对大数据存储系统中的数据文件进行处理的方法及系统与流程
本发明实施例涉及大数据处理,特别是涉及一种对大数据存储系统中的数据文件进行处理的方法及系统。
背景技术:
1、目前,随着数据文件呈现海量增长趋势,利用大数据存储系统对海量的数据文件进行存储是非常重要的数据存储手段。
2、申请号为:cn202010201287.x、名称为:一种数据处理方法、装置以及计算机可读存储介质的发明专利公开了一种数据处理方法、装置以及计算机可读存储介质,该方法涉及资源调度相关技术,该方法包括:作业管理进程向资源管理节点获取目标作业的计算资源,将目标作业的计算资源缓存在资源池中;根据目标作业的计算资源确定资源池中的总计算资源;总计算资源包括映射计算资源和归约计算资源;根据总计算资源中的资源未占用的映射计算资源,依次执行目标作业包含的映射类型子任务;根据总计算资源中的资源未占用的归约计算资源,依次执行目标作业包含的归约类型子任务;当检测到目标作业包含的映射类型子任务和归约类型子任务均执行完成时,将资源池中的总计算资源归还给资源管理节点。
3、然而,很多数据文件的内容非常重要,或者涉及用户隐私。数据文件通常被整体地存储在单个存储设备或存储节点中,这种存储方式的问题是如果特定存储设备或存储节点被恶意攻击者所攻击,那么数据文件的泄露会给大数据存储系统或数据文件的用户造成非常重大的损失。
4、因此,针对特定存储设备或存储节点被恶意攻击者所攻击,数据文件会泄露的技术问题,有必要设计一种对大数据存储系统中的数据文件进行处理的方法及系统以解决上述问题。
技术实现思路
1、本发明提供一种对大数据存储系统中的数据文件进行处理的方法及系统根据,解决了特定存储设备或存储节点被恶意攻击者所攻击,数据文件会泄露的技术问题,极大地提高了大数据存储系统中数据文件的安全性。
2、本发明实施例提供一种对大数据存储系统中的数据文件进行处理的方法,包括:
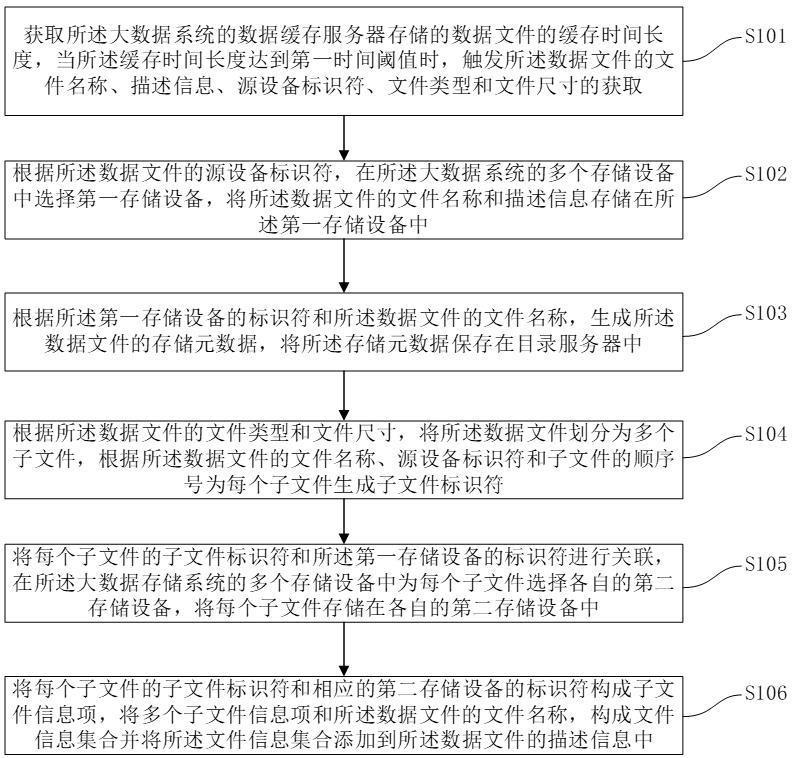
3、获取所述大数据系统的数据缓存服务器存储的数据文件的缓存时间长度,当所述缓存时间长度达到第一时间阈值时,触发所述数据文件的文件名称、描述信息、源设备标识符、文件类型和文件尺寸的获取;
4、根据所述数据文件的源设备标识符,在所述大数据系统的多个存储设备中选择第一存储设备,将所述数据文件的文件名称和描述信息存储在所述第一存储设备中;
5、根据所述第一存储设备的标识符和所述数据文件的文件名称,生成所述数据文件的存储元数据,将所述存储元数据保存在目录服务器中;
6、根据所述数据文件的文件类型和文件尺寸,将所述数据文件划分为多个子文件,根据所述数据文件的文件名称、源设备标识符和子文件的顺序号为每个子文件生成子文件标识符;
7、将每个子文件的子文件标识符和所述第一存储设备的标识符进行关联,在所述大数据存储系统的多个存储设备中为每个子文件选择各自的第二存储设备,将每个子文件存储在各自的第二存储设备中;
8、将每个子文件的子文件标识符和相应的第二存储设备的标识符构成子文件信息项,将多个子文件信息项和所述数据文件的文件名称,构成文件信息集合并将所述文件信息集合添加到所述数据文件的描述信息中。
9、优选地,所述根据数据文件的文件类型和文件尺寸,将数据文件划分为多个子文件,包括:
10、当所述数据文件的文件类型为视频文件时,当所述文件尺寸大于或等于第一尺寸阈值时,将所述数据文件划分为第一数量的多个子文件,当所述文件尺寸小于第一尺寸阈值时,将数据文件划分为第二数量的多个子文件,所述第一数量大于所述第二数量;
11、根据所述多个子文件的视频内容的时间顺序,为每个子文件确定顺序号。
12、优选地,所述根据数据文件的文件类型和文件尺寸,将数据文件划分为多个子文件,包括:
13、当数据文件的文件类型为非视频文件时,获取所述数据文件的分段尺寸,根据所述文件尺寸和分段尺寸确定子文件的第三数量,将所述数据文件划分为第三数量的多个子文件;
14、根据所述多个子文件的内容顺序或文件顺序,为每个子文件确定顺序号。
15、优选地,根据所述文件尺寸和分段尺寸确定子文件的第三数量,将所述数据文件划分为第三数量的多个子文件,具体通过以下公式进行计算:
16、,
17、其中,为第三数量,为文件尺寸,为分段尺寸,为向上取整。
18、优选地,当所述大数据存储系统接收到来自源设备的所述数据文件后,将所述数据文件存储在数据缓存服务器中,并记录数据文件的起始存储时间。
19、优选地,实时检测所述数据缓存服务器中每个数据文件的缓存时间,所述缓存时间为当前时间与所述数据文件的起始存储时间之间的时间长度。
20、优选地,所述数据文件的描述信息为所述数据文件的摘要信息;或者,所述数据文件的描述信息包括所述数据文件的多个描述特征,其中每个描述特征用于表征所述数据文件的不同特点。
21、优选地,所述源设备标识符为将所述数据文件发送到所述大数据存储系统的用户设备的标识符。
22、优选地,所述根据所述数据文件的源设备标识符,在所述大数据系统的多个存储设备中选择第一存储设备,包括:
23、根据预先选定的散列函数计算所述数据文件的源设备标识符的散列值;
24、根据所述数据文件的源设备标识符的散列值,在所述大数据存储系统的多个存储设备中选择第一存储设备。
25、本发明实施例还提供一种对大数据存储系统中的数据文件进行处理的系统,包括:
26、数据文件获取模块,其用于获取所述大数据系统的数据缓存服务器存储的数据文件的缓存时间长度,当所述缓存时间长度达到第一时间阈值时,触发所述数据文件的文件名称、描述信息、源设备标识符、文件类型和文件尺寸的获取;
27、第一存储设备选择模块,其用于根据所述数据文件的源设备标识符,在所述大数据系统的多个存储设备中选择第一存储设备,将所述数据文件的文件名称和描述信息存储在所述第一存储设备中;
28、存储元数据生成模块,其用于根据所述第一存储设备的标识符和所述数据文件的文件名称,生成所述数据文件的存储元数据,将所述存储元数据保存在目录服务器中;
29、子文件划分模块,其用于根据所述数据文件的文件类型和文件尺寸,将所述数据文件划分为多个子文件,根据所述数据文件的文件名称、源设备标识符和子文件的顺序号为每个子文件生成子文件标识符;
30、标识符关联模块,其用于将每个子文件的子文件标识符和所述第一存储设备的标识符进行关联,在所述大数据存储系统的多个存储设备中为每个子文件选择各自的第二存储设备,将每个子文件存储在各自的第二存储设备中;
31、子文件信息项模块,其用于将每个子文件的子文件标识符和相应的第二存储设备的标识符构成子文件信息项,将多个子文件信息项和所述数据文件的文件名称,构成文件信息集合并将所述文件信息集合添加到所述数据文件的描述信息中。
32、与现有技术相比,本发明实施例的技术方案具有以下有益效果:
33、本发明实施例的对大数据存储系统中的数据文件进行处理的方法及系统根据,包括:获取所述大数据系统的数据缓存服务器存储的数据文件的缓存时间长度,当所述缓存时间长度达到第一时间阈值时,触发所述数据文件的文件名称、描述信息、源设备标识符、文件类型和文件尺寸的获取;根据所述数据文件的源设备标识符,在所述大数据系统的多个存储设备中选择第一存储设备,将所述数据文件的文件名称和描述信息存储在所述第一存储设备中;根据所述第一存储设备的标识符和所述数据文件的文件名称,生成所述数据文件的存储元数据,将所述存储元数据保存在目录服务器中;根据所述数据文件的文件类型和文件尺寸,将所述数据文件划分为多个子文件,根据所述数据文件的文件名称、源设备标识符和子文件的顺序号为每个子文件生成子文件标识符;将每个子文件的子文件标识符和所述第一存储设备的标识符进行关联,在所述大数据存储系统的多个存储设备中为每个子文件选择各自的第二存储设备,将每个子文件存储在各自的第二存储设备中;将每个子文件的子文件标识符和相应的第二存储设备的标识符构成子文件信息项,将多个子文件信息项和所述数据文件的文件名称,构成文件信息集合并将所述文件信息集合添加到所述数据文件的描述信息中,解决了特定存储设备或存储节点被恶意攻击者所攻击,数据文件会泄露的技术问题,极大地提高了大数据存储系统中数据文件的安全性;
34、进一步地,当所述数据文件的文件类型为视频文件时,当所述文件尺寸大于或等于第一尺寸阈值时,将所述数据文件划分为第一数量的多个子文件,当所述文件尺寸小于第一尺寸阈值时,将数据文件划分为第二数量的多个子文件,所述第一数量大于所述第二数量;根据所述多个子文件的视频内容的时间顺序,为每个子文件确定顺序号,从而将视频文件划分为合理数量的多个子文件并确定顺序号;
35、进一步地,当数据文件的文件类型为非视频文件时,获取所述数据文件的分段尺寸,根据所述文件尺寸和分段尺寸确定子文件的第三数量,将所述数据文件划分为第三数量的多个子文件;根据所述多个子文件的内容顺序或文件顺序,为每个子文件确定顺序号,从而将非视频文件划分为合理数量的多个子文件并确定顺序号。
- 还没有人留言评论。精彩留言会获得点赞!