基于提示对比学习的持续学习下小样本关系抽取方法
本技术涉及数据处理,特别是涉及一种基于提示对比学习的持续学习下小样本关系抽取方法。
背景技术:
1、关系抽取(re)在知识抽取和管理中起着至关重要的作用,它可以用于自然语言处理中的一系列任务,如问答、文本理解等。给定一个带有注释实体对e1和e2的句子x,re的任务旨在通过将其分类到预定义的关系rk集合中来识别实体对之间的关系。传统的re模型需要一个预定义的固定关系集,它只能将句子中实体对之间的关系划分到固定关系集中的一个类别中。然而,由于现实世界是开放的,新数据的出现导致关系的数量不断增加。针对这种情况,提出了持续关系抽取范式。
2、在现有的研究中,大多数cre模型都假设后续任务有足够的可用于训练的标记数据。然而,在现实世界中,大多数关系都没有足够的标记数据,特别是对于新出现的关系来说。因此,考虑到获取足够多的标记数据代价高昂,秦等人提出了持续小样本关系抽取,该方法要求模型从很少的训练例中学习新的关系,同时不忘记旧的关系。目前的cfre模型都面临两个挑战:对已有知识的灾难性遗忘问题和新出现关系的训练样本不足问题,使得在实体关系抽取时准确率低。
技术实现思路
1、基于此,有必要针对上述技术问题,提供一种能够提高实体关系抽取准确率的基于提示对比学习的持续学习下小样本关系抽取方法。
2、一种基于提示对比学习的持续学习下小样本关系抽取方法,所述方法包括:
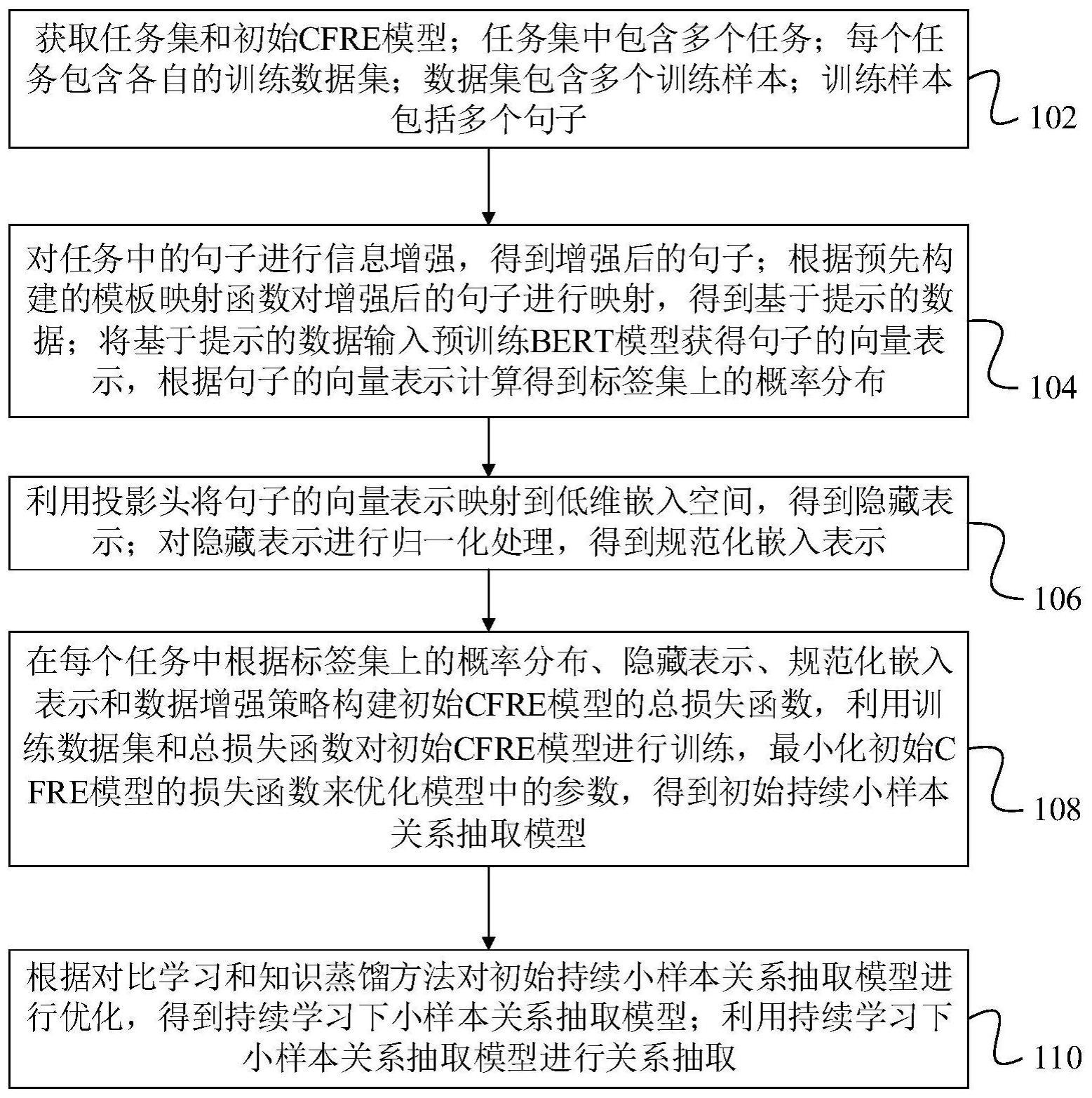
3、获取任务集和初始cfre模型;任务集中包含多个任务;每个任务包含各自的训练数据集;数据集包含多个训练样本;训练样本包括多个句子;
4、对任务中的句子进行信息增强,得到增强后的句子;根据预先构建的模板映射函数对增强后的句子进行映射,得到基于提示的数据;
5、将基于提示的数据输入预训练bert模型获得句子的向量表示,根据句子的向量表示计算得到标签集上的概率分布;
6、利用投影头将句子的向量表示映射到低维嵌入空间,得到隐藏表示;对隐藏表示进行归一化处理,得到规范化嵌入表示;
7、在每个任务中根据标签集上的概率分布、隐藏表示、规范化嵌入表示和数据增强策略构建初始cfre模型的总损失函数,利用训练数据集和总损失函数对初始cfre模型进行训练,最小化初始cfre模型的损失函数来优化模型中的参数,得到初始持续小样本关系抽取模型;
8、根据对比学习和知识蒸馏方法对初始持续小样本关系抽取模型进行优化,得到持续学习下小样本关系抽取模型;
9、利用持续学习下小样本关系抽取模型进行关系抽取。
10、在其中一个实施例中,对任务中的句子进行信息增强,得到增强后的句子,包括:
11、对任务中的句子进行信息增强,得到增强后的句子为
12、xaug={w1,v,[e11],e1,[e12],...,[e21],e2,[e22],...,wx}
13、其中,wx表示句子中的单词,[e11]、[e12]、[e21]和[e22]均表示特殊标记,e1和e2表示句中的头实体和尾实体。
14、在其中一个实施例中,根据预先构建的模板映射函数对增强后的句子进行映射,得到基于提示的数据,包括:
15、根据预先构建的模板映射函数对增强后的句子进行映射,得到基于提示的数据为
16、xprompt=t(xaug)=i think e1 is[mask]of e2[sep]xaug
17、其中,t(·)表示模板映射函数,[mask]表示任务位置,[sep]表示句子分隔符。
18、在其中一个实施例中,初始cfre模型的总损失函数包括交叉熵损失函数、句子特征混合损失函数和对比损失函数;在每个任务中根据标签集上的概率分布、隐藏表示、规范化嵌入表示和数据增强策略构建初始cfre模型的总损失函数,包括:
19、根据标签集上的概率分布构建交叉熵损失函数;
20、根据数据增强策略对隐藏表示和隐藏表示对应的类标签进行线性插值计算,得到插值结果;利用插值结果构建句子特征混合损失函数;
21、根据规范化嵌入表示构建对比损失函数;
22、利用交叉熵损失函数、句子特征混合损失函数和对比损失函数构建初始cfre模型的总损失函数为
23、lall=α1·lce+α2·lsm+α3·lcl
24、其中,lce表示交叉熵损失函数,lsm表示句子特征混合损失函数,lcl表示对比损失函数,α1、α2、α3均表示调优参数。
25、在其中一个实施例中,根据标签集上的概率分布构建交叉熵损失函数,包括:
26、根据标签集上的概率分布构建交叉熵损失函数为
27、
28、其中,θ表示初始cfre模型,表示训练数据集,k表示任务序号,p(y=yi∣zi,yi)表示标签集上的概率分布,y表示目标标签词,yi表示样本i在训练数据集里的真实标签,zi表示规范化嵌入表示,i表示样本序号。
29、在其中一个实施例中,利用插值结果构建句子特征混合损失函数,包括:
30、利用插值结果构建句子特征混合损失函数为
31、
32、其中,vi表示经过bert得到的不同词的表示。表示隐藏表示,表示经过基于提示的编码器获得的混合句子特征,表示混合句子特征对于的混合标签,表示正确的词表示。
33、在其中一个实施例中,根据规范化嵌入表示构建对比损失函数,包括:
34、根据规范化嵌入表示构建对比损失函数为
35、
36、其中,n表示训练数据集的样本总数,p(i)表示与训练样本xi关系相同的样本集合,|p(i)|表示p(i)的基数,p表示是与训练样本xi具有关系相同的样本,si表示记忆内存中部分样本的集合,zi表示规范化嵌入表示,zp表示与训练样本xi具有关系相同的样本表示,τ表示温度系数。
37、在其中一个实施例中,根据对比学习和知识蒸馏方法对初始持续小样本关系抽取模型进行优化之前,还包括
38、根据规范化嵌入表示初始化所有任务的记忆内存,在记忆内存中利用k-means方法获得训练数据集中每个关系训练样本的聚类嵌入,根据聚类嵌入选择记忆内存的典型样本并保存。
39、在其中一个实施例中,根据对比学习和知识蒸馏方法对初始持续小样本关系抽取模型进行优化,得到持续学习下小样本关系抽取模型,包括:
40、根据知识蒸馏方法保留上一个任务中典型样本和对应关系原型之间的相似性,和典型样本与其他关系原型之间的不相似性,对每个样本和上一个任务中所有关系原型之间的相似度和不相似度之间的一致性进行计算,利用计算结果和预先设置的对比学习损失函数对初始持续小样本关系抽取模型进行优化,得到持续小样本关系抽取模型。
41、在其中一个实施例中,对每个样本和上一个任务中所有关系原型之间的相似度和不相似度之间的一致性进行计算,包括:
42、对每个样本和上一个任务中所有关系原型之间的相似度和不相似度之间的一致性进行计算,得到计算结果为
43、
44、其中,是训练新任务前样本与其他关系原型之间相似度的度量分布,表示前k个任务中出现的所有关系的集合,表示训练新任务前原型i和关系原型j相似度的计算,是训练新任务后样本与其他关系原型之间相似度的度量分布,表示训练新任务后原型i和关系原型j相似度的计算,由动态嵌入计算出的样本zi和关系原型pj之间的余弦相似度,τ表示温度系数。
45、上述基于提示对比学习的持续学习下小样本关系抽取方法,本技术通过对任务中的实体进行标记处理来获取增强的句子表示,然后设计模板并通过模板映射函数获得基于提示的数据,将预训练语言模型bert作为编码器获得更好的关系表示,可以更好地利用有限数量的训练样本中的知识,然后使用预训练bert模型的投影头将句子的向量表示映射到低维嵌入空间,得到隐藏表示;对隐藏表示进行归一化处理,得到规范化嵌入表示,根据标签集上的概率分布、隐藏表示、规范化嵌入表示和数据增强策略构建初始cfre模型的总损失函数,利用训练数据集和总损失函数对初始cfre模型进行训练,最小化初始cfre模型的损失函数来优化模型中的参数,得到初始持续小样本关系抽取模型,通过混合数据特征的增强策略来提高模型的鲁棒性,并防止少样本任务过度拟合,进而提高了模型关系抽取的准确性。其次,为了减轻之前知识的遗忘,除了在记忆中重放样本外,还通过对比学习和知识蒸馏方法对初始持续小样本关系抽取模型进行优化,保持了实例嵌入的稳定性,并通过实例级蒸馏损失来保留学习关系的知识,减少了关系抽取误差。
- 还没有人留言评论。精彩留言会获得点赞!