基于分组注意力融合的伪装物体分割方法
本发明属于计算机视觉及人工智能,涉及基于分组注意力融合的伪装物体分割方法。
背景技术:
1、伪装物体分割,是指识别出图像中与背景高度相似的对象。
2、近年来,在目标分割领域,伪装目标分割受到越来越多的研究者的关注。伪装一词,来源于生物学,是一种强大而巧妙的隐藏自身的方式。伪装物体一般通过颜色变化、环境模仿或部分遮挡来融入周围环境,自然界中的许多动物都利用这种方式来躲避天敌或捕食猎物。由于具备识别伪装对象的能力,所以伪装物体分割算法在很多领域都有广泛的应用前景,如物种发现、息肉分割、肺部感染分割、灾害搜救等。
3、但与此同时,目标和背景的高度相似性也对伪装物体分割任务带来了更大的挑战。不同于一般的目标分割算法,伪装目标分割需要网络具备更大的全局感知能力、捕获更多的高级语义信息才能准确的将目标从背景中分离出来。现有的方法大多基于cnn网络提取特征,借助边界或纹理线索来增强模型感知能力,在一些复杂场景下,无法准确的分割伪装目标。
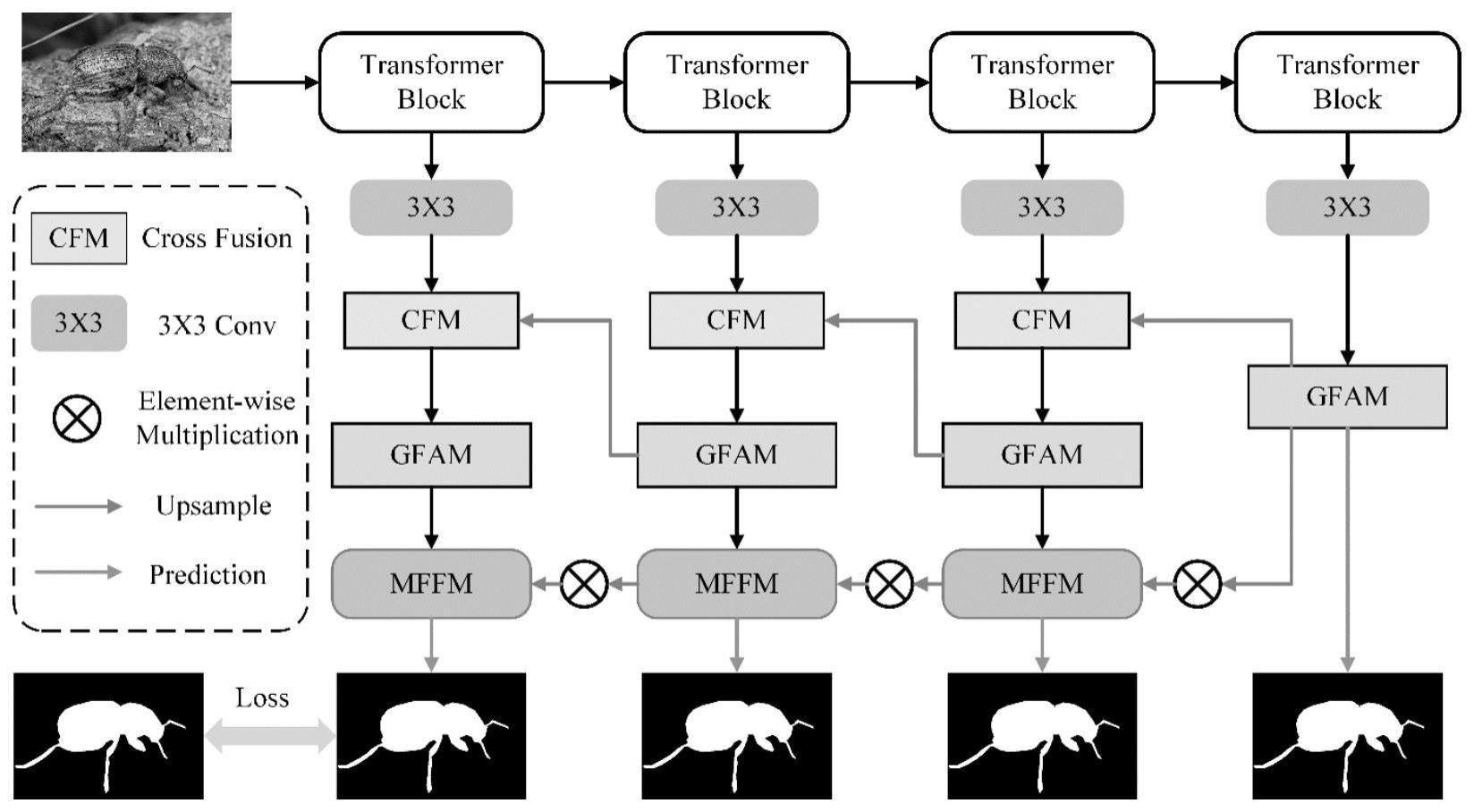
4、我们采用transformer框架作为提取特征的主干网络,借助自注意力机制建立全局感知能力;然后我们设计了一个分组融合模块,借助分组注意力机制,进一步挖掘高级语义特征,增强网络对于前景和背景的辨别能力;最后构建多尺度特征融合模块,由粗到细逐级恢复高分辨的预测图像。
技术实现思路
1、本发明的目的是提供基于分组注意力融合的伪装物体分割方法,实现对伪装物体的准确分割;大幅提高了网络对图像前景和背景的辨别能力,解决了现有方法在复杂场景下难以分割伪装物体的问题。
2、本发明所采用的技术方案是,基于分组注意力融合的伪装物体分割方法,具体按以下步骤实施:
3、步骤1,对输入图像利用图像特征提取模块进行特征提取;
4、步骤2,构建分组注意力模块;
5、步骤3,构建多尺度特征融合模块。
6、本发明的特点还在于:
7、其中步骤1具体为图像特征提取模块采用带金字塔结构的transformer模块对输入图像进行特征提取;
8、其中步骤1具体按以下步骤实施:
9、步骤1.1,输入图像首先经过第一个transformer模块,对待检测图像进行处理,输出第一特征图;
10、步骤1.2,第一特征图经过第二个transformer模块,对特征进行处理,操作同上,输出第二特征图f2;
11、步骤1.3,第二特征图经过第三个transformer模块,对特征进行处理,操作同上,输出第三特征图f3;
12、步骤1.4,第四特征图经过第四个transformer模块,对特征进行处理,操作同上,输出第四特征图f4;
13、其中步骤1.1具体按以下步骤实施:
14、步骤1.1.1,输入图像首先经过patchembedding模块,对图像进行划分,将输入图像h×w×3经过划分后为其中h和w为图像的宽和高,pi和ci为超参数,分别代表划分的块数和输出的通道数,此处的划分采用重叠交叉划分,增强块与块之间的交互,使网络捕获更多的全局信息;
15、步骤1.1.2,处理后的特征,经过带金字塔池化的自注意力机制模块,公式表示如下:
16、
17、式中,分别代表自注意力机制中的quary、经过池化操作的key和经过池化操作的value,dhead代表多头注意力的数量,softmax()指激活函数;
18、步骤1.1.3,经过自注意力后的特征,再经过一个前馈神经网络处理,使用larynorm做层归一化处理,然后使用线性映射将特征放大四倍,再使用线性映射将特征缩小四倍,最终输出第一特征图f1;
19、其中步骤2构建分组注意力模块具体按以下步骤实施:
20、步骤2.1,对主干网络提取到的四层特征分别进行降维操作;
21、步骤2.2,对降维后的四组特征进行交叉融合;
22、步骤2.3,对交叉融合后的四组特征记作f′1,f′2,f′3,f′4,分别进行分组注意力融合;
23、其中步骤2.1具体按以下步骤实施:
24、步骤2.1.1,对四层特征分别做卷积核为3x3的卷积操作,输出通道数设置为64,使用batchnorm进行归一化,最后使用relu操作做激活处理;
25、步骤2.1.2,对处理后的四层特征分别做3x3的卷积操作,输入通道和输出通道设置一致,均为64,记作f1,f2,f2,f4;
26、其中步骤2.2具体按以下步骤实施:
27、步骤2.2.1,第四层特征由于没有上层特征,所以对其仅仅进行两层3x3的卷积操作,通道数保持一致;
28、步骤2.2.2,将处理后的第四组特征按通道拆分为n组,将未处理的第三组特征按通道数拆分为n组,将第四组上采样后进行交叉融合,融合后经过一个3x3的卷积模块进行融合,输入通道数为128,输出通道数为64;
29、步骤2.2.3,将处理后的第三组特征按通道拆分为n组,将未处理的第二组特征按通道数拆分为n组,将第三组上采样后进行交叉融合,融合后经过一个3x3的卷积模块进行融合,输入通道数为128,输出通道数为64;
30、步骤2.2.4,将处理后的第二组特征按通道拆分为n组,将未处理的第一组特征按通道数拆分为n组,将第二组上采样后进行交叉融合,融合后经过一个3x3的卷积模块进行融合,输入通道数为128,输出通道数为64;
31、其中步骤2.3具体按以下步骤实施:
32、步骤2.3.1,对交叉融合后的第四组特征,首先按通道数拆分为m组,记作gi,i∈{1,...,m},首先对g1进行升维操作,使用3x3卷积将其通道数扩充为原来的3倍,记作g1j,j∈{1,2,3};
33、步骤2.3.2,将g1j按通道数拆分为3组,取第一组g11与g2进行cat操作;之后g2同样进行通道数扩充,得到g2j,j∈{1,2,3};对于g3操作同上,最终共生成m组特征,每一组特征都又被按通道数拆分为三组;
34、步骤2.3.3,将m组特征每一组中的第一组gi1,一起cat后进行卷积操作,输出通道设置为64;
35、步骤2.3.4,将m组特征每一组中的第三组gi3,一起cat后进行卷积操作,输出通道设置为1;
36、步骤2.3.5,最终将得到的通道数为1的特征与通道数为64的特征逐元素相乘,再与最初交叉融合后的特征f1′逐元素相加,做残差连接,得到最终的输出fi″,i∈{1,2,3,4};整个分组注意力机制可用表示为如下公式:
37、fi″=fi′+ga(cbr(chunk(fi′,k))),k∈{1,...,m} (2)
38、式中,chunk()表示按通道拆分操作,cbr()表示卷积、batchnorm和relu操作,ga()表示分组注意力操作;
39、其中步骤3具体按以下步骤实施:
40、步骤3.1,对分组注意力模块得到的四层特征进行多尺度融合;
41、步骤3.2,将预测图与真实标注图像做损失计算,反向传播调整网络参数;
42、其中步骤3.1具体按以下步骤实施:
43、步骤3.1.1,对于分组注意力模块输出的第四层特征f″4,由于没有上层特征,故直接对其进行上采样操作,然后进行3x3卷积操作,再与第三层特征做逐元素乘法,记作公式表示如下:
44、
45、步骤3.1.2,对于注意力模块输出的第三层特征f″3,将其上采样后再使用3x3卷积操作,然后步骤3.1.1得到的f3*也同样进行上采样和卷积,二者与上层特征f2″一起做逐元素乘法,得到f2*;公式表示如下:
46、
47、步骤3.1.3,对于注意力模块输出的第二层特征f″2,将其上采样后再使用3x3卷积操作,然后步骤3.1.2得到的f2*也同样进行上采样和卷积,二者与上层特征f1″一起做逐元素乘法,得到f1*;公式表示如下:
48、
49、步骤3.1.4,f4″由于没有上层特征,故将其记作p4,将p4上采样并卷积后,与f3*做cat操作,得到p3;p2也由相同操作产生,公式表示如下:
50、pi=cat(fi*,cbr(u(pi+1))),i∈[1,2,3] (6)
51、步骤3.1.5,最终得到四组特征pi,i∈{1,2,3,4},将p1经过两层3x3卷积操作,第一层保持通道数不表,第二层将通道数缩减为1,得到最终的预测图p;
52、步骤3.2具体为:
53、步骤3.2.1,将预测图p与真实标注图像g分别做加权二进制交叉熵损失与加权交并比损失,公式表示如下:
54、
55、步骤3.2.2,将预测图p与真实标注图像g做不确定性感知损失计算,公式表示如下:
56、lu=λ×(1-|2p-1|2) (8)
57、式中,p为预测图中每一点的像素值,λ超参数;
58、步骤3.2.3,两种损失计算相加,作为最终的损失值。
59、本发明的有益效果是:
60、本发明的基于分组注意力融合的伪装物体分割方法不使用卷积神经网络,而是建立在transformer架构之上,借助自注意力机制可以更好地建立全局依赖关系,使用带金字塔结构的transformer模块,可以大大降低计算复杂度,使网络更好地适用于密集预测的分割任务;本发明提出的分组注意力融合模块,采用分组交互的模式,更好地探索通道间的权重关系,通过学习调整来获得最优的权重配比,进一步挖掘了图像的高级语义信息,增强了网络对图像前景背景的辨别能力;本发明提出的多尺度特征融合模块,采用由粗到细的融合策略,在最大限度保留网络的全局感知能力的同时,有效融合多级特征生成准确的高分辨预测图。
- 还没有人留言评论。精彩留言会获得点赞!