一种基于少样本学习的图像处理方法及相关设备
本发明涉及图像处理,尤其涉及一种基于少样本学习的图像处理方法及相关设备。
背景技术:
1、随着元宇宙概念的兴起,为用户创建虚拟形象成为热门话题之一,相比于采用三维重建等方式创建真实感数字替身,动漫形象因其具有炫酷而个性化的特点,更受用户青睐;制作动漫形象的首要任务是进行人脸的动漫化,因为人类感知力对人脸的身份认同十分敏感,更趋近于关注人脸的特征;虽然可以依靠艺术家或建模师通过数位板等工具对人脸进行动漫化,但往往需要很强的专业知识,同时消耗大量的人力资源,并且不同的艺术家设计的风格也不能够保持统一,效率比较低下;因此,对于人脸的动漫化的自动化生成具有很高的应用价值。
2、人脸动漫化,即是人脸图像的动漫风格化,其目标是将用户输入的真实人脸图像转化为动漫风格,同时尽量保持图像中人脸身份不变;早期方法源自著名的神经风格迁移(neural style transfer),然而神经风格迁移最终被证明更适合于笔触纹理丰富的艺术化风格迁移,如油画、水墨画风格等。对于动漫风格,由于其简洁的色彩和夸张的几何形变,风格迁移往往无法获得令人满意的效果;随后,图像翻译(image-to-image translation)相关方法的提出,引发基于深度学习网络(主要是生成对抗网络(gan))提出了一系列专门用于人脸动漫化的工作;然而现有这些方法都需要大量的训练数据(从100+到1000+),这极大的限制了多样性风格的学习和在实际中的应用;如何基于少样本动漫化示例数据,来快速学习风格特征是当前人脸图像动漫化亟待解决的首要问题;然而少样本学习是当前深度学习的一大难点,尤其是对于图像生成问题;目前,基于在大数据下预训练的stylegan(风格生成对抗网络)图像生成模型,首次实现了将预训练好的stylegan图像迁移到由最多10个样本定义的目标域,完成了在少样本下的跨域迁移任务,实现少样本图像生成;方法的核心是在生成对抗网络的域迁移(gan adaptation,后文统一简称为gan域迁移)过程中引入度量学习,通过约束实例之间的相对相似度来保持数据的多样性,以防止少样本数据集上过拟合;使用域迁移后的stylegan模型,结合gan(生成对抗网络)逆映射(gan inversion)技术,便可实现少样本数据集下的人脸风格化;该方法虽然获得了一定的成功,但其动漫化图像与输入图像存在较大的身份偏差,同时通过gan逆映射技术得到的图像颜色也存在偏差;而后续的实验结果也证明了约束相对相似度对于身份保持是不够的,因此,为了保持人脸结构,研究人员引入了一组空间结构约束,但该约束抑制了形状变形,并可能导致视觉伪影;在进行少数样本域迁移的同时,研究人员试图用gan逆映射技术产生的假数据来微调预训练的stylegan模型,其中提出了几个特征的约束进行参数微调;还提出使用gan逆映射为风格样例生成“真实人脸”,并进行风格混合(style mixing),从而构成假的训练对stylegan模型进行过拟合训练;以上两个方法都可以适用于单样本风格化的极端情况,但不能有效捕捉样例风格,处理具有较大形状变形的风格,而动漫化通常带有较大的脸部夸张形式。
3、早期纹理合成方法无法实现动漫风格的夸张,同时无法保证颜色上与风格参照图的统一;而目前的少样本图像生成方法虽然实现了少样本数据集上的风格化图像生成,但是其对人物身份的约束不足,导致无法保持身份;或者存在人物身份约束过强,导致风格化效果降低的问题,同时因为是图像生成网络,无法完成图像翻译任务;有的虽然实现了少样本甚至是单样本的人物动漫化模型,但是不能够捕捉样例风格,在输入存在巨大形状夸张的动漫风格时,生成的图像夸张化不足。
4、因此,现有技术还有待于改进和发展。
技术实现思路
1、本发明的主要目的在于提供一种基于少样本学习的图像处理方法及相关设备,旨在解决现有技术中在对真实人脸图像进行动漫化处理过程中动漫风格和人脸特征无法同时保持,使得生成的动漫化图像的效果无法满足用户需求的问题。
2、为实现上述目的,本发明提供一种基于少样本学习的图像处理方法,所述基于少样本学习的图像处理方法包括如下步骤:
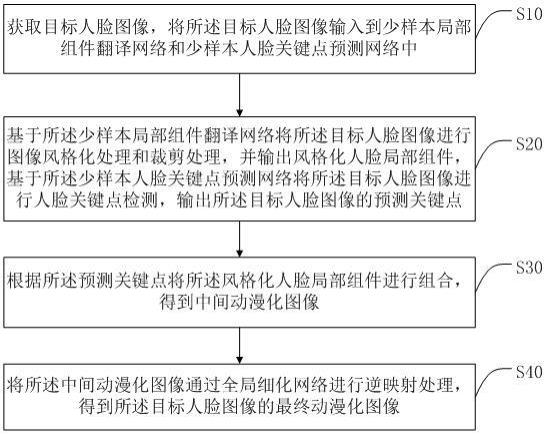
3、获取目标人脸图像,将所述目标人脸图像输入到少样本局部组件翻译网络和少样本人脸关键点预测网络中;
4、基于所述少样本局部组件翻译网络将所述目标人脸图像进行图像风格化处理和裁剪处理,并输出风格化人脸局部组件,基于所述少样本人脸关键点预测网络将所述目标人脸图像进行人脸关键点检测,输出所述目标人脸图像的预测关键点;
5、根据所述预测关键点将所述风格化人脸局部组件进行组合,得到中间动漫化图像;
6、将所述中间动漫化图像通过全局细化网络进行逆映射处理,得到所述目标人脸图像的最终动漫化图像。
7、此外,为实现上述目的,本发明还提供一种基于少样本学习的图像处理系统,其中,所述基于少样本学习的图像处理系统包括:
8、目标人脸图像输入模块,用于获取目标人脸图像,将所述目标人脸图像输入到少样本局部组件翻译网络和少样本人脸关键点预测网络中;
9、目标人脸图像处理模块,用于基于所述少样本局部组件翻译网络将所述目标人脸图像进行图像风格化处理和裁剪处理,并输出风格化人脸局部组件,基于所述少样本人脸关键点预测网络将所述目标人脸图像进行人脸关键点检测,输出所述目标人脸图像的预测关键点;
10、中间动漫化图像生成模块,用于根据所述预测关键点将所述风格化人脸局部组件进行组合,得到中间动漫化图像;
11、最终动漫化图像生成模块,用于将所述中间动漫化图像通过全局细化网络进行逆映射处理,得到所述目标人脸图像的最终动漫化图像。
12、此外,为实现上述目的,本发明还提供一种终端,其中,所述终端包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的基于少样本学习的图像处理程序,所述基于少样本学习的图像处理程序被所述处理器执行时实现如上所述的基于少样本学习的图像处理方法的步骤。
13、此外,为实现上述目的,本发明还提供一种计算机可读存储介质,其中,所述计算机可读存储介质存储有基于少样本学习的图像处理程序,所述基于少样本学习的图像处理程序被处理器执行时实现如上所述的基于少样本学习的图像处理方法的步骤。
14、本发明中,获取目标人脸图像,将所述目标人脸图像输入到少样本局部组件翻译网络和少样本人脸关键点预测网络中;基于所述少样本局部组件翻译网络将所述目标人脸图像进行图像风格化处理和裁剪处理,并输出风格化人脸局部组件,基于所述少样本人脸关键点预测网络将所述目标人脸图像进行人脸关键点检测,输出所述目标人脸图像的预测关键点;根据所述预测关键点将所述风格化人脸局部组件进行组合,得到中间动漫化图像;将所述中间动漫化图像通过全局细化网络进行逆映射处理,得到所述目标人脸图像的最终动漫化图像。本发明通过采用一种适用于gan(生成对抗网络)域迁移的跨域中心一致性损失和基于两阶段的少样本肖像动漫化网络来对人脸图像进行动漫化处理,可以实时对真实人脸图像进行动漫化图像生成,生成的动漫化图像同时具有良好的动漫风格特征和人脸特征保持。
- 还没有人留言评论。精彩留言会获得点赞!