本发明属于情感识别,具体涉及基于通道扩展与融合的循环胶囊网络多模态情感识别方法。
背景技术:
1、近些年伴随计算机硬件资源的提升,人工智能领域得到了飞速的发展。时至今日,人工智能已经融入到了生活的方方面面。例如人工智能中的多模态情感识别,通过结合多种模态信息可以有效识别被采集者的情感状态,在医疗诊断、智能驾驶、人机交互以及舆论监督等场景均发挥了重要的作用。然而,多模态情感识别虽然在各种工业应用中表现出色,但目前仍然有两个难点待解决。首先是如何有效提取各模态特征序列的高层语义信息,为后续的融合阶段提供更加强大、包含更多深层次语义信息的高级表示。其次是如何学习不同模态特征序列之间的潜在关系,有效地融合不同模态特征序列,得到一个更具代表性的多模态融合表示。
技术实现思路
1、本发明的目的是提供基于通道扩展与融合的循环胶囊网络多模态情感识别方法,通过通道扩展和融合的方式对各模态特征序列进行处理,以有效提取各模态特征序列的高层语义信息。
2、本发明所采用的技术方案是,基于通道扩展与融合的循环胶囊网络多模态情感识别方法,具体按照以下步骤实施:
3、步骤1、从多模态情感视频数据库中提取多个视频样本,从每个视频样本中分别提取音频模态特征序列视觉模态特征序列和文本模态特征序列
4、t为各模态特征序列的序列长度,da、dl和dv分别为音频模态、文本模态和视觉模态的特征向量维度;
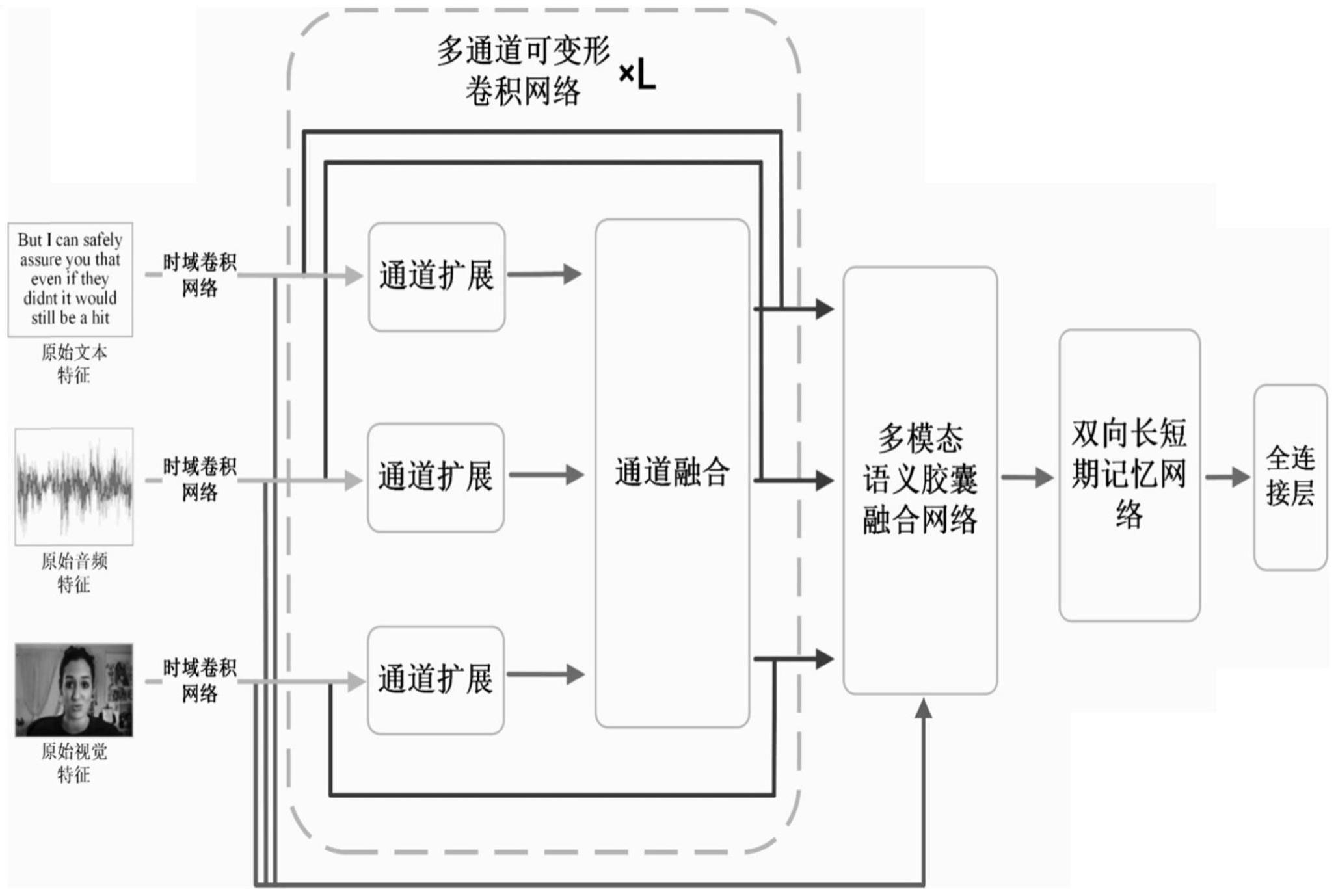
5、步骤2、分别建立三个时域卷积网络,将每个视频样本的音频模态特征序列za、视觉模态特征序列zv和文本模态特征序列zl分别送入对应时域卷积网络中,学习各模态特征序列的时域关系,各模态特征序列的特征向量维度被统一为d,最后,得到包含上下文信息的音频模态特征序列xa、视觉模态特征序列xv和文本模态特征序列xl;
6、步骤3、构建l个多通道可变形卷积网络并按顺序堆叠在一起,每个多通道可变形卷积网络由三个“通道扩展”模块和一个“通道融合”模块组成;然后,将包含上下文信息的音频模态特征序列xa、视觉模态特征序列xv和文本模态特征序列xl同时输入到堆叠的多通道可变形卷积网络中进行处理,得到包含高层语义信息的音频模态特征序列视觉模态特征序列和文本模态特征序列
7、步骤4、构建多模态语义胶囊融合网络,获得全局信息胶囊v;
8、步骤5、将全局语义胶囊v输入到双向长短期记忆网络中进行压缩,得到压缩的多模态融合
9、步骤6、将压缩的多模态融合送入密集层中进行多模态情感分类。
10、本发明的特点还在于,
11、步骤3中,每个“通道扩展”模块是由卷积核大小为3×3和5×5的卷积神经网络以及池化大小为3×3的最大池化层组成;“通道融合”模块是由五个卷积核大小为3×3的可变形卷积网络组成;
12、每个多通道可变形卷积网络的具体处理过程为:
13、步骤a、将包含上下文信息的音频模态特征序列视觉模态特征序列和文本模态特征序列分别输入到“通道扩展”模块中;在“通道扩展”模块中,使用大小为3×3和5×5的卷积核以及大小为3×3的最大池化操作分别处理各模态特征序列,提取各模态特征序列不同粒度的语义信息,具体计算过程如式(1)-(3)所示:
14、
15、
16、
17、其中,i∈{a、v、l},2conv表示为二维卷积神经网络,和分别是使用为3×3卷积、5×5卷积和3×3最大池化的输出结果,是使用3×3卷积操作后的特征通道数,是使用5×5卷积操作后的特征通道数,是使用3×3最大池化操作后的特征通道数;
18、步骤b、将相同模态的和分别与xi拼接在一起,以得到“通道扩展”模块的最终输出即分别为和具体计算过程如式(4)所示:
19、
20、其中,c是拼接后的特征通道维度,计算公式为
21、步骤c、将三个“通道扩展”模块的输出和输入到“通道融合”模块,在“通道融合”模块中,首先按照语义信息的粒度对和进行划分和拼接,并送入对应的可变形卷积网络中进行处理,具体计算过程如式(5)-(9)所示:
22、
23、
24、
25、
26、
27、其中,x3×3、x5×5、xpool和xavl分别为各模态相同粒度的特征序列融合之后的结果,deforconv表示为可变形卷积网络,和分别为“通道融合”模块输出的音频模态、文本模态和视觉模态的特征序列;
28、步骤d、引入残差网络以保证多通道可变形卷积网络不会随着网络层数增加而出现性能下降现象,具体计算过程如式(10)所示:
29、
30、其中,表示矩阵加法操作,和分别为多通道可变形卷积网络输出的各模态特征序列;
31、步骤e、以和作为输入,重复l次步骤a-步骤d,得到堆叠多通道可变形卷积网络的最终输出和
32、步骤4中,具体为:
33、步骤a、将音频模态特征序列视觉模态特征序列文本模态特征序列音频模态特征序列xa、视觉模态特征序列xv和文本模态特征序列xl按照维度t拼接在一起,得到输出特征序列然后从维度t对特征序列x进行划分,得到t个特征序列其中i∈{1,2,...,};
34、步骤b、使用一维卷积神经网络分别处理特征序列得到t个局部语义信息胶囊其中r为一维卷积后的特征维度;
35、步骤c、分别给每个局部信息胶囊一个初始的权重值,将这些局部信息胶囊和对应的权重值加权求和得到一个新的特征序列将其称为全局信息胶囊;然后计算全局信息胶囊p和每个局部信息胶囊ui之间的皮尔逊相关系数,并使用得到的皮尔逊相关系数去更新每个局部信息胶囊对应的权重值;其次,使用所有更新后的权重值重新与对应的局部信息胶囊加权求和,得到一个新的全局信息胶囊最后,计算新的全局信息胶囊m和每个局部信息胶囊ui的皮尔逊相关系数,并继续更新对应的权重值,重复n次,得到最终输出的全局信息胶囊其中j∈{1,2,...,},具体计算过程如式(11)-(15)所示:
36、
37、
38、
39、
40、
41、其中,表示权重值,为中间胶囊,cij表示胶囊系数,用于和中间胶囊加权求和生成全局信息胶囊jj,bij为1,“←”表示对数值进行更新,是和vj的皮尔逊相关系数,是的均值,是vj的均值,是的均值,是vj2的均值,是的均值。
42、步骤6中,密集层由一个relu激活的全连接层、两个线性全连接层和一个dropout层组成。
43、本发明的有益效果是:
44、1)本发明创新性地提出用于学习各模态特征序列的高层语义信息的网络,即多通道可变形卷积网络。该网络通过“通道扩展”和“通道融合”可以充分提取各模态特征序列不同粒度的语义信息,以及通过可变形卷积网络结合其他模态的语义信息,学习到各模态特征序列中隐式的语义信息。并且堆叠多个多通道可变形卷积网络重复处理各模态特征序列,可以充分的提取各模态特征序列的高层语义信息,使学习到各模态高级表示更具代表性,包含更多抽象的语义信息;
45、2)与以往使用胶囊网络的情感识别工作相比,本发明对标准的胶囊网络进行了改进,对每个单词上的所有模态特征序列进行组合以生成局部信息胶囊,并且将胶囊从向量形式变为矩阵形式,增强了胶囊网络的表示能力。此外,使用皮尔逊相关系数计算局部信息胶囊与全局信息胶囊之间的关系,使全局信息胶囊的生成过程更加严谨合理;
46、3)通过大量的实验分析和验证,本发明提出的基于通道扩展与融合的循环胶囊网络合理有效,能够达大大提高多模态情感识别的准确率。