一种基于集成剪枝的软件缺陷数据集分类方法
本发明涉及集成学习、剪枝、遗传算法和软件缺陷预测具体地,涉及把进化聚类应用的集成剪枝方法中。
背景技术:
1、由于科技的快速发展和互联网的普及,导致海量、高速、多样化的数据不断产生、积累和传播的现象。大数据的快速积累和处理使得数据逐渐成为企业和组织中重要的资产,能够为企业和组织提供更多的商业价值。通过对大数据的分析和挖掘,可以发现隐藏在数据中的规律和趋势,从而做出更加明智的决策。
2、单一的学习算法或模型在面对复杂的数据时可能存在一定的局限性,如过拟合、欠拟合、高偏差或高方差等。这可能导致预测性能不理想或无法满足实际需求。集成学习通过将多个学习算法或模型组合起来,集成学习可以通过共同决策、投票、加权等方式获得更为准确和稳健的预测结果。集成学习可以充分利用不同模型之间的互补性,从而提高模型的泛化能力、降低模型的过拟合风险,同时也能够在处理大规模数据和复杂任务时提供更好的性能。
3、集成剪枝是一种将集成学习和模型剪枝技术相结合的方法,旨在通过去除集成模型中的冗余和不必要的部分,从而提高模型的预测性能和模型的解释性。
4、在实际应用中,随着数据规模和模型复杂度的不断增加,模型的解释性和可解释性成为越来越重要的需求。复杂的集成模型可能在预测性能上表现出色,但其对于模型内部的决策过程和特征重要性的解释性较差,这对于一些对模型解释性有要求的场景,如金融、医疗、法律等领域,可能存在限制。因此,需要一种方法来在保持预测性能的同时,提高模型的解释性和可解释性,降低大数据处理对能源的过分消耗。
技术实现思路
1、在实际应用中,模型的泛化性能和稳健性是至关重要的。复杂的集成模型可能存在过拟合、泛化能力下降和对输入数据的高度敏感性等问题。通过剪枝集成模型,可以去除冗余和不必要的模型部分,从而减小模型的复杂度,提高模型的泛化性能和稳健性,从而节约计算机对电力的消耗和达到保护计算机存储器件的目的。
2、为了实现上述目的,本发明的技术方案为:
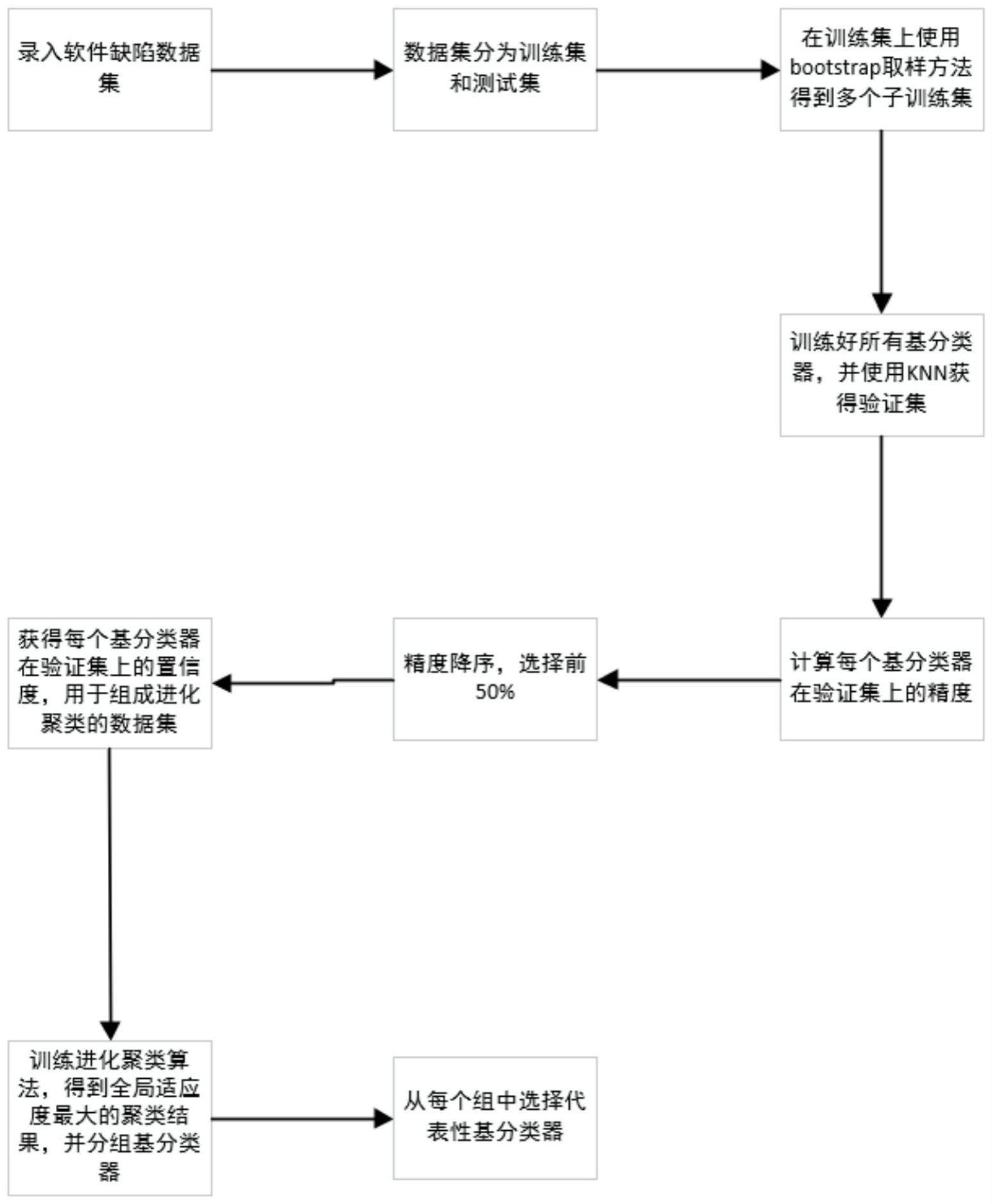
3、一种基于集成剪枝的软件缺陷数据集分类方法,其特征在于:包括以下步骤:
4、(1)加载软件缺陷数据集信息(2)使用bootstrap方法得到不同的训练集,将所有的数据集用于训练不同的基分类器(3)对于验证集的生成,使用knn算法获得在训练集上与测试集相似的数据集作为验证集,并得到每个分类器的性能(4)进化聚类算法的数据集构成,使用每个基分类器对验证集的置信度构成数据集(5)使用进化聚类方法得到全局最优的聚类结果,将所有的基分类器进行分组(6)根据精度最大原则,从每个分组中选择基分类器。减少集成学习在软件缺陷数据集上的运行时间和内存的需要,提高对未知软件缺陷数据的适应能力。
5、进一步,所述步骤(1)加载输入的软件缺陷数据集,首先判断该数据集是否是分类问题数据集,然后对该数据集的实例信息,特征数信息,和类别信息进行统计。最后根据one-hot编码对字符类型的类别转换为数字类型。
6、根据权利要求1所述的一种基于集成剪枝的软件缺陷数据集分类方法,其特征在于,所述步骤(2)根据基分类器数量,使用bootstrap取样获得不同子训练集用于训练不同的基分类器,并保证基分类器之间的多样性。
7、进一步,所述步骤(3)验证集的生成和获得基分类器性能的步骤如下:
8、步骤3.1:设置knn算法的超参数,用以得到合适数量的验证集实例。
9、步骤3.2:使用测试集作为knn算法的训练集,并将训练好的knn算法用于测试原始训练集,得到训练集中存在重复实例,去除重复,该数据集即为基分类器的验证集
10、步骤3.3:得到所有的基分类器的验证集后,每个基分类器用于预测验证集,计算其精度,并将精度降序排序,选择前50%的基分类器用于分组。
11、进一步,所述步骤(4)进化聚类数据集构成步骤如下:
12、步骤4.1:获得所有基分类器在验证集上的置信度分数,在验证集上,假设有n个样本,且标签个数为m,对于一个基学习器w在验证集上的分数结构其中表示基学习器w为第i个样本属于第j个标签的概率。此时每个分数构成为一个二维数组,然后通过转换,变成一个大小相同的一维数组。
13、步骤4.2:转化为一维数据后,将所有的基分类器的置信度拼接为一个二维数组,此时的二维数据即为进化聚类算法的数据集。
14、进一步,所述步骤(5)使用进化聚类方法得到全局最优聚类结果步骤如下:
15、步骤5.1:设定进化聚类算法超参数,如人口数为200,迭代次数为200,变异概率为0.5%。
16、步骤5.2:种群的初始化,使用k-means方法对聚类数据集进行训练和预测,k-means得到的聚类结果作为一个个体的染色体。然后在此基础上,使用随机函数,随机选择位置,随机改变其簇类结果。此时得到的种群中,个体染色体存在较大差别,保证了初始种群的多样性。
17、步骤5.3:对于种群个体适应度计算,这里采用监督分类器计算每个个体的适应度。选择一定数量的训练集来训练每个监督分类器,计算每个监督分类器在测试集上的f1分数,并求平均值,该平均值就会作为该个体的适应度。
18、步骤5.4:计算完成初始种群个体的适应度后,使用竞标赛算子选择父母一代。
19、步骤5.5:在使用单点交叉算子用于父母个体,生成的新个体具有父母的特征,同时在更好适应度的条件下,有可能产生更优秀的后代。
20、步骤5.6:完成单点交叉后,使用交换变异算子,提高进化聚类算法的搜索能力和效果。
21、步骤5.7:完成三个操作算子后,按照设定的迭代次数淘汰选择个体,并从中选择适应度最大的个体。
22、步骤5.8:得到全局适应度最大的个体,按照这个聚类结果,将所用参与进化聚类算法数据集组成的基分类器进行分组。
23、进一步,所述步骤(6)根据精度最大原则从每个组中选择基分类器步骤如下:
24、步骤6.1:首先从第一个组中选择在验证集上精度最大基分类器,加入集成剪枝模型。
25、步骤6.2:对于第二组的基分类器选择使用顺序正向选择方法。把第二组的每个基分类器和集成剪枝模型中的基分类器进行融合,选择集成精度最大基分类器。对所有的分组进行同样的操作。
26、步骤6.3:如果遍历完所有分组后,集成剪枝模型中的基分类器数量仍不满足集成剪枝数量,重新从第一组开始遍历,直到满足剪枝数量要求。
27、本发明的技术效果为:
28、1.通过集成剪枝技术,可以显著减少集成学习模型在软件缺陷数据集上的基分类器数量。这对于移动设备或资源有限的环境中部署模型非常有用,因为可以减少模型的存储需求和推理时的计算开销,由此带来降低计算机数据运行对电力的大量消耗和保护计算机的存储器件。
29、2.提高集成学习模型的泛化性能。剪枝可以消除模型中的过拟合问题,从而提高模型的泛化能力和对未知软件缺陷数据的适应能力。
30、3.降低集成学习模型的计算开销:通过剪枝,可以减少集成学习模型的参数量和计算量,从而降低模型的计算开销,节约能源,使得模型更适用于资源有限的环境。
31、4.本发明能够减少集成学习在软件缺陷数据集上的运行时间和内存的需要,并能够在剪枝的情况下和原来集成方法性能相近甚至可以有所提高。
- 还没有人留言评论。精彩留言会获得点赞!