一种基于图神经网络的论文数据姓名消歧算法
本发明属于实体消歧,具体涉及一种基于图神经网络的论文数据姓名消歧算法。
背景技术:
1、数字图书馆的出现为学者们提供了高质量的学术信息资源,使他们能够方便地访问海量的学术期刊、论文以及学者信息,从而为他们的学术研究提供了便利。随着科学研究的不断深入,研究人员越来越需要高质量的学术资源来支持其研究工作,因此确保数字图书馆中数据的准确性变得尤为重要。然而,由于作者重名现象的普遍存在以及由于文化差异性所导致的记录方式的不一致,使得学术数据库中存在大量的同名学者,这给用户的信息检索带来了极大的困扰,需要用户花费大量时间对检索结果进行筛选,增加了用户检索的难度,妨碍了科研活动的开展。此外,同名学者的存在还可能会导致学者的研究成果被错误地归属给其他同名学者,这可能会影响学者的知名度和声誉,甚至出现混淆和错误的引用。同时,同名学者的论文引用次数还可能会被错误地算入到某个特定学者的引用计数中,从而影响其学术排名和评估,对科学计量学造成影响,因此同名作者消歧便成为文献数据库亟待解决的问题。
2、针对同名作者消歧问题,现有的解决方法主要分为以下几种:
3、1.基于有监督的消歧方法,主要利用人为标注的训练集训练分类模型对同名作者文献进行分类;但是,基于有监督的消歧方法需要在事先标注好的数据集上进行训练,而人工标注训练集的成本过高,不适合大量数据的消歧,因此具有一定的局限性。
4、2.基于无监督的消歧方法,主要使用文献的属性特征来计算相似度,并运用聚类算法进行消歧;基于无监督的方法不需要事先对数据集进行标注,但在计算文献相似性时,很难选择合适的相似性判定阈值;同时,在进行聚类时,由于无法预先确定同名作者的数量,也就无法确定聚类结果的个数即同名作者簇的数量,因此消歧准确率相对较低。
5、3.基于半监督的消歧方法,该方法介于有监督和无监督之间,它可以使用少量标注的数据信息训练分类器来对大量未标注的数据进行分类,从而提高消歧结果的准确率;但是,这种方法往往具有更为复杂的结构,整体性能较为依赖人工标注信息的完整性,对数据质量要求高,且存在人为产生噪声的可能。
6、4.基于图的消歧方法,通常将作者或论文作为网络的节点,然后根据论文与论文之间或者作者与论文之间的关系构建图,最后通过计算节点之间的相似性或者聚类算法进行消歧;通常此方法的消歧效果较好,但现有的基于图的消歧方法通常只考虑了论文之间的合著关系和引用关系等简单关系,而这些简单关系构建的网络不能够有效的捕捉论文数据中丰富的语义和结构信息。
技术实现思路
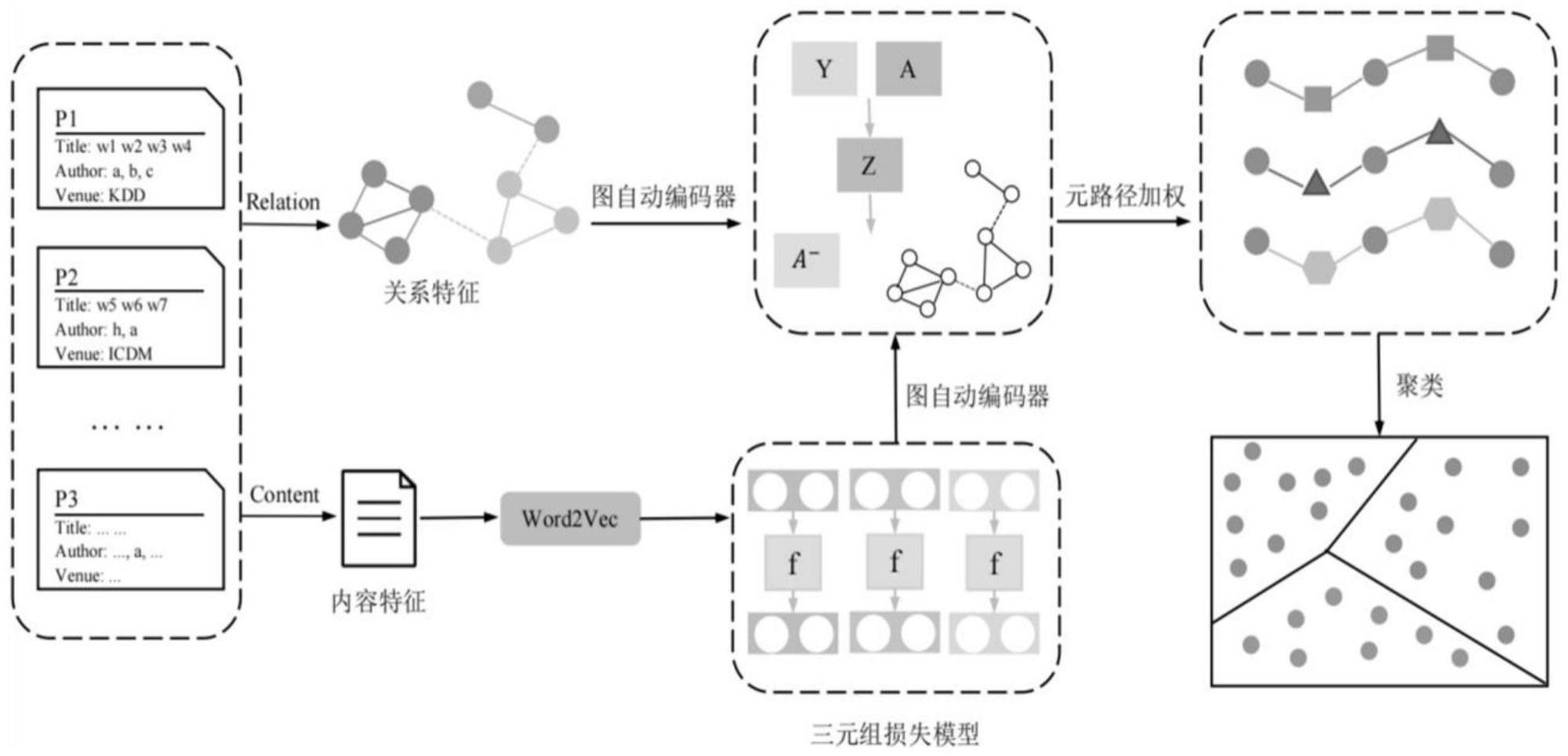
1、鉴于上述,本发明提出了一种基于图神经网络的论文数据姓名消歧算法,该算法将每篇论文作为异质网络的节点,通过论文属性特征之间的强关联性建立边,并使用一个无监督的图自动编码器学习得到每篇论文的表征向量,同时采用一种分层的注意力机制网络来增强论文的向量表示,最后通过层次聚类算法实现同名作者消歧。
2、一种基于图神经网络的论文数据姓名消歧算法,包括如下步骤:
3、(1)利用特征工程提取论文数据集中每篇论文的论文特征作为姓名消歧的元数据,并将每篇论文作为异质网络中的节点;
4、(2)基于拼音声母的转换方法将论文数据集划分为若干个同名作者簇,以解决同一作者姓名有多种不同写法的问题;
5、(3)使用word2vec对论文特征进行词向量嵌入表示并生成每篇论文的特征向量,进而采用三元组损失模型对特征向量进行调整,最后基于特征向量进行初步聚类;
6、(4)根据论文的共同通讯作者构建学术关系网络,并基于强规则对同一关系网络中的同名作者进行二次聚类;
7、(5)利用图自动编码器来学习学术关系网络中节点的分布式表示,从而得到各节点包含论文属性信息和论文间关系信息的表征向量;
8、(6)使用包含节点级和语义级的分层注意力机制网络来学习同一元路径上不同节点之间的权值关系以及不同元路径之间的权值关系,进而通过加权融合以增强论文节点的表征向量;
9、(7)根据增强后得到的论文表征向量通过层次聚类算法进行聚类,从而实现姓名消歧。
10、进一步地,所述步骤(1)中提取的论文特征由论文属性特征和论文关系特征两部分组成,其中论文属性特征包括作者姓名(第一作者)、邮箱、地址机构名称、标题,论文关系特征包括合著者、关键词、出版物。
11、进一步地,所述步骤(2)的具体实现过程如下:
12、step1:将所有论文的作者姓名均视为类,构成类集合a={a1,a2,…,an};
13、step2:将所有作者姓名均统一成小写并去除特殊符号(例如逗号、分号、连接符等);
14、step3:将作者姓名中的拼音全写用唯一的汉字对应(例如zeng对应曾,zheng对应郑);
15、step4:分析作者姓名是拼音全称还是声母简写,并将拼音全写解析为拼音、拼音对应的声母以及拼音对应的汉字;
16、step5:如果集合a中任意两个类a1与a2的作者姓名均为拼音全写且对应的汉字相同,或者类a1与a2的作者姓名中含有声母简写且对应的声母相同,那么将a1和a2合并为类a12,并把类a12添加到集合a中,同时去除a1和a2;
17、step6:反复执行step5,直至集合a中没有类可以再合并为止,结束聚类。
18、进一步地,所述步骤(3)中首先通过word2vec生成每项论文特征的词向量,然后通过tf-idf计算每项论文特征的权值,最后将所有词向量加权求和后得到每篇论文的特征向量,具体计算公式如下:
19、
20、其中:xm表示论文特征,di表示论文i的特征集合,xi表示论文i的特征向量,表示论文特征xm的词向量,fm表示论文特征xm的权值系数。
21、进一步地,所述步骤(3)中采用三元组损失模型对特征向量进行调整即利用大量正负样本对作为训练数据,正样本对为属于同一作者的两篇论文,负样本对为属于不同作者的两篇论文,进而根据以下损失函数ζd对三元组损失模型进行训练,训练完成后取模型中的word2vec重新计算生成每篇论文的特征向量;
22、
23、其中:yij=1表示论文i和论文j属于同一作者即正样本对,yik=0表示论文i和论文k属于不同作者即负样本对,dij表示论文i与论文j特征向量之间的欧式距离,dik表示论文i与论文k特征向量之间的欧式距离,m为一个固定的边界距离常量,[]+为hinge损失函数。
24、进一步地,所述步骤(3)中根据调整后得到的特征向量通过余弦相似度在异质网络中遍历计算任意两个论文节点特征向量之间的相似度,若相似度足够高(即大于阈值),则在这两个节点之间构建一条边。
25、进一步地,由于邮箱地址具有唯一性,在邮箱信息无缺的情况下,如果两位重名作者含有相同的邮箱,则认为这两位作者为同一个人,所述步骤(4)中将与相同通讯作者有合著关系的学者处于同一学术关系网络中。
26、进一步地,所述步骤(4)中的强规则包括:
27、①如果两篇论文的作者姓名相同、地址信息相同且含有相同的合著者,那么可以认为这两篇论文属于同一作者;
28、②如果两篇论文的作者姓名相同、地址信息相同且发表在同一出版物上,那么可以认为这两篇论文属于同一作者;
29、③如果两篇论文的作者姓名相同、地址信息相同且含有相同的关键词,那么可以认为这两篇论文属于同一作者。
30、进一步地,所述步骤(6)中首先通过图注意力网络对同一元路径上的邻居节点进行加权融合,得到节点级的论文表征向量;然后再使用语义级的注意力机制来学习不同元路径的重要性,并融合各个元路径的语义得到最终的论文表征向量;所述元路径即为基于相同论文关系特征连接起来的节点所构成的路径。
31、基于上述技术方案,本发明具有以下有益技术效果:
32、1.本发明利用图神经网络对异质网络中的节点进行表征,可以充分利用节点之间的关联信息,提高消歧的准确率。
33、2.本发明使用无监督的图自动编码器进行论文表征向量的学习,避免了传统消歧方法中需要大量标注数据的问题。
34、3.本发明采用分层的注意力机制网络来学习节点和元路径之间的权值关系,进一步增强了论文的向量表示和消歧的准确率。
- 还没有人留言评论。精彩留言会获得点赞!