一种计算机大数据存储系统及方法与流程
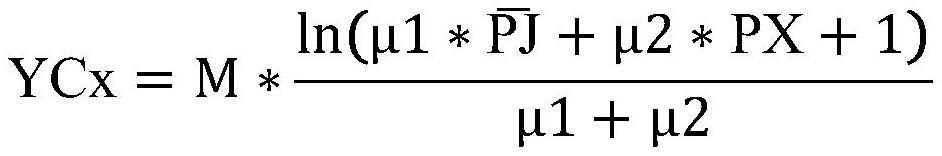
本发明涉及数据存储,具体涉及一种计算机大数据存储系统及方法。
背景技术:
1、计算机大数据(big data)指的是规模巨大、复杂多样、难以通过传统方法进行处理和管理的数据集合。这些数据通常具有“3v”特点,即数据量大(volume)、数据类型多样(variety)和数据处理速度快(velocity),因此需要采用先进的技术和方法对其进行存储、管理、分析和应用。计算机大数据的应用非常广泛,包括商业、科学、政府、医疗、教育等领域,可以用于市场营销、风险管理、产品研发、科学研究、政策制定、医疗诊断、教育教学等方面。常见的计算机大数据技术包括分布式存储、分布式计算、数据挖掘、机器学习、人工智能等。
2、现有技术存在以下不足:计算机数据是个非常庞大的数据库,现阶段对计算机录入数据或者计算机内部数据存储时大多是根据数据的结构形式选择对应地址直接进行存储,由于计算机大数据存储系统无法对存储的异常字句信息进行分析筛除,当存储的字句发生异常时,在对数据进行分析时,由于需要对异常的字句数据进行分析,不仅会降低数据分析的效率,且还会降低数据分析的准确性;其次,当存储的异常字句量发生异常增多时,无法及时获知,待发现大量的字句异常时,才能知晓,存在严重的滞后性。
3、在所述背景技术部分公开的上述信息仅用于加强对本公开的背景的理解,因此它可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现思路
1、本发明的目的是提供一种计算机大数据存储系统及方法,本发明通过对存储数据的字句文字进行分析,将字句文字字节系数与字句文字噪声系数建立数据分析模型,生成高异常风险字句标记和低异常风险字句标记,将正常的数据与异常的数据进行分类存储,在对数据进行分析时,只对正常的数据进行分析,不仅可提高数据分析的效率,且还可提高数据分析的准确性,以解决上述背景技术中的问题。
2、为了实现上述目的,本发明提供如下技术方案:一种计算机大数据存储系统,包括数据采集模块、分析模型建立模块、比对模块、第一存储模块、综合分析模块以及第二存储模块;
3、数据采集模块,采集需要存储的字句信息,获取字句信息的多项参数,多项参数包括字句文字字节系数与字句文字噪声系数,采集后,将字句文字字节系数与字句文字噪声系数传递至分析模型建立模块;
4、分析模型建立模块,将字句文字字节系数与字句文字噪声系数建立数据分析模型,生成字句评价系数,并将字句评价系数传递至比对模块;
5、比对模块,将生成的字句评价系数与阈值进行比对,生成高异常风险字句标记和低异常风险字句标记,将带有高异常风险字句标记的字句传递至第一存储模块和综合分析模块,并将带有低异常风险字句标记的字句传递至第二存储模块;
6、第一存储模块,对带有高异常风险字句标记的字句进行存储;
7、综合分析模块,获取带有高异常风险字句标记的字段中所有字句的字句评价系数,计算所有字句评价系数的平均值和离散程度值,将平均值和离散程度值建立数据分析模型,生成异常指数,将异常指数与阈值进行比对,生成高异常风险字段标记和低异常风险字段标记;
8、第二存储模块,对带有低异常风险字句标记的字句进行存储。
9、优选的,采集到字句文字字节系数与字句文字噪声系数后,将字句文字字节系数与字句文字噪声系数分别标定为zjxi和zsxi;
10、字句文字字节系数获取的逻辑如下:
11、获取字句文字中无效字节的数量、缺失字节的数量、格式错误字节的数量、意外字节的数量以及字节的总量,将无效字节的数量、缺失字节的数量、格式错误字节的数量、意外字节的数量以及字节的总量分别标定为m1、m2、m3、m4、m5,通过公式计算出字句文字字节系数zjxi,计算的表达式为:
12、
13、式中,β1、β2、β3、β4分别为无效字节的数量、缺失字节的数量、格式错误字节的数量、意外字节的数量的权重系数,且β1、β2、β3、β4均大于0。
14、优选的,获取字句评价系数pji后,将字句评价系数pji与阈值ss1进行比对,若字句评价系数pji小于阈值ss1,生成低异常风险字句标记,若字句评价系数pji大于等于阈值ss1,生成高异常风险字句标记。
15、优选的,将带有高异常风险字句标记的字段中所有字句的字句评价系数建立数据集合,将数据集合标定为q,则q={pji}=pj1、pj2、pj3、…、pjv},i为字段中字句的数量,i=2、3、4、...、v,求出数据集合中字句评价系数的平均值和离散程度值,将平均值和离散程度值分别标定为和px,则:则:
16、优选的,获取数据集合中字句评价系数的平均值和离散程度值px后,建立数据分析模型,生成异常指数ycx,依据的公式为:
17、
18、;式中,m为误差修正因子,取值为1.9854,μ1、μ2分别为平均值和离散程度值的预设比例系数,且μ1>μ2>0。
19、优选的,获取异常指数ycx后,将异常指数ycx与阈值ss2进行比对,若异常指数ycx小于阈值ss1,生成低异常风险字段标记,反之则生成高异常风险字段标记,当生成高异常风险字段标记时,通过综合分析模块内设置的预警模块发出预警提示。
20、一种计算机大数据存储方法,包括以下步骤:
21、采集需要存储的字句信息,获取字句信息的多项参数,多项参数包括字句文字字节系数与字句文字噪声系数;
22、将字句文字字节系数与字句文字噪声系数建立数据分析模型,生成字句评价系数;
23、将生成的字句评价系数与阈值进行比对,生成高异常风险字句标记和低异常风险字句标记;
24、对带有高异常风险字句标记的字句和带有低异常风险字句标记的字句进行分类存储;
25、获取带有高异常风险字句标记的字段中所有字句的字句评价系数,计算所有字句评价系数的平均值和离散程度值,将平均值和离散程度值建立数据分析模型,生成异常指数,将异常指数与阈值进行比对,生成高异常风险字段标记和低异常风险字段标记。
26、优选的,采集到字句文字字节系数与字句文字噪声系数后,将字句文字字节系数与字句文字噪声系数分别标定为zjxi和zsxi;
27、字句文字字节系数获取的逻辑如下:
28、获取字句文字中无效字节的数量、缺失字节的数量、格式错误字节的数量、意外字节的数量以及字节的总量,将无效字节的数量、缺失字节的数量、格式错误字节的数量、意外字节的数量以及字节的总量分别标定为m1、m2、m3、m4、m5,通过公式计算出字句文字字节系数zjxi,计算的表达式为:
29、
30、式中,β1、β2、β3、β4分别为无效字节的数量、缺失字节的数量、格式错误字节的数量、意外字节的数量的权重系数,且β1、β2、β3、β4均大于0;
31、获取字句评价系数pji后,将字句评价系数pji与阈值ss1进行比对,若字句评价系数pji小于阈值ss1,生成低异常风险字句标记,若字句评价系数pji大于等于阈值ss1,生成高异常风险字句标记。
32、优选的,将带有高异常风险字句标记的字段中所有字句的字句评价系数建立数据集合,将数据集合标定为q,则q={pji}={pj1、pj2、pj3、…、pjv},i为字段中字句的数量,i=2、3、4、...、v,求出数据集合中字句评价系数的平均值和离散程度值,将平均值和离散程度值分别标定为和px,则:则:
33、获取数据集合中字句评价系数的平均值和离散程度值px后,建立数据分析模型,生成异常指数ycx,依据的公式为:
34、
35、;式中,m为误差修正因子,取值为1.9854,μ1、μ2分别为平均值和离散程度值的预设比例系数,且μ1>μ2>0。
36、优选的,获取异常指数ycx后,将异常指数ycx与阈值ss2进行比对,若异常指数ycx小于阈值ss1,生成低异常风险字段标记,反之则生成高异常风险字段标记,当生成高异常风险字段标记时,发出预警提示。
37、在上述技术方案中,本发明提供的技术效果和优点:
38、本发明通过对存储数据的字句文字进行分析,将字句文字字节系数与字句文字噪声系数建立数据分析模型,生成字句评价系数,将生成的字句评价系数与阈值进行比对,生成高异常风险字句标记和低异常风险字句标记,将带有高异常风险字句标记的字句通过第一存储模块进行存储,将带有低异常风险字句标记的字句通过第二存储模块进行存储,可将正常的数据与异常的数据进行分类存储,在对数据进行分析时,只对正常的数据进行分析,不仅可提高数据分析的效率,且还可提高数据分析的准确性;
39、本发明通过获取带有高异常风险字句标记的字段中所有字句的字句评价系数,将带有高异常风险字句标记的字段中所有字句的字句评价系数建立数据集合,计算所有字句评价系数的平均值和离散程度值,将平均值和离散程度值建立数据分析模型,生成异常指数,将异常指数与阈值进行比对,生成高异常风险字段标记和低异常风险字段标记,当字段数据中生成高异常风险字段标记时,通过综合分析模块内设置的预警模块发出预警提示,提示存储人员存储的异常字句量发生异常增多的现象,便于存储人员及时发现问题。
- 还没有人留言评论。精彩留言会获得点赞!