。
32、当用户使用非英语与ai小助手交流,语音识别组件将语音转换为文字,语言翻译组件翻译,语音合成技术以用户可理解语言呈现给用户。
33、该方法允许用户通过姿势、手势、眼神、语音等自然方式与计算机组件交互。
34、展示给用户的虚拟场景包括虚拟人物、环境、物品、图片、视频、文本等元素。
35、传感器设备包括摄像头、麦克风、陀螺仪等物理传感器。
36、关联连接关系通过向量计算和匹配组件实现,利用虚拟场景中的位置信息组件作为依据,实现ai小助手和虚拟角色之间的实时绑定,确保ai小助手能够随时跟随虚拟角色进行移动并提供服务。
37、与现有技术相比,本发明的有益效果是:通过将ai技术引入虚拟现实领域,提供了一种更加智能化、自然化的虚拟空间交互方式。本发明实现了用户与虚拟场景中的角色和物品之间的真正互动,使虚拟场景中的操作更加自然、流畅。本发明的实现还可以有效减少繁琐的键盘输入和鼠标点击,提高信息获取效率。
- 还没有人留言评论。精彩留言会获得点赞!