基于ARIMA和SVR算法的水质预测模型的训练方法及系统
本发明涉及水质监测,具体涉及一种基于arima和svr算法的水质预测模型的训练方法及系统。
背景技术:
1、水质预测工作是根据采集到的历史水质监测数据,通过建模等手段来预测水质的变化趋势,来达到掌握水质现状以及发展趋势的目的。水质预测精度的提高对于水环境质量的评价、水资源管理制度的制定,以及水污染监测与控制系统的规划具有重大意义。不过,以往人们主要采取人工现场采样和实验室仪器分析为主的水质监测方法,难以实时监测到水质情况,比较耗时耗力,无法满足水环境管理的需求。
2、为了解决这一困难,水质在线自动监测系统和现场快速检测仪器开始登上水质监测的舞台,发挥出自己的作用。随着科学技术的发展,生物监测、遥感监测等技术也逐渐被应用到了水质监测当中。在此基础上设置地表水水质监测站点能够实时获取所处水域的水质状况,基于获取的地表水水质数据并结合其他环境大数据可以实现高精度地表水水质预测,具有重大的实际应用意义。例如监察人员能够提前感知流域的污染风险,向上下游站点发送预警信号,并回溯可能的污染来源。对于预测值和实际值相差较大的点位,可以联动相关人员发起人工排查,提高线下执法效率。
3、尽管我们对于水质研究体系已日臻完善,然而,实现高精度水质预测仍面临许多挑战。水质数据在时间和空间两个维度上有复杂的依赖关系。比如在时间维度上,站点某时刻的污染情况可能会与前一天的同一时刻相似;在空间上,站点的污染情况会受到周围水域的影响,传统的数据分析方法难以建模这种复杂的关联性。许多研究者已经提出过一些方法解决地表水水质预测问题。现有的预测方法可以粗略分为基于物理模型的方法和基于机器学习的方法两类。基于机器学习的方法是一种数据驱动的方法,通过挖掘历史数据的隐含的复杂依赖关系来预测监测站点未来一段时间内的各项指标。基于机器学习的方法,能够自动学习从多源数据输入到实际结果间的复杂映射关系。这类方法的缺点是为了达到可观的预测准确率,需要进行复杂的特征工程,提升了模型的落地应用难度。基于物理模型的方法以领域内专业模型为基础,模拟水污染物从排放到扩散的全过程,从而预测各监测站点未来的水质情况。该方法对污染源数据的完整性要求非常高,且模型参数需要专业人员根据不同的水域场景作调整适配,泛化能力较差。
4、鉴于上述缺陷,本发明创作者经过长时间的研究和实践终于获得了本发明。
技术实现思路
1、为解决上述技术缺陷,本发明的目的在于提供一种基于arima-svr算法的关联分析水质预测模型的训练方法及系统。
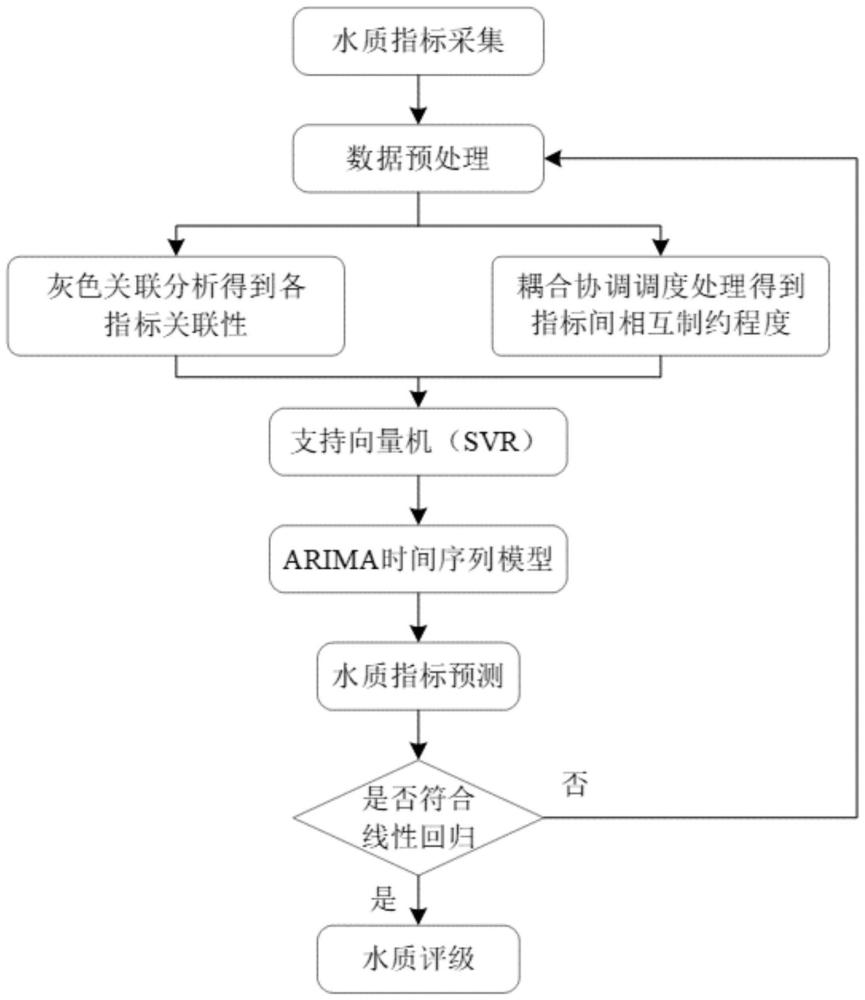
2、一种基于arima和svr算法的水质预测模型的训练方法,包括以下步骤:
3、s1:设定监测点
4、确定需要预测水质指标的河流域,并设置多个监测点;
5、s2:获取监测点数据
6、获取每个监测点的水质信息数据,所述水质信息数据为水质评价指标的时间序列数据,所述水质评价指标包括水质溶解氧含量、ph值、氨氮含量、高锰酸盐指数和总磷含量;
7、将水质信息数据进行预处理,将预处理后的水质信息数据存储至数据库中;
8、s3:监测点水质预测
9、构建水质预测模型,并根据水质信息数据和水质预测模型获得监测点的水质指标预测数据;
10、所述水质预测模型包括耦合协调度模型、灰色关联分析模型和arima-svr模型;
11、通过耦合协调度模型计算各指标因素之间的耦合度协调度,根据耦合协调度计算得到综合协调指数最优参数;
12、根据综合协调指数最优参数以及灰色关联分析模型计算各指标因素之间的灰色关联度;
13、根据水质信息数据对arima-svr模型进行参数训练,得到水质指标预测数据;
14、s4:预测数据检验
15、建立线性回归模型,根据灰色关联度和耦合协调度检验水质指标预测数据是否符合线性回归模型;
16、若满足,则导出水质指标预测数据,否则需重新回到数据处理步骤,检查原始数据是否有缺失、错误;
17、s5:生成水质信息地图
18、将导出的水质指标预测数据展现在地图上,生成水质信息地图,所述监测点的水质指标预测数据通过无线或有线传输的方式上传到服务器,被水质信息地图系统获取。
19、进一步的,步骤s3中通过耦合协调度模型计算各指标因素之间的耦合协调度,根据耦合协调度计算得到综合协调指数最优参数,包括以下内容:
20、对各指标进行归一化处理;
21、通过熵权法计算每个指标的权重;
22、根据指标的权重以及子系统中指标的归一化值计算各指标对水质信息数据的有序度贡献;
23、根据各指标的有序度贡献得到多个指标之间相互作用的耦合度;
24、根据耦合度计算多个指标之间的耦合协调度;
25、通过耦合协调度计算综合协调指数的最优参数。
26、进一步的,步骤s3中根据综合协调指数最优参数以及灰色关联分析模型计算各指标因素之间的关联度,包括以下内容:
27、确定比较序列和母序列,所述母序列即综合协调指数的最优参数,所述比较序列为其它参数;
28、计算比较序列与母序列之间各评价对象的关联系数;
29、将关联系数进行加权处理得到关联度;
30、根据关联度的大小对评价对象进行排序,关联度越大代表评价对象相对于评价标准的重要程度越大。
31、进一步的,步骤s3中将水质信息数据对arima-svr模型进行参数训练,得到水质指标预测数据,包括以下内容:
32、将水质信息数据分为训练集和测试集,基于训练集构建svr模型;
33、将svr模型对时间序列的非线性部分进行建模,采用测试集对svr模型进行测试并得到第一预测结果;
34、根据第一预测结果计算时间序列的线性部分;
35、利用arima模型对时间序列的线性部分进行建模,采用测试集对arima模型进行测试并得到第二预测结果;
36、根据第一预测结果和第二预测结果得到svr-arima模型的最终预测结果,即水质指标预测数据。
37、进一步的,步骤s4中检验水质指标预测数据是否符合线性回归模型,包括以下内容:
38、利用自相关函数acf与偏自相关函数pacf检验水质指标预测值与训练值是否符合关联度和耦合协调度分析结果,若满足,则导出数据;否则需重新回到数据处理步骤,检查原始数据是否有缺失,错误。
39、进一步的,所述第一预测结果的计算,具体包括以下内容:
40、将时间序列yt分为非线性nt和线性残差lt两部分,如下式所示:
41、yt=nt+lt
42、基于svr模型对非线性部分进行建模,测试集对svr预测模型进行测试,得到第一预测结果
43、进一步的,所述第二预测结果的计算,具体包括以下内容:
44、根据时间序列yt和第一预测结果计算svr模型的线性残差序列et,如下式所示:
45、
46、基于arima模型对线性残差部分et进行建模,得到第二预测结果
47、序列et包含原序列中的线性关系,利用arima模型对线性残差部分et进行建模,预测结果用表示,残差序列et是平稳序列且符合arima(5,1,3)模型,估计结果如下式所示:
48、
49、其中∈t-1、∈t-2分别表示第t-1、t-2项的误差;arima(p,d,q)中,p表示p阶自回归,d表示使之成为平等序列所做的差分次数(阶数),q表示q阶滑动平均;arima(5,1,3)表示五阶自回归模型,所作差分次数为1次,3阶滑动平均。
50、进一步的,根据第一预测结果和第二预测结果计算svr-arima模型的最终预测结果,包括以下内容:
51、
52、其中,是svr-arima模型中svr部分所预测出来的第一预测结果,是svr-arima模型中arima部分预测出来的第二预测结果,为svr-arima模型的最终预测结果。
53、进一步的,还包括异常报警:当所述水质指标预测数据超过水质指标评价标准范围时,进行异常报警。
54、一种实施如上述的水质预测模型训练方法的训练系统,包括:
55、监测点设定模块:用于确定需要预测水质指标的河流域,并设置监测点;
56、监测点数据获取模块:用于获取每一个监测点的水质信息数据,水质信息数据包括水质评价指标的时间序列数据,水质评价指标包括水质溶解氧含量、ph值、氨氮含量、高锰酸盐指数和总磷含量;
57、监测点水质预测模块:用于构建水质预测模型,根据水质信息数据和水质预测模型获得监测点的水质指标预测数据,所述水质预测模型包括耦合协调度模型、灰色关联分析模型和arima-svr模型,通过耦合协调度模型计算各指标因素之间的耦合协调度,通过灰色关联分析模型分析各指标因素之间的关联度,将水质信息数据对arima-svr模型进行参数训练,得到水质指标预测数据;
58、预测数据检验模块:建立线性回归模型,根据灰色关联度和耦合协调度检验水质指标预测数据是否符合线性回归模型,若满足,则导出水质指标预测数据,否则需重新回到数据处理步骤,检查原始数据是否有缺失、错误;
59、水质信息地图生成模块:用于将水质指标预测数据展现在地图上,生成水质信息地图,其中,监测点的水质指标预测数据可通过无线或有线传输的方式上传到服务器,被水质信息地图系统获取。
60、与现有技术相比较本发明的有益效果在于:
61、1、本发明通过检测目标河流中的水质溶解氧含量、ph值、氨氮含量、高锰酸盐指数和总磷含量五个指标,利用耦合协调度和灰色关联分析反映各指标之间的相互依赖相互制约程度以及对整个水质系统发展变化态势的关联程度,有效地提高和完善数据预测的准确性,使得数据的处理有效提高,与传统水质预测模型的方法相比较,极大的节约时间成本并提升了预测精度;
62、2、本发明采用svr-arima模型以及线性回归模型,可以针对小规模数据集进行时间序列预测,具有广泛的应用前景,对于河流水质预测自动化、智能化具有重要意义;
63、3、本发明针对小规模数据集,对于一些历史数据少的河流也可以提供准确的数据预测,可以通过关联性的数据分析加强水质系统的整体评估,实现水质精准分级。
- 还没有人留言评论。精彩留言会获得点赞!