物理冶金指导工业大数据挖掘的热轧低合金钢设计方法
本发明涉及热轧低合金钢和深度学习应用,尤其涉及一种物理冶金指导工业大数据挖掘的热轧低合金钢设计方法。
背景技术:
1、在实际的工业生产中,钢铁产品的生产规模庞大,生产工艺流程中参数复杂,且涉及到炼钢、连铸、控轧控冷等多段生产工序,受到环境、设备以及人为等多种因素的影响,使得工业数据库具有数量多、维度高和质量低的特点。针对庞大的工业数据信息,人工经验或传统物理冶金方法均难以从其中的复杂关系中有效分析和挖掘出可靠的数据关联性和机理信息,从而造成其中有效信息的浪费和生产工艺优化的低效。同时由于钢铁生产工艺流程长而复杂的特点,采用正交试错法在工业生产线上开发新型合金需要经过繁琐的流程操作和耗时较长的验证周期,使得合金开发的效率较低,难以推动新材料新工艺的快速研发。
2、随着人工智能技术与大数据的接轨,目前在材料领域有着广泛的应用。使用人工智能算法建立的多种机器学习模型在材料领域表现出了强大的优势,例如能够深度挖掘数据内在的关联信息,实现高效的材料优化设计,所建立模型的预测精度高且其参数具有较好的泛化性等,能够为钢铁生产领域的研究和应用提供高效可行的技术手段,如wu等人基于人工神经网络(ann)建立铌钛微合金钢的力学性能预测模型,对拉伸性能实现了准确预测,并结合多目标优化算法实现了s360钢的热轧工艺设计。因此基于计算方法实现钢铁材料实验室合金设计和工业产品转化的开发设计理念有利于缩短产品开发的时间和资金成本,对加速钢铁材料研发具有极其重要的研究意义。
3、在金属热成形加工过程中,微观组织的调控会对材料力学性能的优化产生至关重要的影响,迄今为止通过物理冶金学原理建立成分-工艺-组织-性能之间的关系已被广泛应用于钢铁材料的力学性能预测。钢材力学性能主要受到其合金成分、生产工艺以及微观组织的影响,基于目前已形成较为成熟的物理冶金学理论来建立物理模型能够较为准确的描述材料组织演变和预测力学性能。
4、钢铁工业生产中大多数热轧、冷轧等钢铁板材产品生产工艺流程复杂、且各工序中涉及到多个操作流程及大量关键工艺参数,另一方面,工业生产线上钢铁产量巨大且仍在不断增长。面对数量庞大且参数复杂的工业数据,传统的建模策略对工业大数据的利用率较低且数据分析效果较差,因此难以实现对工业热轧钢板力学性能的准确预测。为了解决机理模型所带来的问题,采用数据分析能力突出的人工智能技术进行工业大数据分析得到了广泛关注。adel等人根据x70管线钢的化学成分开发了一种ann模型,以元素的重量百分比作为输入对其拉伸和冲击性能实现了准确预测。kisi等人利用多层感知器(mlp)等多种方法开发了分析公式来预测钢梁的超强度。但目前基于人工智能算法的建模方式虽然能够实现钢材性能的准确预测,但其对材料的性能预测和设计只是一个数学过程,设计过程很少涉及物理冶金参数,这大大浪费了物理冶金学在材料设计中的独特优势。
技术实现思路
1、本发明要解决的技术问题是针对上述现有技术的不足,提供一种物理冶金指导工业大数据挖掘的热轧低合金钢设计方法,本方法将物理冶金机制引入到工业大数据分析中,同时结合优化算法形成完备的设计平台,设计结果更加符合物理冶金学原理。
2、为了实现本发明的上述目的,本发明所采取的技术方案是:
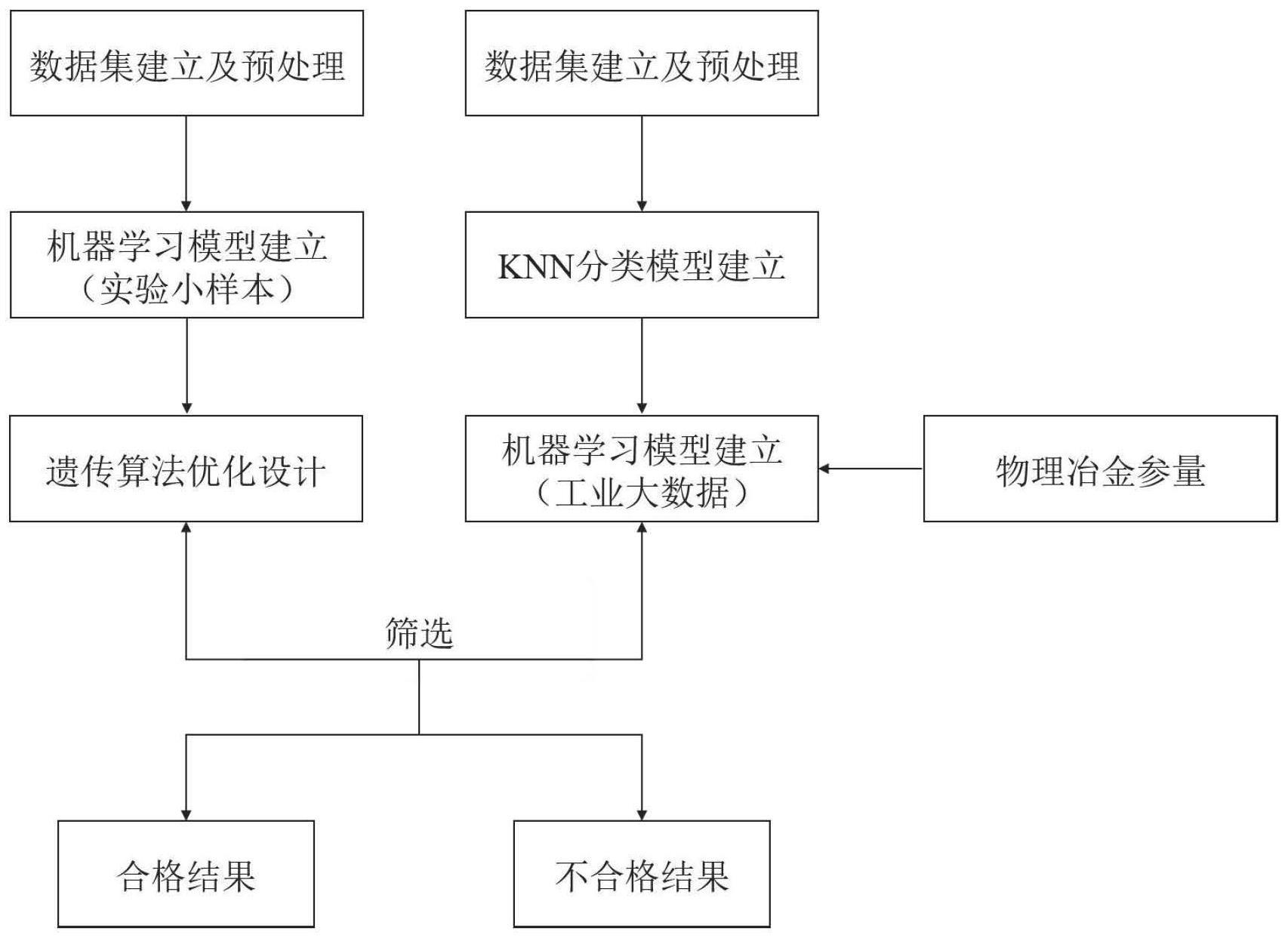
3、一种物理冶金指导工业大数据挖掘的热轧低合金钢设计方法,包括以下步骤:
4、步骤1将一段历史年份的工业产线数据提取出来,建立为工业数据集,并对工业数据集进行预处理,得到标准数据集。
5、步骤具体包括:
6、步骤1.1提取一段历史年份的热轧低合金钢h种材料的成分、工艺及其对应的目标性能。使用提取的h组数据共同组成原始数据集,其中所述成分为材料的元素及含量,所述工艺为材料的工艺参数。将原始数据集作为材料目标性能预测的有效数据并对原始数据集中的所有数据进行标准化处理,形成初始数据集。数据标准化公式为:
7、
8、其中x为待转换的数值,xscale为转换后的数值,max和min分别为参数在数据集中的最大值和最小值。
9、步骤1.2通过计算pearson相关性系数对初始数据集中成分、工艺与目标性能的相关性进行分析,删除其中相关性低于设定阈值的特征,形成标准数据集。
10、步骤2根据标准数据集中的数据特点,建立基于knn算法的knn分类模型并对标准数据集进行分类。
11、步骤具体包括:
12、步骤2.1knn算法中包括两个参数,分别为用来描述两个样本点相似程度的距离和所选取的相邻样本的数量k。使用欧几里德距离作为上述的距离,在设定的范围内使用knn算法对k的每个取值进行逐个测试,根据分类结果的准确率来确定参数k的最优值。
13、步骤2.2将工业数据集的前三年数据按设定比例划分为训练集和测试集,将工业数据集的第四年数据作为验证集,建立knn分类模型。通过主成分分析pca将高维数据投影到较低维空间中,将高维数据降低到设定维度,使用knn分类模型完成数据分类并形成若干个子数据集。
14、步骤3依据各子数据集的成分和工艺数据特点和pearson相关性系数,选择相应类别的输入特征。
15、步骤4根据步骤2.2中分类得到的子数据集,构建基于多种回归策略的大数据性能预测模型。同时根据热轧低合金钢的力学性能,引入性能相关的物理冶金参数pm,指导基于多种回归策略的大数据性能预测模型的机器学习过程。上述基于多种回归策略的大数据性能预测模型包括svr-pm模型,mlp-pm模型,rf-pm模型,xgb-pm模型,gbr-pm模型,cnn-pm模型。其中上述svr-pm模型中包含两种不同模型,分别由线性核函数及高斯核函数作为其核函数建立。
16、上述svr-pm模型是基于svr算法建立的并在其中加入了物理冶金参数pm。
17、设置其核函数为高斯核函数并优化参数c和γ,其中高斯核函数的表达式如下所示:
18、
19、其中x'为核函数中心,||x-x'||2为向量x和向量x'的欧氏距离,σ是带宽,用来控制径向作用范围。
20、设置其核函数为线性核函数并优化参数c和γ,其中线性核函数的表达式如下所示:
21、k(x,x')=xtx'+c
22、其中x'为核函数中心,c为常数。
23、上述mlp-pm模型是基于mlp算法建立的并在其中加入了物理冶金参数pm。将adam作为优化器,优化其隐藏层层数和神经元个数。
24、上述rf-pm模型是基于rf算法建立的并在其中加入了物理冶金参数pm。优化其中的参数n_estimators和max_features。
25、上述xgb-pm模型和gbr-pm模型是分别基于xgb算法和gbr算法建立的并加入了物理冶金参数pm。优化其learning_rate和n_estimators参数,其他参数均设置为固定值。上述其他参数包括n_estimators、subsample、colsample_bytree、max_depth、及min_child_weight。
26、上述cnn-pm模型是基于cnn算法建立的并加入了物理冶金参数pm。设定其激活函数为relu,优化器为adam,对cnn-pm模型进行训练,周期为10000次。激活函数relu的表达式如下所示:
27、relu(x)=max(x,0)
28、其中x为输入特征,relu(x)为上述激活函数,max(x,0)为一个取大值函数,比较x与0的大小并输出其中较大值。
29、步骤5对分类后的每个子数据集都根据步骤4建立模型,并针对每个模型选择最优的算法。
30、步骤具体包括:
31、步骤5.1将工业数据集的前三年数据按设定比例划分为训练集和测试集,将工业数据集的第四年数据作为验证集,进行了设定次数的数据随机划分以保证预测结果的稳定性;
32、步骤5.2根据基于多种回归策略的大数据性能预测模型的预测结果,计算平均绝对误差mae和有效率er,平均绝对误差mae和有效率er的表达式如下所示:
33、
34、
35、其中n是样本总数,f(xi)和yi分别代表第i个数据点的预测值和实测值,ne为在规定误差范围内的数据量,nall为数据集的总数据量;
36、步骤5.3通过计算在训练集和测试集中预测结果的mae和er来进行不同模型预测效果的对比,筛选出各类别中的最优回归算法,筛选原则为:首先根据训练集结果,从七个模型中排除mae最大的两个模型,再根据测试集结果,从剩下的五个模型中排除mae最大的两个模型,从而筛选出了三个在训练集和测试集中预测效果均较好的模型。最后通过对比这三个模型在验证集中预测结果的mae以及在所有数据中预测结果的有效率,挑选出各类别中效果最好的模型;
37、步骤6使用低合金钢实验得到的热轧低合金钢数据建立数据集,对其进行数据标准化,建立实验小样本数据集,然后进一步基于所建立的实验小样本数据集使用rf算法建立性能预测模型,并对rf算法的参数进行优化。最后选取最优模型用于后续的实验合金优化设计。
38、步骤具体包括:
39、步骤6.1使用低合金钢实验得到的热轧低合金钢的数据建立数据集,对其进行数据标准化,形成实验小样本数据集。
40、步骤6.2计算表示实验小样本数据集中成分和工艺与目标性能之间相关性的pearson相关性系数,删除其中相关性低于设定阈值的特征形成实验小样本标准数据集,依据数据集的自身特点和pearson相关性系数,选择输入参数。
41、步骤6.3将实验小样本标准数据集按设定比例划分为训练集和测试集,并对训练集和测试集进行设定次数的随机划分;
42、步骤6.4然后根据pearson相关性系数判断特征重要性程度并选择不同维度的输入项建立基于rf算法的实验小样本预测模型,根据预测结果的平均绝对误差mae和决定系数r2筛选出模型的最佳输入维度和输入特征参数,平均绝对误差mae和决定系数r2的表达式如下所示:
43、
44、其中n为样本个数,f(xi)和yi分别代表第i个数据点的预测值和实测值;
45、
46、其中n是样本总数,f(xi)和yi分别代表第i个数据点的预测值和实测值,ymean为原数据的平均值。
47、步骤6.5优化rf算法中的参数“max_features”和“n_estimators”,其他参数均为默认参数值;
48、步骤7将实验小样本预测模型和遗传算法相结合进行合金成分工艺的优化设计;采用目标性能的高低作为遗传算法的适应度函数,将遗传算法用于优化设计成分及工艺来获得最佳目标性能的材料;
49、具体步骤包括:
50、步骤7.1在实验小样本标准数据集上,采用遗传算法将数据随机产生m条染色体,构成染色体组l,每个染色体都包含了成分和工艺;
51、步骤7.2将各染色体个体中的成分及工艺,通过物理冶金模型计算得到其对应的冶金参数,并将各染色体的成分、工艺及其相应的冶金参数构成第v代数据集,其中v代表目前的迭代次数;将第v代数据集中的数据进行标准化处理,将标准化后的数据作为输入参数带入最优模型,然后计算出目标性能;
52、步骤7.3由适应度函数计算出各个染色体个体的适应度,将所有适应度按照从高到低的顺序排列;判断目前迭代次数是否为第一次迭代,若是,那么保留目前染色体组中适应度高的90%的染色体个体,删除剩余10%,然后执行步骤7.4;若否,保留目前染色体组中适应度高的90%的染色体个体,而将剩余10%的染色体个体进行选择、交叉、变异操作来产生新的染色体,从而获得新的染色体组kv,该染色体组kv由染色体组kv-1中适应度高的90%的染色体个体和新生成的染色体组成,然后执行步骤7.4;
53、步骤7.4按照步骤7.3得到的结果判断是否达到终止条件,若是,则输出合金的成分、工艺及其目标性能,并将该结果放入设计结果集f中,;若否,则执行步骤7.2。所述的终止条件为当前染色体组中的全部染色体个体都收敛至同一结果,并且连续十次以上迭代的结果都相同;
54、步骤8对所建立的实验小样本预测模型进行筛选,筛选准则为:r2在0.8以上且训练集和测试集r2偏差在0.2以内的模型,得到准确性较高的模型指导合金优化设计;根据成分工艺及目标性能对设计结果进行筛选以获得较优的设计方案;
55、步骤9采用建立的基于多种回归策略的大数据性能预测模型,对实验设计结果进行有效的性能验证和方案筛选,得到满足目标性能热轧低合金钢的成分和工艺。
56、采用上述技术方案所产生的有益效果在于:
57、本发明提供一种物理冶金指导工业大数据挖掘的热轧低合金钢设计方法,该方法应用物理冶金学指导的各种模型建立起成分、工艺与目标性能之间的关系,使用遗传算法ga迅速准确的在数据集范围内对目标性能进行优化设计,采用建立的基于多种回归策略的大数据性能预测模型对得到的大量设计结果进行筛选,甄别出可靠性较高的设计结果,形成完备的热轧低合金钢设计平台。本发明中首次利用物理冶金原理指导工业大数据分析,使工业大数据分析富有了物理冶金学含义,并且该方法可以提升模型的泛化能力,使设计更为高效,设计结果更加符合物理冶金学原理。
- 还没有人留言评论。精彩留言会获得点赞!