一种基于缺失值填补的虚拟机负载预测方法
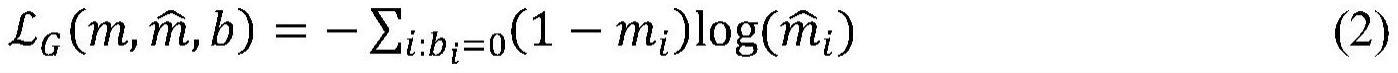
本发明属于云计算,特别涉及一种基于缺失值填补的虚拟机负载预测方法。
背景技术:
1、随着云计算的发展,越来越多的软件系统被作为saas部署到云环境中提供服务。saas层应用(即云应用)通过与用户签订服务水平协议(sla,service level agreement)向用户提供服务。
2、一般情况下,云应用提供商需要租用云资源提供商提供的资源(如虚拟机),部署云应用,并为用户提供满足sla要求的服务。部署在虚拟机(vm,virtual machine)上的云应用,其性能与其所在虚拟机的资源量(如cpu类型及核数、内存容量、网络带宽、系统盘类型及容量等)和负载(如cpu利用率、内存占用率等)密切相关,同一配置下的虚拟机,如果其负载不同,则在其上运行的云应用的性能也不同。而虚拟机负载高低受虚拟机资源量、用户并发访问量等因素的影响。在相同的用户并发访问量下,如果虚拟机资源量大,则可能负载低、性能好;如果虚拟机资源量小,则可能负载高、性能差。
3、云应用提供商总是希望以最小的资源使用成本来租用资源部署云应用,为用户提供满足sla要求的服务。为了以最小资源使用成本来保证云应用的性能,需要将虚拟机的负载限制在某个范围之内,如果超出范围,则需要对虚拟机资源进行动态调整。为尽量满足初始申请或者调整后的虚拟机负载在所限制的范围内,需要建立一个基于虚拟机资源量、用户并发访问量对虚拟机负载进行预测的模型,利用该模型计算在当前并发访问量条件下需要将虚拟机资源量调整到何种程度,因此如何基于虚拟机资源量和用户并发访问量对虚拟机负载进行预测成为虚拟机资源弹性调整的关键问题。
4、基于虚拟机资源量和用户并发访问量的虚拟机负载预测是一个回归问题,其输入为虚拟机的资源量与并发访问量,输出为虚拟机的负载。
技术实现思路
1、针对现有技术存在的不足,本发明提出了一种基于缺失值填补的虚拟机负载预测方法;将虚拟机配置信息与并发量当做已知值,将待预测的虚拟机负载当做缺失值,采用gain(generative adversarial imputation nets,生成对抗插补网络)对缺失值进行填补。
2、一种基于缺失值填补的虚拟机负载预测方法,具体包括以下步骤:
3、步骤1:将虚拟机负载预测问题转化为缺失虚拟机负载值填补问题;
4、所述虚拟机负载预测,是根据虚拟机某时段的并发访问量及资源量来预测该时段虚拟机的负载;其中并发访问量及资源量和负载的指标根据实际应用需求设置;
5、将要进行负载预测的虚拟机某时段的并发访问量及资源量当作已知值,将待预测的虚拟机负载当作缺失值,通过使用缺失值填补方法对虚拟机负载进行填补,实现对虚拟机负载的预测任务,从而将虚拟机负载预测问题转化为缺失虚拟机负载值填补问题;具体为:
6、根据实际应用需求采用并发访问量和n项虚拟机资源量指标预测m项虚拟机负载,将虚拟机负载预测问题转化为缺失虚拟机负载值填补问题的转化方法如下:
7、虚拟机的n项虚拟机资源量指标、虚拟机并发访问量和m项虚拟机负载指标共同组成一个由k项(k=n+1+m)指标描述的虚拟机状态;其中,前n项为虚拟机资源量、第n+1项为并发访问量、后m项为待预测的虚拟机负载;
8、虚拟机在某个时间段的各状态指标的具体值,就形成了一个k维虚拟机状态向量;针对一个待预测负载的虚拟机,基于虚拟机资源量、用户并发访问量对虚拟机负载进行预测,即利用该虚拟机状态向量的前n+1项预测后m项的值;将虚拟机状态向量的前n+1项当作是已知值,后m项当作是缺失值,对缺失值进行填补完成对虚拟机负载的预测工作,从而将虚拟机负载预测问题转换为一个缺失虚拟机负载值填补问题;
9、步骤2:构建基于gain的虚拟机负载预测模型gain-vmlp;
10、所述gain-vmlp,将虚拟机资源量与并发访问量(即虚拟机状态向量的前n+1项)当作已知值,将待预测的虚拟机负载(即虚拟机状态向量的后m项)当做缺失值,将虚拟机负载预测问题转化为缺失虚拟机负载值填补问题,并采用gain对缺失虚拟机负载值进行填补,从而完成对虚拟机负载的预测,由此构建用于虚拟机负载预测的gain-vmlp模型;
11、所述采用gain进行缺失虚拟机负载值填补,具体为:通过生成器生成对缺失虚拟机负载值的拟合数据,然后通过判别器来判断数据是否是真实的来达到对抗目的;
12、所述gain-vmlp模型的输入是带有缺失虚拟机负载值的k维虚拟机状态向量(后m项为待预测的虚拟机负载),输出是带有虚拟机负载预测值的k维虚拟机状态向量(后m项为已经预测出结果的虚拟机负载);
13、所述构建基于gain的虚拟机负载预测模型gain-vmlp,具体过程如下:
14、步骤s1:对输入数据向量进行设计;
15、在虚拟机状态向量中缺失的项用一个特殊值进行标注,所述特殊值不在任何指标的取值范围之内,形成输入数据向量x;针对k维虚拟机状态向量,并发访问量和虚拟机资源量的前n+1项都是已知的,而代表虚拟机负载的后m项是缺失的;
16、步骤s2:对掩码向量进行设计;
17、通过掩码向量对缺失数据位置进行标记;k维向量m=(m1,...,mk),每个分量的取值为0或1,其中1表示x中对应分量的值不缺失,0表示x中对应分量的值不缺失;每个x都对应一个m,m中各分量的值根据x进行设置,当x中的分量xi(i∈[1,k])为0时,对应的m中的分量mi也为0;当x中的分量xi(i∈[1,k])不为0时,对应的m中的分量mi为1,从而形成掩码向量m;
18、步骤s3:对随机噪声向量进行设计;
19、使用随机噪声对缺失数据进行最初的填补;随机生成一个k维随机噪声向量z=(z1,…,zk),其每个分量的取值范围是[0,1],从而形成随机噪声向量z;
20、步骤s4:对提示向量进行设计;
21、所述提示向量强化生成器和判别器的对抗过程,给判别器提示原始数据中部分缺失的信息,让判别器更加关注提示向量提示的部分,同时逼迫生成器去生成更加真实的数据;提示向量h的生成方法如下:
22、步骤s4.1:首先生成随机向量b;k维向量b=(b1,…,bk)的每个分量的取值为0或1;每个分量值的生成方法为:从{1,…,k}之间随机生成一个数p,将b中第p分量的值设为0,其余分量的值都设为1;
23、步骤s4.2:根据b生成提示向量h;k维向量h=(h1,…,hk)的每个分量的取值为0、0.5或1,h的生成方法如式1所示:
24、h=b⊙m+0.5(1-b) (1)
25、其中,⊙表示向量的点乘计算;
26、步骤s5:对生成器g进行设计;
27、所述gain-vmlp中使用生成器用来生成预测数据;生成器的输入为带缺失值的k维输入数据向量x、掩码向量m和随机噪声向量z,经过三层全连接层,输出为带有虚拟机负载预测值的输出数据向量由于生成器不仅预测待预测位置的值,也会预测原始的输入数据的值,所以输出的向量不仅要使预测的值欺骗判别器,也要使原始的输入数据的值输出也接近真实值;因此生成器的两个损失函数如式2和式3所示:
28、
29、
30、其中,m表示掩码向量;b表示随机向量;表示判别器的判别结果,表示对生成器生成的数据是否是缺失数据的概率;x代表输入数据向量;代表生成器生成的数据向量;k表示数据向量x的维数;
31、生成器g的目标是使得两个损失函数的加权和最小化,如式4所示:
32、
33、其中,kg表示生成器g采用梯度下降法进行训练时每批次训练样本的个数,α为超参数;
34、步骤s6:对判别器d进行设计;
35、所述gain-vmlp中使用判别器来判断数据是数据集中真实的数据还是生成器生成的虚假数据,其输入为生成器的输出和提示向量h,通过三层全连接层,输出以概率形式表示的判断结果
36、判别器的损失函数如式5所示:
37、
38、其中,m表示掩码向量;b表示随机向量;表示判别器的判别结果,表示对生成器生成的数据是否是缺失数据的概率;
39、针对式5,期望判别器对预测出来的虚拟机负载的真实性判断的足够准确,所以判别器的训练准则如式6所示:
40、
41、其中,kd表示判别器d采用梯度下降法进行训练时每批次训练样本的个数;
42、步骤s7:对输入数据进行标准化设计;
43、对所述gain-vmlp输入数据的每一维都进行标准化处理,将数据映射到[0,1]区间内,标准化公式如式7所示:
44、
45、步骤3:训练gain-vmlp模型;
46、所述gain-vmlp模型的训练过程如下:
47、步骤3.1:对训练数据集进行处理;所述训练数据集由虚拟机运行或进行基准测试所获得的若干条数据组成,每条数据由n个虚拟机资源量指标值、并发访问量、m个虚拟机负载指标值组成;按照比例随机选取数据集中若干条数据,对虚拟机负载指标值清空,表示缺失值;
48、步骤3.2:生成输入数据向量;按照输入数据的标准化设计,采用式7对数据集中的每条数据进行标准化处理,并将每条数据中负载值为空的项用-1进行标注,从而形成由若干个k维虚拟机状态向量标准化后的输入数据向量所组成的数据集x;
49、步骤3.3:设置批处理大小s;使用小批量梯度下降法对所述gain-vmlp模型进行训练;每批次输入到gain-vmlp中的虚拟机状态向量数将根据批处理大小(batch size)参数s进行控制;
50、步骤3.4:计算掩码向量;按照掩码向量设计方法,对数据集x中的每个数据向量x生成掩码向量m,从而组成数据集x的掩码集m;
51、步骤3.5:进行判别器优化训练:判别器优化训练过程如下:
52、步骤3.5.1:从数据集中x选取s个数据向量并且同时从掩码集m中选取这s个数据向量所对应的掩码向量
53、步骤3.5.2:生成s个独立同分布的随机噪声z;
54、步骤3.5.3:生成s个独立同分布的随机向量b;
55、步骤3.5.4:使用生成器针对s个数据向量生成s个数据向量
56、步骤3.5.5:使用梯度下降法基于式5更新训练判别器d;
57、步骤3.6:进行生成器优化训练;生成器器优化训练过程如下:
58、步骤3.6.1:从数据集中x选取s个数据向量并且同时从掩码集m中选取这s个数据所对应的掩码向量
59、步骤3.6.2:生成s个独立同分布的随机噪声z;
60、步骤3.6.3:生成s个独立同分布的随机向量b;
61、步骤3.6.4:基于式1生成s个提示向量
62、步骤3.6.5:使用梯度下降法基于式4更新训练生成器g;
63、步骤4:使用训练完成的gain-vmlp模型对虚拟机的负载进行预测;
64、根据实际应用需求设置虚拟机资源量指标和虚拟机负载指标,结合给定的并发量,组成虚拟机状态向量,输入到gain-vmlp模型,模型输出结果即为虚拟机负载预测结果,从而实现对虚拟机的负载进行预测。
65、本发明有益技术效果:
66、1.本发明构建基于缺失值填补的虚拟机负载预测方法,探讨预测方法中的模型建立问题,对云计算中虚拟机负载进行预测。根据实验结果以及实际应用需求确定选用的模型与相关参数。
67、2.本发明基于缺失值填补的虚拟机负载预测方法,介绍了该模型的预测过程以及预测算法。经过实验对比分析,本方法在预测精度和稳定性上都取得了很好的效果。
68、3.本发明将虚拟机资源量与并发访问量当作已知值,将待预测的虚拟机负载当作缺失值,从而将虚拟机负载预测问题转化为缺失虚拟机负载值填补问题,进而提出了一种基于缺失值填补的虚拟机负载预测方法,并采用一种缺失值填补算法gain对问题进行求解,可以有效解决云计算中虚拟机负载预测问题,从而为云计算中虚拟机资源的弹性伸缩调整提供有效支持。
- 还没有人留言评论。精彩留言会获得点赞!