基于迭代式策略约束的智能体强化学习方法和装置
本发明涉及机器学习,尤其涉及一种基于迭代式策略约束的智能体强化学习方法和装置。
背景技术:
1、在线强化学习(online reinforcement learning)作为一项日渐重要的ai技术,基本思想是智能体(agent)在与环境不断交互的过程中会获得奖励的刺激,从而学习到获得最大累计奖励值的策略。然而智能体在训练初期与环境的交互探索过程通常为随机探索,其危险性大,成本高且效率低,难以应用在真实的决策优化场景(例如自动驾驶、数据中心节能优化、复杂工业设备的调优等);离线强化学习(offline reinforcement learning)和离线模仿学习(offline imitation learning)方法建立在离线学习的前提下,模型训练过程完全基于预先收集好的离线数据集,不接触真实系统,无需引入额外的高精度仿真或与真实系统交互。然而,离线策略学习的方法受数据集质量影响较大,很难在质量较差的数据集中学习得到较优的策略。因此,一个直接的解决方案是采用离线强化学习或离线模仿学习方法预训练出一个次优策略,随后采用在线强化学习方法进行策略性能的微调。这样一方面可以消除离线策略学习受数据集质量的限制,另一方面可以为在线强化学习提供一个较优的初始策略,跳过早期的低效率、高成本、危险性大的随机探索阶段。因契合真实决策优化场景的现实需求,这种“离线预训练,在线微调”的范式受到了学术界和工业界的广泛关注,并已在机器人控制和自然语言处理领域(chatgpt,gpt4)取得了重大突破,并在未来有望用于自动驾驶决策和工业场景优化中。
2、然而目前的离线到在线强化学习仍面临许多挑战,其中最大的挑战是分布漂移(distribution shift)现象。此现象主要集中在在线微调的初期。在微调初期,由于在线微调会收集很多离线数据集中从未出现过的新数据,对这些新引入的数据进行策略学习会因为数据分布较少的原因而出现较大的估计误差,这种估计误差会影响策略的优化过程从而造成严重的策略性能下降,破坏掉离线预训练得到的较优策略。
3、针对上述由于在线微调初期分布漂移导致智能体策略性能下降的问题,现有的离线到在线强化学习通常采用行为正则化方法或者价值函数正则化方法,将在线微调策略π严格地限制在离线预训练策略或离线数据集的分布内,从而防止在线微调策略出现严重的策略性能下降。其中,基于行为正则化方法的离线到在线强化学习方法通过限制在线微调策略到数据集分布之间的kl(kullback-leibler)散度实现策略约束,之后通过求解优化问题的kkt(karush-kuhn-tucker)条件,可以实现隐式的策略约束。但是一味地限制在线微调策略和数据集分布间的偏差将导致像离线策略学习一样,微调策略的性能将同样受数据集质量限制严重,难以得到最优的策略。基于价值函数正则化的离线到在线强化学习方法通常采用保守q学习的方式预训练策略。由于保守q学习预训练得到的价值函数会将较低的价值估值分配给数据分布以外动作,同时因为价值函数的高低反映着策略性能的好坏,所以数据分布以外的动作会由于较低的价值估值而被判断为性能较差的动作。因此,在在线微调阶段,数据分布以外的动作不再参与到策略优化的过程中,减少了由分布漂移带来的误差累积。然而,为了较好地压低所有数据分布外动作的价值函数,通常需要采用价值函数聚合等方式训练多个保守价值函数,这无疑会消耗极大的计算资源,应用成本极高。因此,亟需提供一种新的离线到在线强化学习方法。
技术实现思路
1、为了解决上述问题,本发明提供一种基于迭代式策略约束的智能体强化学习方法和装置,通过迭代式地更新策略约束,既可以避免离线到在线强化学习早期在线微调阶段的策略性能下降,还可以在训练后期减弱策略约束,以获得最优策略。
2、第一方面,本发明提供一种基于迭代式策略约束的智能体强化学习方法,所述方法包括:
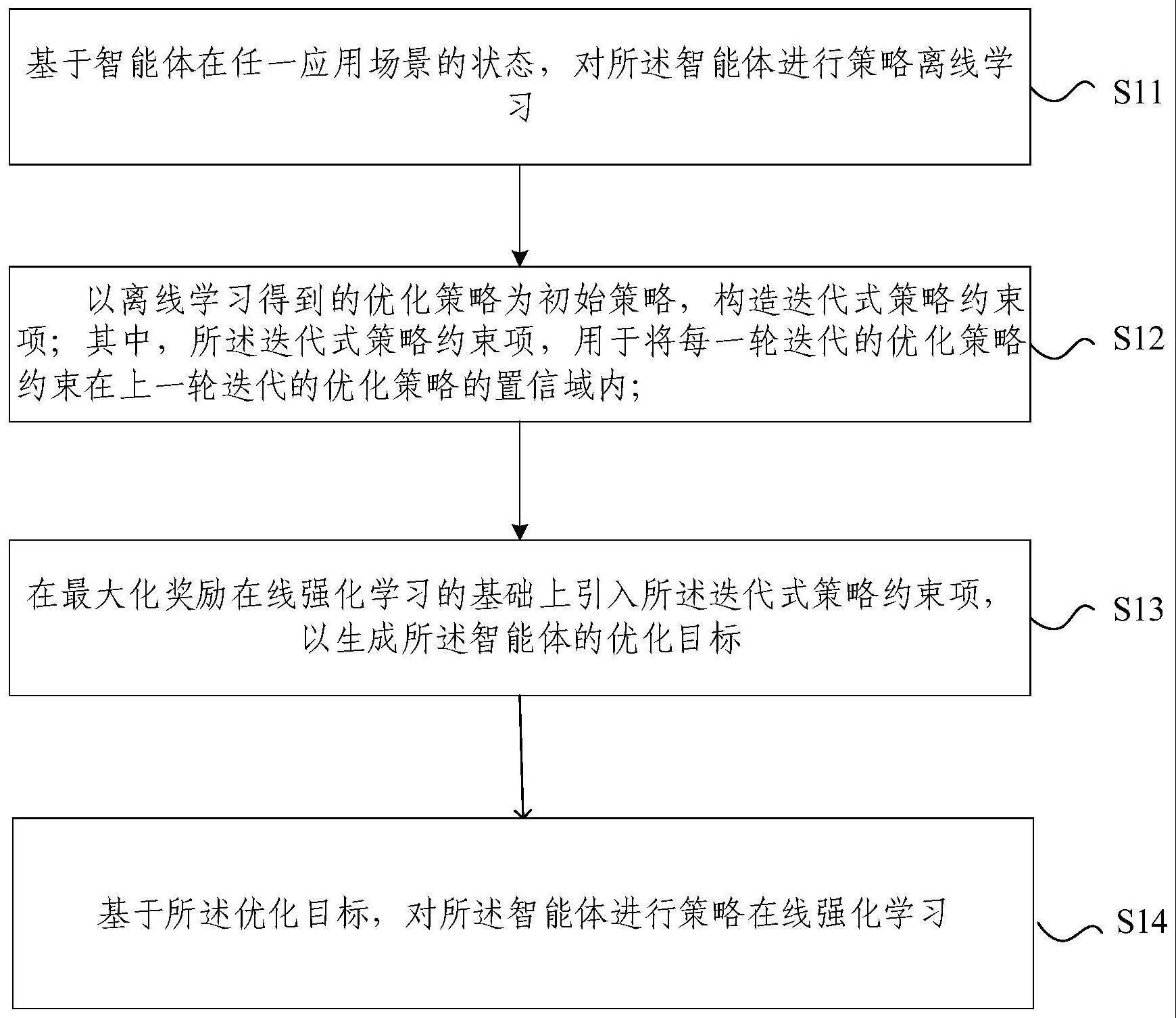
3、基于智能体在任一应用场景的状态,对所述智能体进行策略离线学习;
4、以离线学习得到的优化策略为初始策略,构造迭代式策略约束项;其中,所述迭代式策略约束项,用于将每一轮迭代的优化策略约束在上一轮迭代的优化策略的置信域内;
5、在最大化奖励在线强化学习的基础上引入所述迭代式策略约束项,以生成所述智能体的优化目标;
6、基于所述优化目标,对所述智能体进行策略在线强化学习。
7、根据本发明提供的一种基于迭代式策略约束的智能体强化学习方法,所述智能体的应用场景包括但不限于:机器人控制任务场景、自动驾驶任务场景以及工业发电控制任务场景。
8、根据本发明提供的一种基于迭代式策略约束的智能体强化学习方法,所述基于智能体在任一应用场景的状态,对所述智能体进行策略离线学习,包括:
9、基于智能体在任一应用场景的状态,对所述智能体进行策略离线强化学习;
10、或者
11、基于智能体在任一应用场景的状态,对所述智能体进行策略离线模仿学习。
12、根据本发明提供的一种基于迭代式策略约束的智能体强化学习方法,所述迭代式策略约束项为
13、其中,k≥0且k为整数,(a|s)表示已知状态s的情况下决策动作a,π(a|s)为(a|s)条件下智能体第k+1轮迭代的候选策略,πk(a|s)为(a|s)条件下智能体第k轮迭代的优化策略,π0(a|s)为(a|s)条件下离线学习得到的优化策略,α为保守因子,f(·)为f-散度所对应的正则化函数。
14、根据本发明提供的一种基于迭代式策略约束的智能体强化学习方法,所述优化目标如下所示:
15、
16、其中,γ为折旧因子,st和at分别为t时刻智能体在所述任一应用场景下的状态和动作,rt为t时刻智能体的策略奖励,(at|st)表示已知状态st的情况下决策动作at,π(at|st)为(at|st)条件下智能体第k+1轮迭代的候选策略,πk(at|st)为(at|st)条件下智能体第k轮迭代的优化策略,πk+1为智能体第k+1轮迭代的优化策略。
17、根据本发明提供的一种基于迭代式策略约束的智能体强化学习方法,所述基于所述优化目标,对所述智能体进行策略在线强化学习,包括:
18、确定所述优化目标在动作家-评论家框架下的等价式;
19、利用所述等价式,对所述智能体进行策略在线强化学习。
20、根据本发明提供的一种基于迭代式策略约束的智能体强化学习方法,所述等价式如下所示:
21、动作家:
22、评论家:
23、
24、其中,st+1和at+1分别为t+1时刻智能体在所述任一应用场景下的状态和动作,rt为当前时刻智能体的策略奖励,为状态集,p(·|st,at)为给定(st,at)时的状态转移矩阵,(at+1|st+1)表示已知状态st+1的情况下决策动作at+1,π(·|st)为动作集,πk(·|st+1)为(at+1|st+1)条件下智能体第k轮迭代的策略的置信域包含的动作的集合,q(st+1,at+1)为智能体在状态st+1的条件下以at+1为策略对应的价值函数,为智能体第k轮迭代在状态st+1的条件下以at+1为策略对应的价值函数,πk(at+1|st+1)为(at+1|st+1)条件下智能体第k轮迭代的候选策略,πk-1(at+1|st+1)为(at+1|st+1)条件下智能体第k轮迭代的优化策略。
25、第二方面,本发明提供一种基于迭代式策略约束的智能体强化学习装置,所述装置包括:
26、离线学习模块,用于基于智能体在任一应用场景的状态,对所述智能体进行策略离线学习;
27、迭代式策略约束项构造模块,用于以离线学习得到的优化策略为初始策略,构造迭代式策略约束项;其中,所述迭代式策略约束项,用于将每一轮迭代的优化策略约束在上一轮迭代的优化策略的置信域内;
28、优化目标生成模块,用于在最大化奖励在线强化学习的基础上引入所述迭代式策略约束项,以生成所述智能体的优化目标;
29、在线强化学习模块,用于基于所述优化目标,对所述智能体进行策略在线强化学习。
30、第三方面,本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如第一方面所述基于迭代式策略约束的智能体强化学习方法。
31、第四方面,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如第一方面所述基于迭代式策略约束的智能体强化学习方法。
32、本发明提供的基于迭代式策略约束的智能体强化学习方法和装置,包括:基于智能体在任一应用场景的状态,对智能体进行策略离线学习;以离线学习得到的优化策略为初始策略,构造迭代式策略约束项;在最大化奖励在线强化学习的基础上引入迭代式策略约束项,以生成智能体的优化目标;基于优化目标,对智能体进行策略在线强化学习。本发明通过迭代式地更新策略约束,既可以避免离线到在线强化学习早期在线微调阶段的策略性能下降,还可以在训练后期减弱策略约束,以获得最优策略。
- 还没有人留言评论。精彩留言会获得点赞!