基于检索增强的金融问答文本生成方法、设备及存储介质
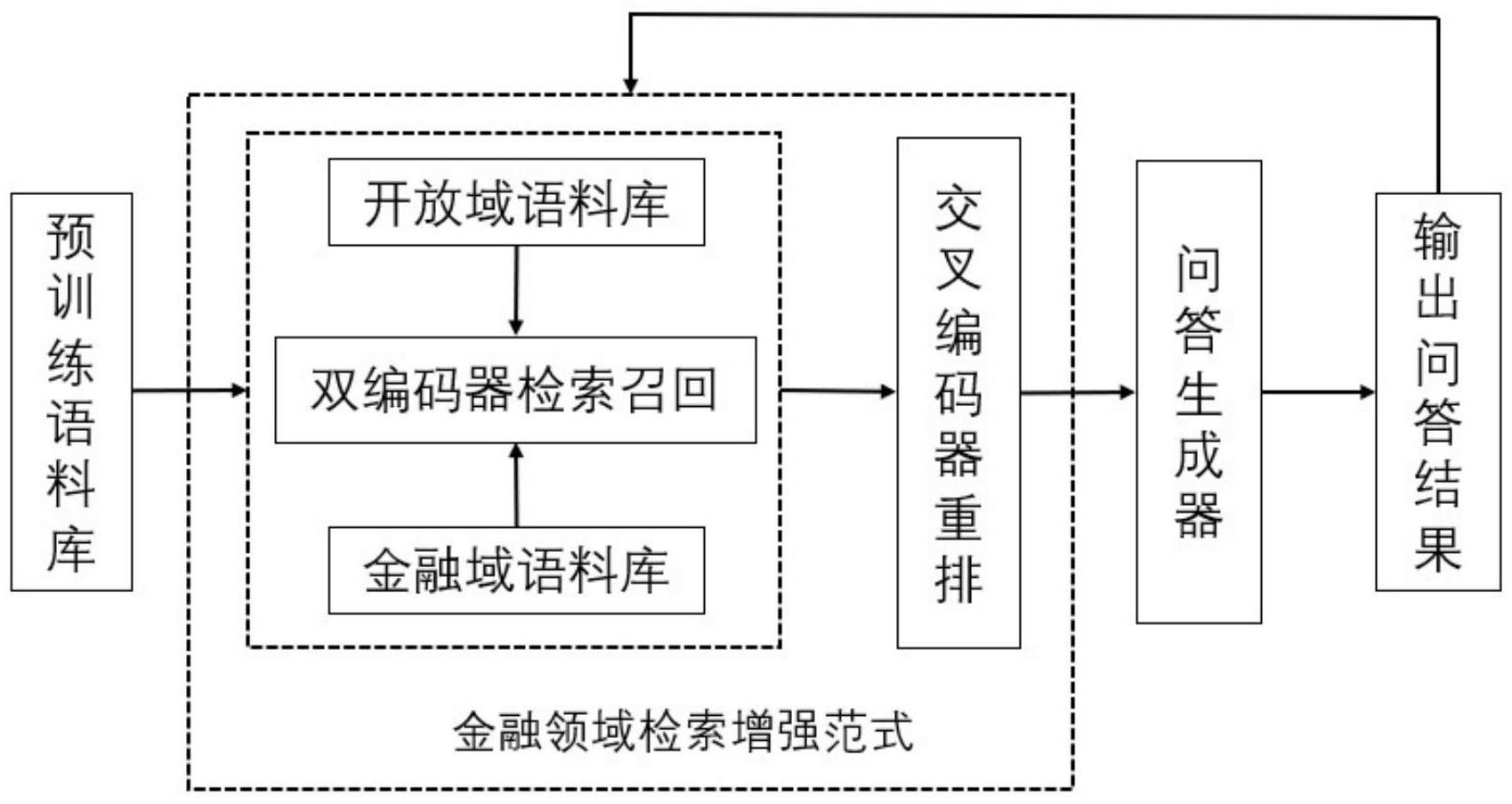
本发明涉及问答,尤其是涉及一种基于检索增强的金融问答系统文本生成方法。
背景技术:
1、问答系统由搜索引擎发展而来,能够为用户返回更加精确的和更加符合用户需求的答案。对话系统可以分为两类,即基于检索的模型和基于生成的模型。基于检索的模型在接收响应请求时直接从对话语料库(即检索池)中复制现有的响应。检索到的回答通常是信息丰富和合乎语法的,因为它们是从真实世界的对话中收集的,也可能是由人类编辑的。因此,当给定的对话历史与检索池中的对话历史有本质差异时,这样的系统表现很差。另一方面,基于生成的模型从零开始生成一个新的话语。这些基于生成的模型在处理不可见的对话上下文时具有更好的泛化能力。
2、目前,应用于金融领域的问答系统较多为基于知识图谱的知识检索模型。中国专利申请cn112100344a给出了一种基于知识图谱的金融领域知识问答方法。中国专利申请cn110083692b给出了一种金融知识问答的文本交互匹配方法及装置,中国专利申请cn111522906b提出了一种基于问答模式的金融事件主体抽取方法。
3、基于知识图谱的问答系统通过对用户的问句进行语义解析,识别问句的中心实体,理解用户的意图,将问句的实体链接到知识图谱中的实体,最后构造查询语句从知识图谱中查询到答案返回给用户。但是在对话切换话题的场景中,仅通过中心实体来构造外部知识图谱的方式,无法有效对问题进行扩充,特别是在垂直领域中,以中心实体构造的外部知识容易导致语言模型的“幻觉”。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在的缺陷而提供一种检索增强范式,将检索模型和生成模型相结合,以满足问答系统对结果的准确性、多样性及合理性的要求。
2、本发明的目的可以通过以下技术方案来实现:
3、作为本发明的第一方面,提供一种基于检索增强的金融问答文本生成方法,方法步骤包括:
4、使用检索器,采用双编码器模型分别对开放域以及金融域的问题和检索文档进行编码,并召回问题相关文档;
5、使用检索结果集成器,采用交叉编码器模型对开放域与金融域召回的问题相关文档进行重排并精选检索结果,对精选检索结果与原始上下文采用加权集成策略进行拼接;
6、使用生成器,以加权集成生成的文档为输入,根据问题和检索到的辅助知识生成问答结果;
7、其中,所述问题检索器采用基于模糊度监督优化方法调整检索文档的概率。
8、进一步的,所述检索器采用密集通道检索的优化训练方法,基于双编码器模型分别实现对开放域和金融域检索源的检索,具体步骤如下:
9、基于双编码器及其训练策略,对两个编码器e q(·)和e p(·)采用预先训练的大模型初始化的两个独立神经网络,并将第一个标记处的表示作为编码的输出;
10、基于双编码器及其训练策略,对两个编码器eq(·)和ep(·)采用预先训练的大模型初始化的两个独立神经网络,并将第一个标记处的表示作为编码的输出;
11、密集通道双编码器使用编码器ep(·)来获取通道的嵌入;
12、建立通道嵌入索引进行检索,在查询时使用另一个编码器eq(·)将输入问题嵌入到一个d维实值向量中,检索出嵌入位置与问题最近的k个段落文档;
13、计算问题q和候选段落p之间的相似性,利用相似度抽取语料库中与问题相似度较高的文档进行召回。
14、进一步的,所述检索器的训练目标是学习问题和文章的密集表示,使训练数据中问题积极的文章对比问题消极的文章对具有更高的相似度:
15、双编码器给定一个问题qi及其文章正样本和m个负样本通过训练将损失函数最小化:
16、
17、其中,m训练采用的负样本数量,sim(q,p)表示问题q和候选段落p之间的相似性。
18、进一步的,所述开放域的检索为根据问题从检索库与外部搜索引擎检索源获得相关文档。
19、进一步的,所述金融域的检索为从金融领域知识库和搜索引擎库检索源对排名靠前的热门检索词进行检索获得相关文档。
20、进一步的,所述采用交叉编码器模型重排开放域与金融域召回的问题相关文档,具体过程如下:
21、将问答正样本与由问题检索器得到的2*k个检索文档输入bert编码器;
22、将编码结果计算相关性分数;
23、依据相关性分数对文档进行重拍并输出前k个精选检索结果。
24、进一步的,所述对精选检索结果与原始上下文采用加权集成策略进行拼接,具体步骤包括:
25、对预训练语料库中原始上下文x进行编码;
26、计算基于文档d和输入上下文x之间的相似性得分:
27、根据评分函数,得到由k个与输入上下文x最相关的文档组成的集合d′,将d′中的每个文档d提前到输入上下文x,并将这个连接分别传递给生成器,然后集成来自所有2k次传递的输出概率,所述评分函数如下:
28、p(y|x,d′)=p(y|d°x)·λ(d,x)
29、其中,°表示两个序列的连接与权重,λ(d,x)是基于文档d和输入上下文x之间的相似性得分;
30、所述集成方法需要运行k次,在每个检索到的文档d和输入上下文x之间执行交叉注意力。
31、进一步的,所述基于模糊度监督的检索器优化方法用于调整检索文档的概率,以匹配生成器的输出序列模糊的概率,找到使结果评分较高的文档:
32、在给定输入上下文x的情况下,使用检索器从语料库d中检索召回k个相似度得分最高的检索文档
33、计算每个检索文档d∈d的检索似然:
34、
35、其中,γ是控制最大值的超参数,通过对检索到的文档d’进行边缘化来近似检索可能性;
36、计算在给定输入上下文x和文档d的情况下,生成器输出y的概率真值;
37、依据生成器输出y的概率真值计算每个检索文档评分:
38、
39、通过最小化检索似然与检索文档评分两个分布之间的kl发散,训练更新检索器模型参数:
40、
41、其中,β是一组输入上下文;
42、在每个训练步骤中重新计算文档嵌入并使用新的嵌入重建有效的搜索索引;
43、使用新的文档嵌入和索引进行检索,并重复训练过程。
44、作为本发明的第二方面,提供一种金融问答文本生成设备,包括:
45、一个或多个处理器;
46、存储器,用于存储一个或多个程序;
47、当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如上任一项所述的金融问答文本生成方法。
48、作为本发明的第三方面,提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如上任一项所述的金融问答文本生成方法的步骤。
49、与现有技术相比,本发明具有以下有益效果:
50、1)本发明在金融领域问答系统中通过检索增强范式将检索模型与生成模型相结合,通过检索增强扩展对话语料库或文档,纳入更多开放域及金融领域的语料库来扩大检索池,提升问答结果的合理性。
51、2)基于检索增强的金融领域问答系统的相关知识不需要隐式地存在模型参数中,而可以通过即插即用方式显示引入知识,具有更大的扩展性。
52、3)基于检索增强的金融领域问答系统文本生成将通过检索得到的文档作为参考,能一定程度减轻文本生成的难度,提升结果的准确性。
- 还没有人留言评论。精彩留言会获得点赞!