融合神经辐射场的音频驱动的说话人视频合成方法及系统
本发明涉及说话人视频合成,尤其涉及一种融合神经辐射场的音频驱动的说话人视频合成方法及系统。
背景技术:
1、近年来,随着深度学习技术的不断发展,说话人视频合成技术取得了很大的进展。音频驱动的说话人视频合成技术是指利用语音作为输入,生成与该语音内容相匹配的人物视频。这种技术在虚拟人物、语音合成、视频会议等领域具有广泛的应用前景。音频驱动的说话人视频合成,其目的就是通过一段源音频驱动对应目标视频的生成,且目标视频的口型与输入的源音频保持一致。
2、目前常见的音频驱动的说话人视频合成方法有基于纯图像的方法和基于模型的方法。基于纯图像的方法:采用深度学习的方法提取各种人物图片的特征,建立一个神经网络模型以此应用于新的目标人物,使用目标人物的人脸控制给定面部的姿势和表情。该模型可以用于轻量级、复杂的视频和图像编辑。基于模型的说话人合成方法:在生成逼真的人脸图像时采用先验信息的方法,即这种方法的核心是统计模型,例如面部形状的3dmorphable models(三维形变模型)或者2d landmarks(关键点特征),通过音频特征和3dmm模型的面部特征相结合,生成目标说话人的面部表情动画。
3、但是现有技术存在以下的不足:
4、1.基于纯图像的说话人合成方法:只能生成静止的人脸裁剪图像。无法生成具有背景和目标人物自然拍摄风格的全尺寸图像,且受到输入图片尺寸的大小,无法生成高分辨率的图像。
5、2.基于模型的说话人合成方法:例如3dmm依赖于中间表示(即中间过程所生成的三维参数),以弥合音频输入和视频输出之间的差距,由于中间表示造成的信息损失,可能会导致原始音频信号与学习到的人脸形变之间的语义不匹配,在表示人脸的形状和纹理方面具有一定的限制,例如无法很好地处理头发、眼睛、嘴唇等细节区域,限制了模型的精度和逼真度。3dmm模型的训练需要大量的高质量的面部数据,但是很难获得具有足够多样性的面部数据集,这限制了模型的泛化能力和适应性。
技术实现思路
1、为此,本发明实施例提供了一种融合神经辐射场的音频驱动的说话人视频合成方法及系统,用于解决现有技术中只能生成静止的人脸裁剪图像以及依赖于中间表示导致原始音频信号与学习到的人脸形变之间的语义不匹配的问题。
2、为了解决上述问题,本发明实施例提供一种融合神经辐射场的音频驱动的说话人视频合成方法,该方法包括:
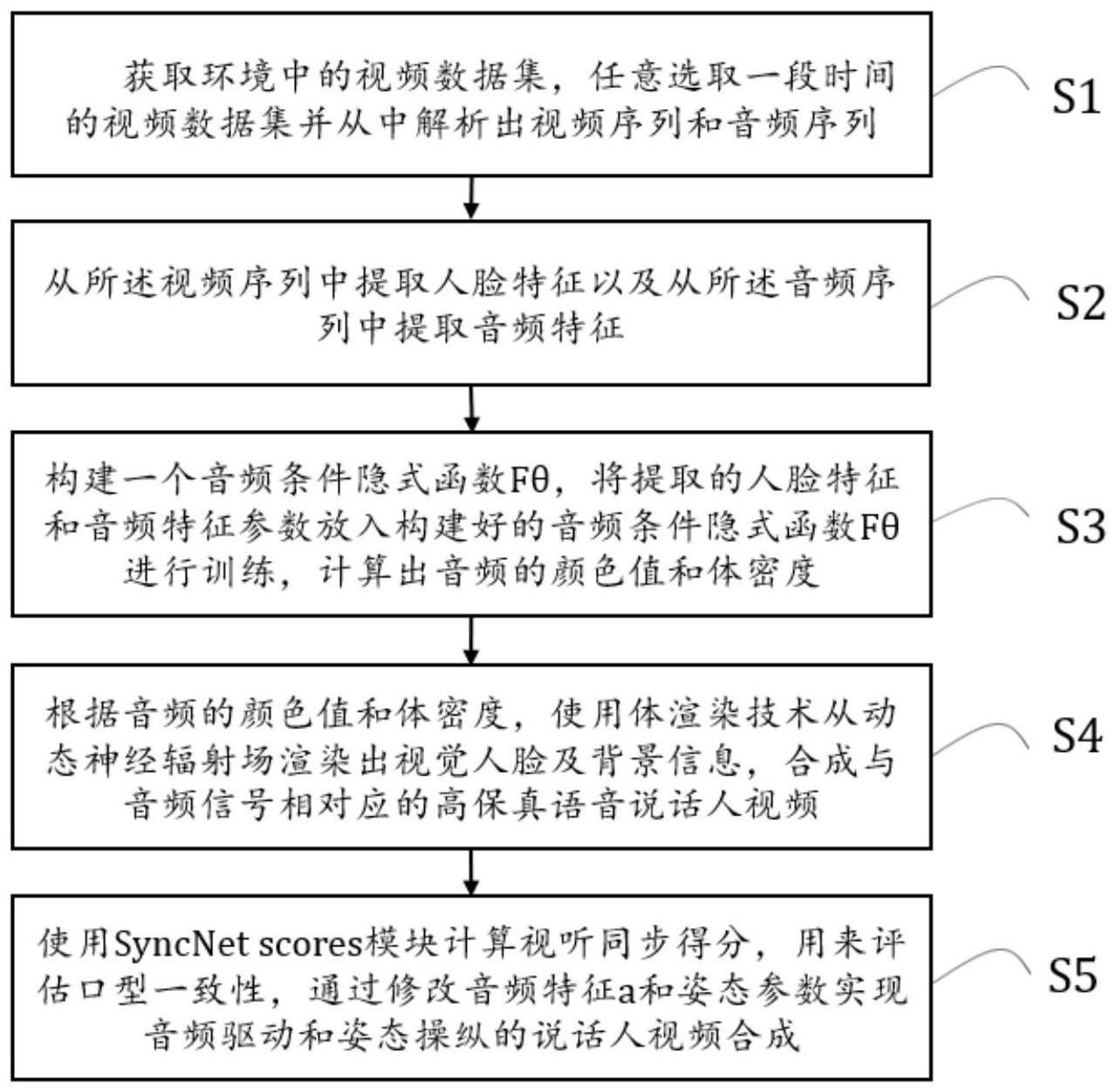
3、s1:获取环境中的视频数据集,任意选取一段时间的视频数据集并从中解析出视频序列和音频序列;
4、s2:从所述视频序列中提取人脸特征以及从所述音频序列中提取音频特征;
5、s3:构建一个音频条件隐式函数fθ,将提取的人脸特征和音频特征参数放入构建好的音频条件隐式函数fθ进行训练,计算出音频的颜色值和体密度,所述隐式函数fθ用于表示动态神经辐射场;
6、s4:根据音频的颜色值和体密度,使用体渲染技术从动态神经辐射场渲染出视觉人脸及背景信息,合成与音频信号相对应的高保真语音说话人视频。
7、优选地,还包括使用syncnet scores模块计算视听同步得分,用来评估口型一致性,通过修改音频特征a和姿态参数π实现音频驱动和姿态操纵的说话人视频合成
8、优选地,从所述视频序列中提取人脸特征的方法为:
9、采用人脸面部解析方法分割视频序列中的人脸部位并提取干净的背景,得到解析后的视频帧,对解析后的视频帧序列进行平移和旋转,将人脸特征转换到规范空间。
10、优选地,从所述音频序列中提取音频特征的方法为:
11、使用语音识别工具从所述音频序列中提取音频特征。
12、优选地,所述音频条件隐式函数fθ模型为:
13、fθ:(a,d,x)→(c,σ)
14、其中a表示音频特征,d表示观看方向,x表示物体的3d位置,c表示颜色值,σ表示体密度。
15、优选地,根据音频条件隐式函数fθ模型得出颜色值c和体密度σ,接着使用体渲染技术,将采样的体密度σ和颜色值c沿着每个像素投射的光线进行累积,计算图像渲染结果的输出颜色c,计算公式为:
16、
17、
18、其中,r(t)=o+td,o表示相机中心,d表示观看方向,tn表示近界,tf表示远界,θ表示角度,π表示姿态参数,σθ(·)和cθ(·)表示隐式函数fθ模型的输出,t(t)为从tn到t沿光线的累计透射率。
19、优选地,使用l2损失函数,优化渲染出的图像和训练真实图像之间的误差,表示如下:
20、其中,ir表示渲染出的图像,ir∈rw×h×3,ig表示训练的真实图片,ig∈rw×h×3,w表示宽度,h表示高度,a表示音频特征,π表示姿态参数,θ表示角度,w表示宽度,h表示高度。
21、本发明实施例还提供了一种融合神经辐射场的音频驱动的说话人视频合成系统,该系统包括:
22、采集模块,用于获取环境中的视频数据集,任意选取一段时间的视频数据集并从中解析出视频序列和音频序列;
23、特征提取模块,用于从所述视频序列中提取人脸特征以及从所述音频序列中提取音频特征;
24、计算模块,用于构建一个音频条件隐式函数fθ,将提取的人脸特征和音频特征参数放入构建好的音频条件隐式函数fθ进行训练,计算出音频的颜色值和体密度,所述隐式函数fθ用于表示动态神经辐射场;
25、合成模块,用于使用体渲染技术从动态神经辐射场渲染出视觉人脸及背景信息,合成与音频信号相对应的高保真语音说话人视频;
26、评估模块,使用syncnet scores模块计算视听同步得分,用来评估口型一致性,通过修改音频特征a和姿态参数π实现音频驱动和姿态操纵的说话人视频合成。
27、本发明实施例还提供了一种电子装置,其特征在于,包括处理器、存储器和总线系统,所述处理器和存储器通过该总线系统相连,所述存储器用于存储指令,所述处理器用于执行存储器存储的指令,以实现上述任意一项所述的融合神经辐射场的音频驱动的说话人视频合成方法。
28、本发明实施例还提供了一种计算机存储介质,其特征在于,所述计算机存储介质存储有计算机软件产品,所述计算机软件产品包括的若干指令,用以使得一台计算机设备执行上述任意一项所述的融合神经辐射场的音频驱动的说话人视频合成方法。
29、从以上技术方案可以看出,本发明申请具有以下优点:
30、1.相较于基于纯图像的说话人合成方法,本发明借助于神经辐射场生成具有背景和目标人物自然拍摄风格的图像,使得生成的图像不是静止的人脸裁剪图像,且不受输入图像大小的限制。
31、2.相较于基于模型的说话人合成方法,由于中间表示造成的信息损失,可能会导致原始音频信号与学习到的人脸变形之间的语义不匹配。本发明不依赖于任何中间表示,将输入音频信号的特征直接输入到条件隐式函数中,生成动态神经辐射场,之后用合成与音频对应的高保真视频,且支持音频信号,观看方向和背景图像的自由调整。
32、3.本发明不同于现有的方法,只需要一段3-5分钟的短视频序列,不依赖于中间表示过程,简化了生成过程,借助于改进的神经辐射场,生成高保真全场景的说话人合成视频。
- 还没有人留言评论。精彩留言会获得点赞!